Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Azure Data Lake Analytics drogs tillbaka den 29 februari 2024. Läs mer i det här meddelandet.
För dataanalys kan din organisation använda Azure Synapse Analytics eller Microsoft Fabric.
Den här artikeln visar hur du använder Azure Data Lake Tools i Visual Studio för att felsöka problem med återkommande jobb. Läs mer om pipeline- och återkommande jobb från Azure Data Lake- och Azure HDInsight-bloggen.
Återkommande jobb delar vanligtvis samma frågelogik och liknande indata. Anta till exempel att du har ett återkommande jobb som körs varje måndag morgon kl. 08.00 för att räkna förra veckans aktiva användare varje vecka. Skripten för dessa jobb delar en skriptmall som innehåller frågelogik. Indata för dessa jobb är användningsdata för förra veckan. Att dela samma frågelogik och liknande indata innebär vanligtvis att prestandan för dessa jobb är liknande och stabil. Om ett av dina återkommande jobb plötsligt presterar onormalt, misslyckas eller saktar ned mycket kanske du vill:
- Se statistikrapporterna för tidigare körningar av det återkommande jobbet för att se vad som hände.
- Jämför det onormala jobbet med ett normalt jobb för att ta reda på vad som har ändrats.
Relaterad jobbvy i Azure Data Lake Tools för Visual Studio hjälper dig att påskynda felsökningsprocessen i båda fallen.
Steg 1: Hitta återkommande jobb och öppna Relaterad jobbvy
Om du vill använda relaterad jobbvy för att felsöka ett återkommande jobbproblem måste du först hitta det återkommande jobbet i Visual Studio och sedan öppna Relaterad jobbvy.
Fall 1: Du har URL:en för det återkommande jobbet
Via Verktyg>Data Lake> kan du klistra in jobb-URL:n för att öppna jobbvyn i Visual Studio. Välj Visa relaterade jobb för att öppna vyn Relaterat jobb.

Fall 2: Du har pipelinen för den återkommande uppgiften, men inte URL:en
I Visual Studio kan du öppna Pipeline Browser via Server Explorer > ditt Azure Data Lake Analytics-konto >Pipelines. (Om du inte hittar den här noden i Server Explorer laddar du ned det senaste plugin-programmet.)

I Pipeline Browser visas alla pipelines för Data Lake Analytics-kontot till vänster. Du kan utöka pipelines för att hitta alla återkommande arbetsuppgifter och därefter välja den som har problem. Relaterad jobbvy öppnas till höger.

Steg 2: Analysera en statistikrapport
En sammanfattning och en statistikrapport visas överst i den relaterade jobbvyn. Där kan du hitta den potentiella grundorsaken till problemet.
- I rapporten visar X-axeln tiden för jobbinskickning. Använd den för att hitta det onormala jobbet.
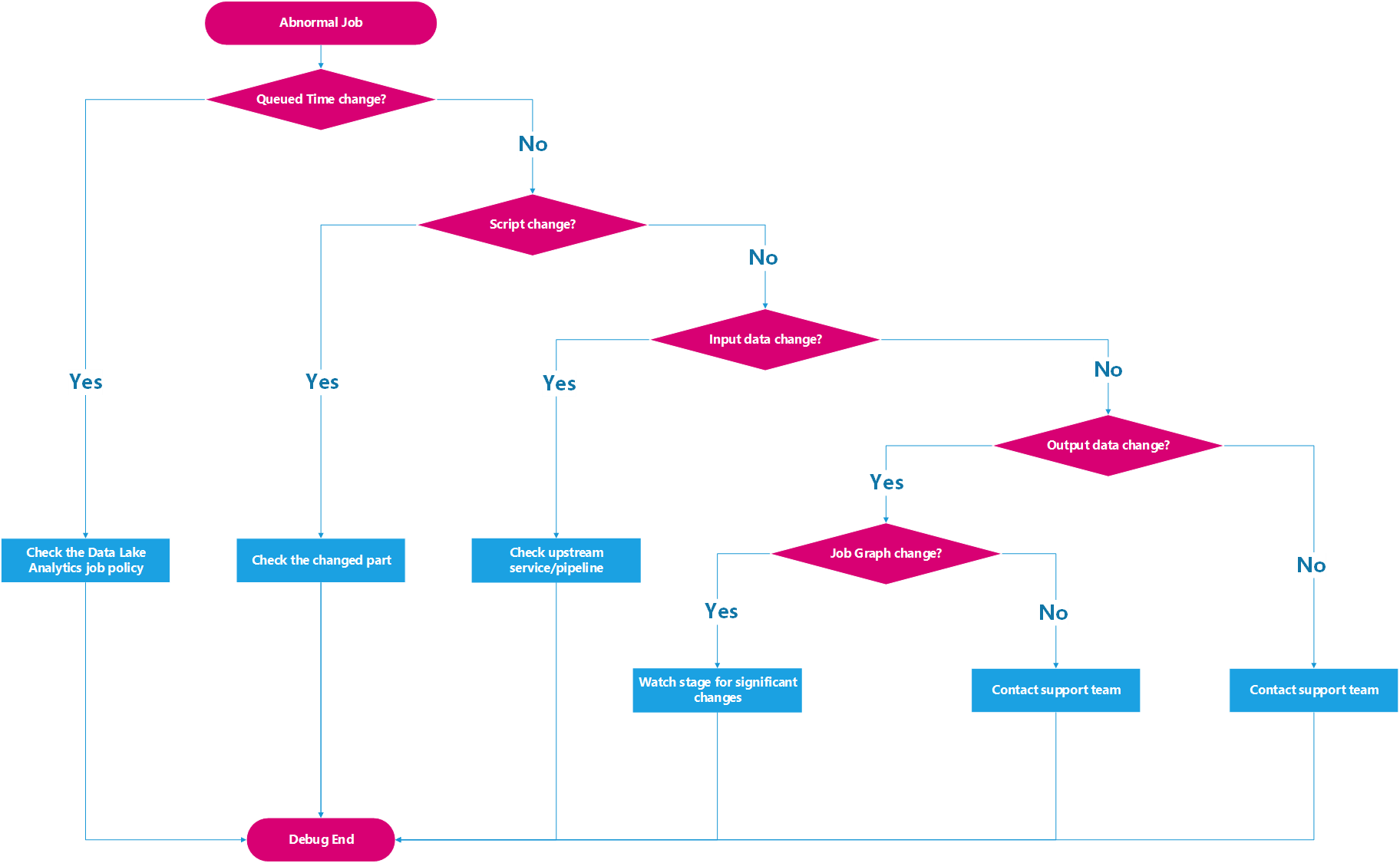
- Använd processen i följande diagram för att kontrollera statistik och få insikter om problemet och möjliga lösningar.

Steg 3: Jämför det onormala jobbet med ett normalt jobb
Du hittar alla skickade återkommande jobb via jobblistan längst ned i Den relaterade jobbvyn. Om du vill hitta fler insikter och potentiella lösningar högerklickar du på det onormala jobbet. Använd jobb-Diff-vyn för att jämföra det onormala jobbet med ett tidigare normalt jobb.

Var uppmärksam på skillnaderna mellan dessa två jobb. Dessa skillnader orsakar förmodligen prestandaproblemen. Om du vill kontrollera ytterligare använder du stegen i följande diagram: