Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Applica a:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Questo articolo illustra le procedure consigliate per l'uso del collegamento Managed Instance per replicare i dati tra Azure SQL Managed Instance e le istanze di SQL Server ospitate ovunque. Il collegamento fornisce la replica dei dati quasi in tempo reale tra le repliche collegate.
Eseguire regolarmente i backup del log
Se SQL Server è il database primario iniziale, eseguire il primo backup del log in SQL Server dopo che il seeding iniziale termina, quando il database non si trova più nello stato di Restoring... nell'istanza gestita di Azure SQL. Eseguire quindi regolarmente i backup del log delle transazioni di SQL Server per mantenere in salute le dimensioni del file di log delle transazioni mentre SQL Server è nel ruolo primario.
La funzionalità di collegamento replica i dati usando la tecnologia dei gruppi di disponibilità distribuiti in base ai gruppi di disponibilità Always On. La replica dei dati del gruppo di disponibilità distribuito si basa sulla replica dei record del log delle transazioni. L'istanza primaria SQL Server non può troncare i record del log delle transazioni dal database fino a quando non vengono replicati nel database nella replica secondaria. Se i problemi di connessione di rete causano un rallentamento o un blocco della replica dei record del log delle transazioni, il file di log continua a crescere nell'istanza primaria. L'intensità del carico di lavoro e la velocità di rete determinano la velocità di crescita. Se un'interruzione della connessione di rete è prolungata e il carico di lavoro nell'istanza primaria è elevato, il file di log può occupare tutto lo spazio di archiviazione disponibile.
L'esecuzione di backup regolari del log delle transazioni tronca il log delle transazioni e riduce al minimo il rischio di esaurimento dello spazio nell'istanza primaria SQL Server a causa della crescita dei file di log. Non è necessaria alcuna azione aggiuntiva quando SQL Managed Instance è il database primario perché i backup di log vengono già eseguiti automaticamente. Eseguendo regolarmente i backup dei log nel SQL Server primario, si rende il database più resiliente agli eventi di crescita dei log non pianificati. Prendere in considerazione la pianificazione delle attività di backup giornaliero del log usando un'attività di SQL Server Agent.
È possibile usare uno script Transact-SQL (T-SQL) per eseguire il backup del file di log, ad esempio l'esempio fornito in questa sezione. Sostituire i segnaposto nello script di esempio con il nome del database, il nome e il percorso del file di backup e la descrizione.
Per eseguire il backup del log delle transazioni, usare lo script di esempio Transact-SQL (T-SQL) seguente in SQL Server:
-- Execute on SQL Server
-- Take log backup
BACKUP LOG [<DatabaseName>]
TO DISK = N'<DiskPathandFileName>'
WITH NOFORMAT, NOINIT,
NAME = N'<Description>', SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 1
Usare il comando Transact-SQL (T-SQL) seguente per controllare lo spazio del log usato dal database in SQL Server:
-- Execute on SQL Server
DBCC SQLPERF(LOGSPACE);
L'output della query è simile all'esempio seguente per il database di esempio tpcc:
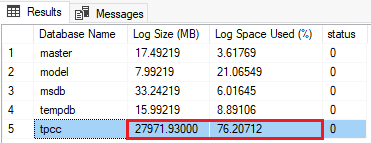
In questo esempio il database ha usato il 76% del log disponibile, con dimensioni del file di log assolute di circa 27 GB (27.971 MB). Le soglie per l'azione variano in base al carico di lavoro. Nell'esempio precedente, le dimensioni del log delle transazioni e la percentuale di utilizzo del log indicano in genere che è necessario eseguire un backup del log delle transazioni per troncare il file di log e liberare spazio oppure eseguire backup del log più frequenti. Potrebbe anche essere un'indicazione che il troncamento del log delle transazioni è bloccato da transazioni aperte. Per altre informazioni sulla risoluzione dei problemi di un log delle transazioni in SQL Server, vedere Risoluzione dei problemi di un log delle transazioni pieno (SQL Server Errore 9002). Per altre informazioni sulla risoluzione dei problemi relativi a un log delle transazioni in Azure SQL Managed Instance, vedere Risoluzione dei problemi con errori del log delle transazioni con Azure SQL Managed Instance.
Nota
Quando si partecipa a un collegamento, SQL Managed Instance esegue backup automatici completi e del log delle transazioni indipendentemente dal fatto che si tratti o meno della replica primaria. I backup differenziali non vengono eseguiti, il che può causare tempi di ripristino più lunghi.
