Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här sidan beskriver hur du läser data som delas med dig med öppna delningsprotokollet OpenSharing med ägartoken. Den innehåller instruktioner för att läsa delade data med hjälp av följande verktyg:
I den här databricks-till-öppna-delningsmodellen använder du en fil med autentiseringsuppgifter som delas med en medlem i ditt team av dataleverantören för att få säker läsåtkomst till delade data. Åtkomsten bevaras så länge autentiseringsuppgiften är giltig och providern fortsätter att dela data. Leverantörer hanterar förfallodatum och rotation av autentiseringsuppgifter. Uppdateringar av data är tillgängliga nästan i realtid. Du kan läsa och göra kopior av delade data, men du kan inte ändra källdata.
Note
Om data har delats med dig med Databricks-till-Databricks OpenSharing behöver du ingen autentiseringsfil för att komma åt data och den här sidan gäller inte för dig. I stället, se Läs data som delas via Databricks-till-Databricks OpenSharing (för mottagare).
Note
I Databricks-to-Open-delning bestäms lagrings bucketen och autentiseringsuppgifterna (omfång, förfallodatum, läsning och läsning/skrivning) av providern. Om du monterar en öppen delning i en SEG-arbetsyta (Secure Egress Gateway) läggs leverantörens bucket automatiskt till i tillåtelselistan för utgående åtkomst – kontrollera leverantören innan du monterar den.
I följande avsnitt beskrivs hur du använder Azure Databricks, Apache Spark, pandas, Power BI och Iceberg-klienter för att komma åt och läsa delade data med hjälp av autentiseringsfilen. En fullständig lista över OpenSharing-anslutningsappar och information om hur du använder dem finns i dokumentationen om OpenSharing open-source. Om du får problem med att komma åt delade data kontaktar du dataleverantören.
Innan du börjar
En medlem i ditt team måste ladda ned filen med autentiseringsuppgifter som delas av dataleverantören och använda en säker kanal för att dela filen eller filplatsen med dig. Se Hämta åtkomst i delningsmodellen Databricks-to-Open.
Mer information om anslutningsspecifik dokumentation finns på sidan för att ladda ned autentiseringsuppgifter.
Azure Databricks: Läs delade data med Databricks-till-Open Sharing-anslutningar
I det här avsnittet beskrivs hur du importerar en provider och hur du frågar efter delade data i Catalog Explorer eller i en Python-notebook-fil:
Om din Azure Databricks-arbetsyta är aktiverad för Unity Catalog använder du användargränssnittet för importprovidern i Katalogutforskaren. Du kan göra följande utan att behöva lagra eller ange en autentiseringsfil:
- Skapa kataloger från delningar med ett klick på en knapp.
- Använd åtkomstkontroller för Unity Catalog för att bevilja åtkomst till delade tabeller.
- Fråga efter delade data med standardsyntax för Unity Catalog.
- Tillämpa en roterad autentiseringsuppgift på det befintliga providerobjektet utan att återskapa katalogen. Se Rotera autentiseringsuppgifter för öppna mottagare.
Om din Azure Databricks-arbetsyta inte är aktiverad för Unity Catalog använder du Python Notebook-instruktionerna som exempel.
Katalogutforskaren
Behörigheter som krävs: En metaarkivadministratör eller en användare som har både CREATE PROVIDER och USE PROVIDER behörigheter för ditt Metaarkiv i Unity Catalog.
På din Azure Databricks-arbetsyta klickar du på
 Katalog för att öppna Katalogutforskaren.
Katalog för att öppna Katalogutforskaren.Längst upp i fönstret Katalog klickar du på
 väljer OpenSharing.
väljer OpenSharing.Du kan också klicka på Dela > OpenSharing i det övre högra hörnet.
På fliken Delat med mig klickar du på Installera delning.
Ange leverantörens namn.
Namnet får inte innehålla blanksteg.
Ladda upp filen med autentiseringsuppgifter som providern delade med dig.
Många leverantörer har egna OpenSharing-nätverk som du kan ta emot resurser från. Mer information finns i Providerspecifika konfigurationer.
(Valfritt) Ange en kommentar.

Klicka på Importera.
Skapa kataloger från delade data.
På fliken Resurser klickar du på Skapa katalog på resursraden.
Information om hur du använder SQL eller Databricks CLI för att skapa en katalog från en resurs finns i Skapa en katalog från en resurs.
Bevilja åtkomst till katalogerna.
Se Hur gör jag delade data tillgängliga för mitt team? och Hantera behörigheter för scheman, tabeller och volymer i en OpenSharing-katalog.
Läs de delade dataobjekten precis som med alla dataobjekt som är registrerade i Unity Catalog.
Mer information och exempel finns i Åtkomst till data i en delad tabell eller volym.
Python
I det här avsnittet beskrivs hur du använder en Databricks-to-Open-delningsanslutning för att komma åt delade data med hjälp av en notebook-fil i din Azure Databricks arbetsyta. Du eller någon annan medlem i ditt team lagrar autentiseringsfilen i Azure Databricks och använder den sedan för att autentisera till dataleverantörens Azure Databricks-konto och läsa de data som dataleverantören delade med dig.
Note
Dessa instruktioner förutsätter att din Azure Databricks-arbetsyta inte är aktiverad för Unity Catalog. Om du använder Unity Catalog behöver du inte peka på autentiseringsfilen när du läser från resursen. Du kan läsa från delade tabeller precis som från alla tabeller som är registrerade i Unity Catalog. Databricks rekommenderar att du använder användargränssnittet för importprovidern i Katalogutforskaren i stället för anvisningarna här.
Lagra först autentiseringsfilen som en Azure Databricks-arbetsytefil så att användare i ditt team kan komma åt delade data.
Information om hur du importerar autentiseringsfilen i Azure Databricks-arbetsytan finns i Importera en fil.
Ge andra användare behörighet att komma åt filen genom att klicka på
 Bredvid filen och sedan Dela (behörigheter). Ange de Azure Databricks-identiteter som ska ha åtkomst till filen.
Bredvid filen och sedan Dela (behörigheter). Ange de Azure Databricks-identiteter som ska ha åtkomst till filen.Mer information om filbehörigheter finns i Fil-ACL:er.
Nu när autentiseringsfilen har lagrats använder du en notebook-fil för att visa och läsa delade tabeller.
På din Azure Databricks-arbetsyta klickar du på Ny > anteckningsbok.
Mer information om Azure Databricks notebooks finns i Databricks notebooks.
Om du vill använda Python eller
pandasför att komma åt delade data installerar du delta-sharing Python connector. I notebook-redigeraren klistrar du in följande kommando:%sh pip install delta-sharingKör cellen.
Python-biblioteket
delta-sharinginstalleras i klustret om det inte redan är installerat.Använd Python och visa en lista över tabellerna i delen.
I en ny cell klistrar du in följande kommando. Ersätt arbetsytans sökväg med filsökvägen till din autentiserings- och certifikatfil.
När koden körs läser Python autentiseringsfilen.
import delta_sharing client = delta_sharing.SharingClient(f"/Workspace/path/to/config.share") client.list_all_tables()Kör cellen.
Resultatet är en matris med tabeller, tillsammans med metadata för varje tabell. Följande utdata visar två tabeller:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Om utdata är tomma eller inte innehåller de tabeller du förväntar dig kontaktar du dataprovidern.
Utför en fråga på en delad tabell.
Att använda Scala
I en ny cell klistrar du in följande kommando. När koden körs läss autentiseringsfilen från arbetsytefilen.
Ersätt variablerna på följande sätt:
-
<profile-path>: sökvägen till arbetsytan för autentiseringsfilen. Till exempel/Workspace/Users/user.name@email.com/config.share. -
<share-name>: värdetshare=för tabellen. -
<schema-name>: värdetschema=för tabellen. -
<table-name>: värdetname=för tabellen.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Kör cellen. Varje gång du läser in den delade tabellen ser du nya data från källan.
För att fråga radspårningskolumner i en delad tabell, se Läsa radspårningskolumner i delade tabeller.
-
Använda SQL:
För att fråga data med hjälp av SQL skapar du en lokal tabell på arbetsytan från den delade tabellen och ställer sedan frågor mot den lokala tabellen. Delade data lagras eller cachats inte i den lokala tabellen. Varje gång du frågar den lokala tabellen visas det aktuella tillståndet för delade data.
I en ny cell klistrar du in följande kommando.
Ersätt variablerna på följande sätt:
-
<local-table-name>: namnet på den lokala tabellen. -
<profile-path>: platsen för autentiseringsfilen. -
<share-name>: värdetshare=för tabellen. -
<schema-name>: värdetschema=för tabellen. -
<table-name>: värdetname=för tabellen.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;När du kör kommandot efterfrågas delade data direkt. Som ett test efterfrågas tabellen och de första 10 resultaten returneras.
-
Om utdata är tomma eller inte innehåller de data du förväntar dig kontaktar du dataleverantören.
Isbergsklienter: Läsa delade data
Använd externa Iceberg-klienter, till exempel Snowflake, Trino, Flink och Spark, för att läsa delade datatillgångar med nollkopieringsåtkomst med apache Iceberg REST Catalog API.
Hämta autentiseringsuppgifter för anslutning
Innan du får åtkomst till delade datatillgångar med externa Iceberg-klienter samlar du in följande autentiseringsuppgifter:
- Slutpunkten för Isbergs REST-katalog
- En giltig bärartoken
- Delningsnamnet
- (Valfritt) Namnområdet eller schemanamnet
- (Valfritt) Tabellnamnet
Isbergs REST-katalogslutpunkten (icebergEndpoint) och ägartoken finns i den autentiseringsfil som delas med dig av dataleverantören. Mer information finns i Innan du börjar. Resursnamnet, namnområdet och tabellnamnet kan identifieras programmatiskt med hjälp av OpenSharing-API:er.
Important
icebergEndpoint Finns i autentiseringsfilen och har formatet <workspace-url>/api/2.0/delta-sharing/metastores/<metastore-id>/iceberg.
I följande exempel visas hur du hämtar ytterligare autentiseringsuppgifter. Ange slutpunkten, Iceberg-slutpunkten och ägartoken från autentiseringsfilen där det behövs:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
Note
Den här metoden hämtar alltid den mest up-to-date-listan över tillgångar. Det kräver dock internetåtkomst och kan vara svårare att integrera i miljöer utan kod.
Konfigurera Isbergskatalog
När du har hämtat de nödvändiga autentiseringsuppgifterna för anslutningen konfigurerar du klienten så att den använder isbergs-REST-katalogslutpunkterna för att skapa och fråga tabeller.
Skapa en katalogintegrering för varje delning.
USE ROLE ACCOUNTADMIN; CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER> CATALOG_SOURCE = ICEBERG_REST TABLE_FORMAT = ICEBERG REST_CONFIG = ( CATALOG_URI = '<icebergEndpoint>', WAREHOUSE = '<share_name>', ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) REST_AUTHENTICATION = ( TYPE = BEARER, BEARER_TOKEN = '<bearerToken>' ) ENABLED = TRUE;Du kan också lägga till
REFRESH_INTERVAL_SECONDSför att hålla metadata uppdaterade. Ange värdet baserat på katalogens uppdateringsfrekvens.REFRESH_INTERVAL_SECONDS = 30När katalogen har konfigurerats skapar du en databas från katalogen. Detta skapar automatiskt alla scheman och tabeller i katalogen.
CREATE DATABASE <DATABASE_PLACEHOLDER> LINKED_CATALOG = ( CATALOG = <CATALOG_PLACEHOLDER> );Kontrollera att delning lyckades genom att fråga från en tabell i databasen. Du bör se delade data från Azure Databricks.
Om resultatet är tomt eller om ett fel inträffar följer du de här vanliga felsökningsstegen:
- Dubbelkolla behörigheter, status för generering av ögonblicksbilder och REST-autentiseringsuppgifter.
- Kontakta dataleverantören.
- Se dokumentationen som är specifik för din Iceberg-klient.
Exempel: Få åtkomst till delade tabeller med olika Iceberg-klienter
Följande exempel visar hur du får åtkomst till öppna delade tabeller med hjälp av externa Iceberg-klienter, till exempel Snowflake, Apache Spark, PyIceberg och REST API, när du har hämtat dina autentiseringsuppgifter för anslutningen. Mer information om hur du hämtar autentiseringsuppgifter för anslutningar finns i Innan du börjar.
Snowflake
Om du vill läsa delade datatillgångar i Snowflake laddar du upp filen med autentiseringsuppgifter som du laddade ned och genererar det nödvändiga SQL-kommandot:
Klicka på Snowflake-ikonen från aktiveringslänken för OpenSharing.
På sidan Snowflake-integrering laddar du upp filen med autentiseringsuppgifter som du fick från dataprovidern.

När du har läst in autentiseringsuppgifterna väljer du den resurs som du vill komma åt i Snowflake.
Klicka på Generera SQL när du har valt önskade tillgångar.
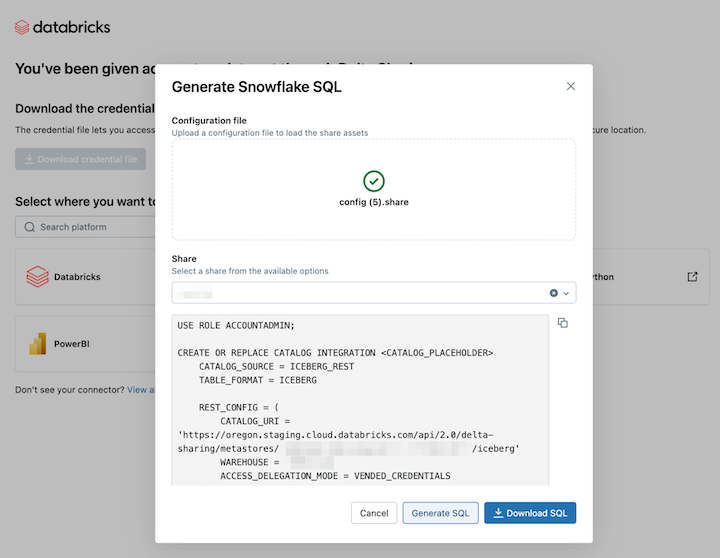
Kopiera och klistra in den genererade SQL-filen i snowflake-kalkylbladet. Ersätt
CATALOG_PLACEHOLDERmed namnet på den katalog som du vill använda ochDATABASE_PLACEHOLDERmed namnet på den databas som du vill använda.
Begränsningar
Anslutning till Iceberg REST-katalogen i Snowflake har följande begränsningar:
- Metadatafilen uppdateras inte automatiskt med den senaste ögonblicksbilden. Du måste förlita dig på automatisk uppdatering eller manuella uppdateringar.
- R2 stöds inte.
- Alla begränsningar för Iceberg-klienten gäller.
Apache Spark
Om du vill komma åt delade tabeller med Apache Spark konfigurerar du API:et för Isbergs REST-katalog med följande inställningar. Ersätt <spark-catalog-name> med ett namn på katalogen och ange dina autentiseringsuppgifter för anslutningen:
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
# Configuration for accessing tables shared using Delta Sharing
"spark.sql.catalog.<spark-catalog-name>":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<spark-catalog-name>.type": "rest",
"spark.sql.catalog.<spark-catalog-name>.uri": "<icebergEndpoint>",
"spark.sql.catalog.<spark-catalog-name>.token": "<bearerToken>",
"spark.sql.catalog.<spark-catalog-name>.warehouse":"<share_name>",
"spark.sql.catalog.<spark-catalog-name>.scope":"all-apis"
PyIceberg
PyIceberg är en Python-implementering för åtkomst till Iceberg-tabeller utan att använda en JVM. PyIceberg kräver pyarrow tabellåtgärder som att läsa data och inspektera tabellmetadata. Installera PyIceberg med pyarrow extra komponenter:
pip install "pyiceberg[pyarrow]"
Om du vill komma åt delade tabeller lägger du till följande katalogkonfiguration i PyIceberg-konfigurationsfilen:
catalog:
delta_sharing:
type: rest
uri: <icebergEndpoint>
warehouse: <share_name>
token: <bearerToken>
REST-API
Använd ett REST API-anrop som i följande curl exempel för att läsa in en tabell och hämta dess metadata tillsammans med tillfälliga autentiseringsuppgifter för åtkomst till datafilerna:
curl -X GET -H "Authorization: Bearer <bearerToken>" -H "Accept: application/json" \
<icebergEndpoint>/v1/shares/<share_name>/namespaces/<schema_name>/tables/<table_name>
Svaret innehåller metadata för Iceberg-tabellen, S3-platsen och tillfälliga AWS-autentiseringsuppgifter som gör att klienten kan läsa datafilerna:
{
"metadata-location": "s3://bucket/path/to/iceberg/table/metadata/file",
"metadata": <iceberg-table-metadata-json>,
"config": {
"expires-at-ms": "<epoch-ts-in-millis>",
"s3.access-key-id": "<temporary-s3-access-key-id>",
"s3.session-token": "<temporary-s3-session-token>",
"s3.secret-access-key": "<temporary-secret-access-key>",
"client.region": "<aws-bucket-region-for-metadata-location>"
}
}
Begränsningar för Iceberg-klient
Följande begränsningar gäller vid frågor mot OpenSharing-data från Iceberg-klienter:
- Om namnområdet innehåller fler än 100 delade vyer när du listar tabeller i ett namnområde begränsas svaret till de första 100 vyerna.
Apache Spark: Läsa delade data
Följ dessa steg för att komma åt delade data med Spark 3.x eller senare.
Dessa instruktioner förutsätter att du har åtkomst till autentiseringsfilen som delades av dataprovidern. Se Hämta åtkomst i delningsmodellen Databricks-to-Open.
Important
Kontrollera att din autentiseringsfil är tillgänglig för Apache Spark med hjälp av en absolut sökväg. Sökvägen kan referera till ett molnobjekt eller en Unity Catalog-volym.
Note
Om du använder Spark på en Azure Databricks-arbetsyta som är aktiverad för Unity Catalog och du använde importproviderns användargränssnitt för att importera providern och dela, gäller inte anvisningarna i det här avsnittet för dig. Du kan komma åt delade tabeller precis som andra tabeller som är registrerade i Unity Catalog. Du behöver inte installera delta-sharing Python-anslutningsprogrammet eller ange sökvägen till autentiseringsfilen. Se Azure Databricks: Läsa delade data med hjälp av Databricks-to-Open-delningsanslutningar.
Installera Anslutningsapparna OpenSharing Python och Spark
Om du vill komma åt metadata som är relaterade till delade data, till exempel listan över tabeller som delas med dig, gör du följande. I det här exemplet används Python.
Installera delta-sharing Python-anslutning. Mer information om begränsningar för Python-anslutningsprogram finns i Begränsningar för OpenSharing Python-anslutningsprogram.
pip install delta-sharing
Visa en lista över delade tabeller med Spark
Lista tabellerna i delningen. I följande exempel ersätter du <profile-path> med platsen för autentiseringsfilen.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Resultatet är en matris med tabeller, tillsammans med metadata för varje tabell. Följande utdata visar två tabeller:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Om utdata är tomma eller inte innehåller de tabeller du förväntar dig kontaktar du dataprovidern.
Få åtkomst till delade data med Spark
Kör följande och ersätt dessa variabler:
-
<profile-path>: platsen för autentiseringsfilen. -
<share-name>: värdetshare=för tabellen. -
<schema-name>: värdetschema=för tabellen. -
<table-name>: värdetname=för tabellen. -
<version-as-of>: valfri. Tabellversionen för inläsning av data. Fungerar bara om dataprovidern delar tabellens historik. Kräverdelta-sharing-spark0.5.0 eller senare versioner. -
<timestamp-as-of>: valfri. Läs in data från versionen som är före eller vid den angivna tidsstämpeln. Fungerar bara om dataprovidern delar tabellens historik. Kräverdelta-sharing-spark0.6.0 eller högre.
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
Scala
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Få åtkomst till dataflöde för delad ändring med Spark
Om tabellhistoriken har delats med dig och ändringsdataflödet (CDF) är aktiverat i källtabellen kan du komma åt ändringsdataflödet genom att köra följande och ersätta dessa variabler. Kräver delta-sharing-spark 0.5.0 eller senare versioner.
En startparameter måste anges.
-
<profile-path>: platsen för autentiseringsfilen. -
<share-name>: värdetshare=för tabellen. -
<schema-name>: värdetschema=för tabellen. -
<table-name>: värdetname=för tabellen. -
<starting-version>: valfri. Startversionen av sökfrågan, inkluderande. Ange som Lång. -
<ending-version>: valfri. Slutversionen av sökfrågan, inklusive. Om slutversionen inte tillhandahålls använder API:et den senaste tabellversionen. -
<starting-timestamp>: valfri. Starttidsstämpeln för frågan konverteras till en version skapad vid eller efter den här tidsstämpeln. Ange som en sträng i formatetyyyy-mm-dd hh:mm:ss[.fffffffff]. -
<ending-timestamp>: valfri. Den avslutande tidsstämpeln för frågan konverteras till en version som skapades tidigare eller lika med den här tidsstämpeln. Ange som en sträng i formatetyyyy-mm-dd hh:mm:ss[.fffffffff]
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Om utdata är tomma eller inte innehåller de data du förväntar dig kontaktar du dataleverantören.
Få åtkomst till en delad tabell med Spark Structured Streaming
Om tabellhistoriken delas med dig kan du strömma läsning av delade data. Kräver delta-sharing-spark 0.6.0 eller högre.
Alternativ som stöds:
-
ignoreDeletes: Ignorera transaktioner som tar bort data. -
ignoreChanges: Bearbeta uppdateringar igen om filer skrevs om i källtabellen på grund av en dataförändringsåtgärd somUPDATE,MERGE INTO,DELETE(inom partitioner) ellerOVERWRITE. Oförändrade rader kan fortfarande sändas ut. Därför bör nedströmskonsumenterna kunna hantera dubbletter. Raderingar sprids inte nedströms.ignoreChangesinkluderarignoreDeletes. Om du använderignoreChangesstörs därför inte dataströmmen av borttagningar eller uppdateringar av källtabellen. -
startingVersion: Den delade tabellversion som ska startas från. Alla tabelländringar från och med den här versionen (inklusive) läses av strömningskällan. -
startingTimestamp: Tidsstämpeln som ska startas från. Alla tabelländringar som har committerats vid eller efter tidsstämpeln (inklusive) läses av streamingkällan. Exempel:"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: Antalet nya filer som ska beaktas i varje mikrobatch. -
maxBytesPerTrigger: Mängden data som bearbetas i varje mikrobatch. Det här alternativet anger ett "mjukt maxvärde", vilket innebär att en batch bearbetar ungefär den här mängden data och kan bearbeta mer än gränsen för att få strömningsfrågan att gå framåt i de fall då den minsta indataenheten är större än den här gränsen. -
readChangeFeed: Stream läser ändringsdataflödet för den delade tabellen.
Alternativ som inte stöds:
Trigger.availableNow
Exempel på strukturerade strömningsfrågor
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Se även Begrepp för strukturerad direktuppspelning.
Läs tabeller med borttagningsvektorer eller kolumnmappning aktiverat
Important
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Borttagningsvektorer är en funktion för lagringsoptimering som leverantören kan aktivera i delade Delta-tabeller. Se Borttagningsvektorer i Databricks.
Azure Databricks stöder även kolumnmappning för Delta-tabeller. Se Byt namn på och ta bort kolumner med kolumnmappning i Delta Lake.
Om providern har delat en tabell med borttagningsvektorer eller kolumnmappning aktiverad kan du läsa tabellen med hjälp av beräkning som kör delta-sharing-spark 3.1 eller senare. Om du använder Databricks-kluster kan du utföra batchläsningar med hjälp av ett kluster som kör Databricks Runtime 14.1 eller senare. CDF- och strömningsfrågor kräver Databricks Runtime 14.2 eller senare.
Du kan utföra batchfrågor som de är, eftersom de automatiskt kan lösas baserat på tabellfunktionerna i den delade tabellen.
Om du vill läsa en cdf (change data feed) eller utföra strömmande frågor på delade tabeller med borttagningsvektorer eller kolumnmappning aktiverat måste du ange det ytterligare alternativet responseFormat=delta.
I följande exempel visas frågor om batch, CDF och strömning:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Läsa kolumner för radspårning i delade tabeller
Om dataleverantören har aktiverat radspårning i en delad tabell kan du köra frågor mot metadatakolumnerna för radspårning med Scala Spark. En lista över tillgängliga kolumner finns i Radspårning i Databricks .
Du måste ange responseFormat alternativet till delta.
spark.read.format("deltaSharing")
.option("responseFormat", "delta")
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.select("_metadata.row_id")
.show()
Note
Endast deltasvarsformatet stöds för att fråga efter radspårningskolumner i Spark-klienten. Dumpkopplingar stöds inte.
Pandas: Läsa delade data
Följ dessa steg för att komma åt delade data i pandas 0.25.3 eller senare.
Dessa instruktioner förutsätter att du har åtkomst till autentiseringsfilen som delades av dataprovidern. Se Hämta åtkomst i delningsmodellen Databricks-to-Open.
Note
Om du använder pandas på en Azure Databricks-arbetsyta som är aktiverad för Unity Catalog och du använde importproviderns användargränssnitt för att importera providern och dela, gäller inte anvisningarna i det här avsnittet för dig. Du kan komma åt delade tabeller precis som andra tabeller som är registrerade i Unity Catalog. Du behöver inte installera delta-sharing Python-anslutningsprogrammet eller ange sökvägen till autentiseringsfilen. Se Azure Databricks: Läsa delade data med hjälp av Databricks-to-Open-delningsanslutningar.
Installera OpenSharing Python-anslutningsappen
För att få åtkomst till metadata som rör delade data, till exempel listan över tabeller som delas med dig, måste du installera delta-sharing Python connector. Mer information om begränsningar för Python-anslutningsprogrammet finns i Begränsningar för OpenSharing Python-anslutningsprogrammet.
pip install delta-sharing
Lista delade tabeller med hjälp av pandas
Om du vill visa en lista över tabellerna i resursen kör du följande och ersätter <profile-path>/config.share med platsen för autentiseringsfilen.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Om utdata är tomma eller inte innehåller de tabeller du förväntar dig kontaktar du dataprovidern.
Få åtkomst till delade data med hjälp av pandas
Om du vill komma åt delade data i pandas med hjälp av Python kör du följande och ersätter variablerna på följande sätt:
-
<profile-path>: platsen för autentiseringsfilen. -
<share-name>: värdetshare=för tabellen. -
<schema-name>: värdetschema=för tabellen. -
<table-name>: värdetname=för tabellen.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Få åtkomst till ett dataflöde för delad ändring med hjälp av pandas
Om du vill komma åt ändringsdataflödet för en delad tabell i pandas med python kör du följande genom att ersätta variablerna på följande sätt. En ändringsdatafeed kanske inte är tillgänglig, beroende på om dataleverantören delade ändringsdataflödet för tabellen eller inte.
-
<starting-version>: valfri. Startversionen av sökfrågan, inkluderande. -
<ending-version>: valfri. Slutversionen av sökfrågan, inklusive. -
<starting-timestamp>: valfri. Starttidsstämpeln för frågan. Detta konverteras till en version som skapats större än eller lika med den här tidsstämpeln. -
<ending-timestamp>: valfri. Den avslutande tidsstämpeln för frågan. Detta konverteras till en version som skapats tidigare eller lika med den här tidsstämpeln.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Om utdata är tomma eller inte innehåller de data du förväntar dig kontaktar du dataleverantören.
Power BI: Läsa delade data
Med Power BI OpenSharing-anslutningsappen kan du identifiera, analysera och visualisera datauppsättningar som delas med dig via OpenSharing Open Protocol.
Requirements
- Power BI Desktop 2.99.621.0 eller senare.
- Åtkomst till autentiseringsfilen som delades av dataprovidern. Se Hämta åtkomst i delningsmodellen Databricks-to-Open.
Ansluta till Databricks
Gör följande för att ansluta till Azure Databricks med hjälp av OpenSharing-anslutningsappen:
- Öppna den delade autentiseringsfilen med en textredigerare för att hämta slutpunkts-URL:en och token.
- Öppna Power BI Desktop.
- På menyn Hämta data söker du efter OpenSharing.
- Välj anslutningsappen och klicka på Anslut.
- Ange slutpunkts-URL:en som du kopierade från filen med autentiseringsuppgifter till fältet OpenSharing Server-URL .
- Du kan också ange en radgräns för det maximala antalet rader som du kan ladda ned på fliken Avancerade alternativ. Detta är inställt på 1 miljon rader som standard.
- Klicka på OK.
- För autentisering kopierar du den token som du hämtade från autentiseringsuppgifterna till Ägartoken.
- Klicka på Anslut.
Begränsningar för Power BI OpenSharing-anslutningsappen
Power BI OpenSharing Connector har följande begränsningar:
- De data som anslutningsappen läser in måste passa in i datorns minne. För att hantera det här kravet begränsar anslutningsappen antalet importerade rader till den radgräns som du anger under fliken Avancerade alternativ i Power BI Desktop.
Tableau: Läs delad data
Tableau OpenSharing-anslutningen gör att du kan upptäcka, analysera och visualisera datauppsättningar som delas med dig via det öppna protokollet OpenSharing.
Requirements
- Tableau Desktop och Tableau Server 2024.1 eller senare
- Åtkomst till autentiseringsfilen som delades av dataprovidern. Se Hämta åtkomst i delningsmodellen Databricks-to-Open.
Anslut till Azure Databricks
Gör följande för att ansluta till Azure Databricks med hjälp av OpenSharing-anslutningsappen:
- Gå till Tableau Exchange, följ anvisningarna för att ladda ned OpenSharing Connector och placera den i en lämplig skrivbordsmapp.
- Öppna Tableau Desktop.
- På sidan Anslutningsappar söker du efter "OpenSharing by Databricks".
- Välj Ladda upp resursfil och välj den autentiseringsuppgiftsfil som delades av providern.
- Klicka på Hämta data.
- I Datautforskaren väljer du tabellen.
- Du kan också lägga till SQL-filter eller radgränser.
- Klicka på Hämta tabelldata.
Begränsningar
Tableau OpenSharing Connector har följande begränsningar:
- De data som anslutningsappen läser in måste passa in i datorns minne. För att hantera det här kravet begränsar anslutningsappen antalet importerade rader till den radgräns som du angav i Tableau.
- Alla kolumner returneras som typ
String. - SQL Filter fungerar bara om OpenSharing-servern stöder predicateHint.
- Borttagningsvektorer stöds inte.
- Kolumnmappning stöds inte.
Begränsningar för OpenSharing Python-anslutningsprogram
Dessa begränsningar är specifika för OpenSharing Python-anslutningsappen:
- OpenSharing Python connector 1.1.0+ stöder ögonblicksbildsfrågor i tabeller med kolumnmappning, men CDF-frågor på tabeller med kolumnmappning stöds inte.
- OpenSharing-Python-anslutningsappen misslyckas med CDF-frågor med
use_delta_format=Trueom schemat ändrades under det efterfrågade versionsintervallet.
Begränsningar för strömmande tabeller
Du kan bara läsa den aktuella ögonblicksbilden av en delad strömningstabell. Följande funktioner stöds inte för direktuppspelningstabeller i Databricks-to-Open-delning:
- Köra frågor mot tabellens historikdata
- Köra frågor mot tabellens ändringsdataflöde (CDF)
- Använda tabellen som källa för Spark Structured Streaming
Begränsningar för materialiserad vy
Du kan bara läsa den aktuella ögonblicksbilden av en delad materialiserad vy. Användning av en materialiserad vy som källa för Spark Structured Streaming stöds inte i Databricks-to-Open-delning.
Begära en ny autentiseringsuppgift
Om url:en för aktivering av autentiseringsuppgifter eller nedladdade autentiseringsuppgifter går förlorad, skadas eller komprometteras, eller om autentiseringsuppgifterna upphör att gälla utan att leverantören skickar en ny, kontaktar du leverantören för att begära en ny autentiseringsuppgift.
Om du är en Azure Databricks mottagare som importerade autentiseringsuppgifterna som ett providerobjekt i Unity Catalog använder du de nya autentiseringsuppgifterna med hjälp av Databricks REST API. Se Rotera autentiseringsuppgifter för öppna mottagare.