Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a: ![]() SQL Server no Linux
SQL Server no Linux
Este artigo descreve as características dos grupos de disponibilidade (AGs) em instalações do SQL Server baseadas em Linux. Também cobre as diferenças entre os AGs baseados em clusters de failover Linux e Windows Server (WSFC). Consulte O que é um grupo de disponibilidade Always On? para os conceitos básicos dos AGs, pois funcionam da mesma forma no Windows e Linux, exceto no WSFC.
Observação
Em grupos de disponibilidade que não utilizam Windows Server Failover Clustering (WSFC), como grupos de disponibilidade read-scale, ou grupos de disponibilidade no Linux, colunas nas DMVs de grupos de disponibilidade relacionadas com o cluster podem mostrar dados sobre um cluster interno predefinido. Estas colunas são apenas para uso interno e podem ser desconsideradas.
De um ponto de vista geral, os grupos de disponibilidade no SQL Server on Linux são os mesmos que nas implementações baseadas em WSFC. Isso significa que todas as limitações e recursos são os mesmos, com algumas exceções. As principais diferenças incluem:
- O Microsoft Distributed Transaction Coordinator (DTC) é suportado sob Linux a partir do SQL Server 2017 16. No entanto, o DTC ainda não é suportado em Grupos de Disponibilidade no Linux. Se as suas aplicações requerem o uso de transações distribuídas e um AG, implemente o SQL Server no Windows.
- Implantações baseadas em Linux que exigem alta disponibilidade usam o Pacemaker para clustering em vez de um WSFC.
- Ao contrário da maioria das configurações para AGs no Windows, exceto no cenário do Workgroup Cluster, o Pacemaker nunca requer Active Directory Domain Services (AD DS).
- Como falhar um AG de um nó para outro é diferente entre Linux e Windows.
- Certas definições, como
required_synchronized_secondaries_to_commitsó podem ser alteradas via Pacemaker no Linux, enquanto uma instalação baseada em WSFC usa Transact-SQL.
Número de réplicas e nós de Cluster
Um AG na edição Standard do SQL Server pode ter duas réplicas no total: uma primária e uma secundária que só pode ser usada para fins de disponibilidade. Ele não pode ser usado para mais nada, tais como consultas inteligíveis. Um AG na edição SQL Server Enterprise pode ter até nove réplicas no total: uma principal e até oito secundárias, das quais até três (incluindo a primária) podem ser síncronas. Se estiver usando um cluster subjacente, pode haver um máximo de 16 nós no total quando o Corosync estiver envolvido. Um grupo de disponibilidade pode abranger no máximo nove dos 16 nós com a edição SQL Server Enterprise, e dois com a edição Standard do SQL Server.
Uma configuração de duas réplicas que requer a capacidade de failover automático para outra réplica requer o uso de uma réplica somente de configuração, conforme descrito em Réplica e quórum somente de configuração. Réplicas apenas de configuração foram introduzidas no SQL Server 2017 (14.x) Cumulative Update 1 (1), pelo que essa deverá ser a versão mínima implementada para esta configuração.
Se o Pacemaker for usado, ele deve ser configurado corretamente para que permaneça ativo e funcionando. Isto significa que o quórum e o isolamento de um nó com falha devem ser implementados corretamente do ponto de vista do Pacemaker, além de quaisquer requisitos do SQL Server, como uma réplica de configuração única.
Réplicas secundárias legíveis são apenas suportadas com a edição SQL Server Enterprise.
Tipo de cluster e modo de failover
Novidade no SQL Server 2017 (14.x) é a introdução de um tipo de cluster para AGs. Para Linux, existem dois valores válidos: Externo e Nenhum. Um tipo de cluster "External" significa que o Pacemaker é utilizado sob o AG. Usar Externo como tipo de cluster exige que o modo de failover esteja definido como Externo também (também novidade no SQL Server 2017 (14.x)). O failover automático é suportado, mas, ao contrário de um WSFC, o modo de failover é definido como externo, não automático, quando se utiliza o Pacemaker. Ao contrário de um WSFC, a parte Pacemaker do AG é criada depois que o AG é configurado.
Um tipo de cluster 'nenhum' significa que não há necessidade de Pacemaker, nem o AG o utiliza. Mesmo em servidores com o Pacemaker configurado, se um AG estiver configurado com um tipo de cluster de None, o Pacemaker não verá nem gerenciará esse AG. Um tipo de cluster Nenhum suporta apenas a transferência manual de uma réplica primária para uma secundária. Um Grupo de Disponibilidade criado com a configuração 'Nenhum' é direcionado principalmente para atualizações e escalonamento de leitura. Embora possa ser utilizado em cenários como recuperação de desastres ou disponibilidade local em que não é necessário o uso de failover automático, não é aconselhável. A história do ouvinte também é mais complexa sem o Pacemaker.
O tipo de cluster é armazenado na vista SQL Server de gestão dinâmica (DMV) sys.availability_groups, nas colunas cluster_type e cluster_type_desc.
secundários_sincronizados_necessários_para_confirmar
Há uma nova configuração no SQL Server 2017 (14.x) que é usada por AGs chamada required_synchronized_secondaries_to_commit. Isso informa ao AG o número de réplicas secundárias que devem estar em sincronização com a primária. Isso permite coisas como failover automático (somente quando integrado ao Pacemaker com um tipo de cluster externo) e controla o comportamento de coisas como a disponibilidade do primário se o número certo de réplicas secundárias estiver online ou offline. Para entender mais sobre como isso funciona, consulte Alta disponibilidade e proteção de dados para configurações de grupo de disponibilidade. O valor required_synchronized_secondaries_to_commit é definido por defeito e mantido pelo Pacemaker/SQL Server. Você pode substituir manualmente esse valor.