Confrontare la capacità di prestazione tra le repliche
Quando si usa la funzionalità di collegamento, armonizzare la capacità di prestazione sia di SQL Server sia di SQL Managed Instance. Questo abbinamento consente di evitare problemi di prestazioni se la replica secondaria non riesce a sincronizzarsi con la sincronizzazione dalla replica primaria o in seguito al failover. La capacità delle prestazioni include core CPU (o vCore in Azure), memoria e velocità effettiva di I/O.
È possibile monitorare le prestazioni della replica controllando le dimensioni della coda di redo nella replica secondaria. La dimensione della coda di redo indica il numero di record di log in attesa di essere rifatti sulla replica secondaria. Una dimensione costantemente elevata della coda di redo indica che la replica secondaria non riesce a tenere il passo con la replica primaria. È possibile controllare le dimensioni della coda di rollforward nei modi seguenti:
- Il valore
redo_queue_sizedella vista a gestione dinamica sys.dm_hadr_database_replica_states sulla replica primaria. - Il valore
InstanceRedoLagReplicationSecondsin Get-AzSqlInstanceLink nella replica primaria.
Se la dimensione della coda di riapplicazione è costantemente elevata, prendere in considerazione l'aumento delle risorse nella replica secondaria.
Monitorare il ritardo della replica
Il monitoraggio del ritardo di replica consente di determinare la velocità di sincronizzazione della replica secondaria con la replica primaria. Una discrepanza elevata indica che la replica secondaria presenta problemi con la replica primaria, che in genere è causata da una velocità effettiva di rete lenta nel collegamento tra le due istanze, l'allocazione di risorse non corrispondente tra le due repliche o da un carico di lavoro eccessivamente elevato nella replica primaria.
Il monitoraggio del ritardo di replica è particolarmente importante quando si esegue un failover pianificato, che richiede che la replica secondaria sia completamente sincronizzata con la replica primaria prima che il failover possa essere eseguito. Se il ritardo di replica è elevato, il failover potrebbe richiedere più tempo e, in alcuni casi, potrebbe anche non riuscire.
Usare la seguente query T-SQL sia in SQL Server che in SQL Managed Instance per monitorare il ritardo di replica tra le repliche.
-- Execute on SQL Server and SQL Managed Instance
USE master
DECLARE @link_name varchar(max) = '<DAGname>'
SELECT
ag.name [Link name],
ars1.role_desc [Link role],
ars2.connected_state_desc [Link connected state],
ars2.synchronization_health_desc [Link sync health],
drs.secondary_lag_seconds [Link replication latency (seconds)]
FROM
sys.availability_groups ag
JOIN sys.dm_hadr_availability_replica_states ars1
ON ag.group_id = ars1.group_id
JOIN sys.dm_hadr_availability_replica_states ars2
ON ag.group_id = ars2.group_id
JOIN sys.dm_hadr_database_replica_states drs
ON ars2.replica_id = drs.replica_id
WHERE
ag.is_distributed = 1 AND ag.name = @link_name AND ars1.is_local = 1 AND ars2.is_local = 0
GO
Rinnovare il certificato
Potrebbe essere necessario ruotare manualmente il certificato usato per proteggere l'endpoint del mirroring del database in SQL Server. Poiché il servizio gestisce e ruota automaticamente il certificato usato per proteggere l'endpoint del mirroring del database in SQL Managed Instance, non è necessario ruotarlo manualmente.
SQL Server
Il certificato usato per proteggere l'endpoint del mirroring del database in SQL Server può scadere. Se il certificato scade, può causare una riduzione delle prestazioni dei collegamenti. Per evitare questo problema, ruotare il certificato prima della scadenza.
Usare il comando Transact-SQL (T-SQL) seguente per controllare la data di scadenza del certificato corrente:
-- Run on SQL Server
USE MASTER
GO
SELECT * FROM sys.certificates WHERE pvt_key_encryption_type = 'MK'
Se il certificato sta per scadere o è già scaduto, creare un nuovo certificato e quindi modificare l'endpoint esistente per sostituire il certificato corrente.
Dopo aver configurato l'endpoint per l'uso del nuovo certificato, è possibile eliminare il certificato scaduto.
Istanza Gestita SQL
Il certificato dell'endpoint del mirroring del database in SQL Managed Instance viene ruotato periodicamente. Non è necessario monitorare la data di scadenza per il certificato dell'endpoint del mirroring del database in SQL Managed Instance, purché sia possibile convalidare la catena dei certificati in SQL Server correttamente.
Convalidare la catena di certificati in SQL Server
Nota
Convalidare periodicamente la catena di certificati per i collegamenti esistenti o risolvere i problemi relativi a un collegamento danneggiato. Se si sta configurando un nuovo collegamento o sono stati completati di recente i passaggi nelle sezioni Gettare la chiave pubblica del certificato da SQL Managed Instance e importarla in SQL Server e Importare le chiavi dell'autorità di certificazione radice Azure attendibili per SQL Server, ignorare questa sezione.
I problemi relativi alla catena di certificati possono compromettere il collegamento. Per evitare questo problema, convalidare regularmente la catena di certificati in SQL Server.
Gli scenari seguenti possono causare problemi con la catena di certificati in SQL Server:
- Rotazione pianificata dei certificati in SQL Managed Instance.
- Modifiche accidentali o accidentali ai certificati in SQL Server, ad esempio l'eliminazione o la modifica del certificato usato per proteggere l'endpoint del mirroring del database.
Prima di tutto, determinare il certificate_id del certificato dell'endpoint MI importato sostituendo il valore di <ManagedInstanceFQDN> e poi eseguire la seguente query su SQL Server:
-- Run on SQL Server
USE master
SELECT name, subject, certificate_id, start_date, expiry_date
FROM sys.certificates
WHERE issuer_name LIKE '%Microsoft Corporation%' AND name = '<ManagedInstanceFQDN>'
GO
Convalidare quindi il certificato sostituendo il valore di <certificate_id> dal risultato della query precedente e quindi eseguendo la query seguente in SQL Server:
-- Run on SQL Server
USE master
EXEC sp_validate_certificate_ca_chain <certificate_id>
GO
Una risposta di Commands completed successfully. Completion time: ... indica che il certificato dell'endpoint MI è stato convalidato correttamente.
Importante
La stored procedure sp_validate_certificate_ca_chain si basa sui servizi del sistema operativo host per eseguire la convalida del certificato, che potrebbe comportare un controllo di revoca dei certificati online. Se il sistema operativo host non è configurato per accedere a Internet, l'esecuzione ha esito negativo anche se la catena di certificati è valida.
Se si verifica un errore, la mitigazione più affidabile consiste nel ripristinare la catena di certificati eliminando prima tutti i certificati creati nelle sezioni Ottenere la chiave pubblica del certificato da SQL Managed Instance e importarla in SQL Server e Importare le chiavi dell'autorità di certificazione radice affidabili di Azure in SQL Server, e quindi reimportarli.
Aggiungere flag di traccia di avvio
In SQL Server sono presenti due flag di traccia (-T1800 e -T9567) che, se aggiunti come parametri di avvio, possono ottimizzare le prestazioni della replica dei dati tramite il collegamento. Per altre informazioni, vedere Abilitare i flag di traccia di avvio.
Usare il commit sincrono con cautela
La modalità commit predefinita per il collegamento è asincrona. Anche se è possibile modificare la modalità commit in sincrona, non è consigliabile e non è necessario proteggersi da potenziali perdite di dati.
Durante un failover collegato pianificato, la replica viene temporaneamente impostata in modalità di commit sincrono fino al completamento del failover. Dopo il failover, la modalità commit torna all'asincrona, anche se è impostata in modo esplicito sulla modalità commit sincrono prima del failover.
L'uso della modalità commit sincrono per il collegamento può influire sulle prestazioni della replica primaria, soprattutto se è presente una latenza di rete elevata tra le repliche. In modalità commit sincrono, le transazioni nella replica primaria devono attendere la conferma della protezione avanzata dei record del log delle transazioni nella replica secondaria prima di poter eseguire il commit della transazione nel database primario. Questo tempo di attesa aumenta con una latenza di rete più elevata, con conseguente aumento dei tempi di risposta delle transazioni e riduzione della velocità effettiva nella replica primaria.
Contenuto correlato
Per usare il collegamento:
- Prepara l'ambiente per il collegamento Managed Instance
- Configurare il collegamento tra SQL Server e Istanza gestita di SQL con SSMS
- Configurare il collegamento tra SQL Server e Istanza gestita di SQL con script
- Eseguire il failover con il collegamento
- Eseguire la migrazione con il collegamento
- Risolvere i problemi relativi al collegamento
Per altre informazioni sul collegamento:
- Panoramica del collegamento Managed Instance
- Ripristino di emergenza con collegamento di Istanza gestita
- Procedure consigliate per la gestione del collegamento
Per altri scenari di replica e migrazione, prendere in considerazione:
- Replicazione transazionale con SQL Managed Instance
- Servizio di riproduzione dei log (LRS)