A combinação de required_synchronized_secondaries_to_commit e o novo número de sequência (que é armazenado em sys.availability_groups) informa o Pacemaker e SQL Server que, por exemplo, pode ocorrer um failover automático. Nesse caso, uma réplica secundária teria o mesmo número de sequência que a principal, o que significa que está atualizada com todas as informações de configuração mais recentes.
Há três valores que podem ser definidos para required_synchronized_secondaries_to_commit: 0, 1 ou 2. Eles controlam o comportamento do que acontece quando uma réplica fica indisponível. Os números correspondem ao número de réplicas secundárias que devem ser sincronizadas com a primária. O comportamento é o seguinte no Linux:
| Configurações | Descrição |
|---|---|
0 |
As réplicas secundárias não precisam estar no estado sincronizado com a principal. No entanto, se os secundários não estiverem sincronizados, não haverá failover automático. |
1 |
Uma réplica secundária deve estar num estado sincronizado com a primária; a comutação automática é possível. O banco de dados primário não estará disponível até que uma réplica síncrona secundária esteja disponível. |
2 |
Ambas as réplicas secundárias em uma configuração AG de três ou mais nós devem ser sincronizadas com a principal; failover automático é possível. |
required_synchronized_secondaries_to_commit Controla não apenas o comportamento de failovers com réplicas síncronas, mas também a perda de dados. Com um valor de 1 ou 2, uma réplica secundária deve ser sempre sincronizada, para garantir redundância de dados. Isso significa que não há perda de dados.
Para alterar o valor de required_synchronized_secondaries_to_commit, use a seguinte sintaxe:
Observação
Alterar o valor faz com que o recurso seja reiniciado, o que significa uma breve interrupção. A única maneira de evitar isso é definir o recurso para não ser gerenciado pelo cluster temporariamente.
Red Hat Enterprise Linux (RHEL) e Ubuntu
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<value>
Servidor SUSE Linux Enterprise (SLES)
sudo crm resource param ms-<AGResourceName> set required_synchronized_secondaries_to_commit <value>
Observação
A partir do SQL Server 2025 (17.x), o SUSE Linux Enterprise Server (SLES) não é suportado.
Neste exemplo, <AGResourceName> é o nome do recurso configurado para o AG e <value> é 0, 1 ou 2. Para retornar ao padrão em que o Pacemaker gere o parâmetro, execute a mesma instrução sem valor.
O failover automático de um AG é possível quando as seguintes condições são atendidas:
- A réplica primária e a réplica secundária estão configuradas para a movimentação de dados síncrona.
- O secundário está em estado sincronizado (não sincronizando), o que significa que ambos estão no mesmo ponto de dados.
- O tipo de cluster é definido como Externo. O failover automático não é possível com um tipo de cluster Nenhum.
- Para que a réplica secundária
sequence_numberse torne a primária, ela deve ter o maior número de sequência - em outras palavras, a réplica secundáriasequence_numberdeve corresponder à réplica primária original.
Se essas condições forem atendidas e o servidor que hospeda a réplica primária falhar, o AG transferirá a posse para uma réplica síncrona. O comportamento de réplicas síncronas (das quais pode haver três no total: uma réplica primária e duas réplicas secundárias) pode ser controlado por required_synchronized_secondaries_to_commit. Isto funciona com AGs tanto no Windows como no Linux, mas está configurado de forma diferente. No Linux, o valor é configurado automaticamente pelo cluster no próprio recurso AG.
Réplica e quórum somente de configuração
Uma réplica somente de configuração foi introduzida para resolver as limitações na manipulação de quórum com o Pacemaker, especialmente ao cercar um nó com falha. Ter apenas uma configuração com dois nós não funciona para um Grupo de Disponibilidade (AG). Para um FCI, os mecanismos de quórum fornecidos pelo Pacemaker podem ser adequados, porque toda a arbitragem de failover do FCI acontece na camada de cluster. Para um AG, a arbitragem sob Linux ocorre no SQL Server, onde todos os metadados são armazenados. É aqui que a réplica somente de configuração entra em jogo.
Na falta de outras opções, seria necessário um terceiro nó e pelo menos uma réplica sincronizada. A réplica somente de configuração armazena a configuração AG na base de dados master, da mesma forma que as outras réplicas na configuração AG. A réplica somente de configuração não inclui os bancos de dados de usuários que participam do AG (Grupo de Disponibilidade). Os dados de configuração são enviados de forma síncrona a partir do primário. Esses dados de configuração são usados durante failovers, sejam eles automáticos ou manuais.
Para que um AG mantenha o quórum e permita failovers automáticos com um tipo de cluster Externo, deve:
- Ter três réplicas síncronas (apenas edição SQL Server Enterprise); ou
- Ter duas réplicas (primária e secundária) e uma réplica apenas de configuração.
Failovers manuais podem acontecer usando tipos de cluster Externo ou Nenhum para configurações AG. Embora uma réplica somente de configuração possa ser configurada com um Grupo de Disponibilidade que tenha o tipo de cluster definido como Nenhum, isso não é recomendado, pois complica a implementação. Para essas configurações, modifique required_synchronized_secondaries_to_commit manualmente para ter um valor de pelo menos 1, para que haja pelo menos uma réplica sincronizada.
Uma réplica apenas de configuração pode ser alojada em qualquer edição do SQL Server, incluindo o SQL Server Express. Isto minimiza os custos de licenciamento e garante que funciona com AGs na edição SQL Server Standard. Isto significa que o terceiro servidor exigido só precisa de cumprir a especificação mínima para o SQL Server, uma vez que não está a receber tráfego de transações de utilizadores para o AG.
Quando uma réplica somente de configuração é usada, ela tem o seguinte comportamento:
Por padrão,
required_synchronized_secondaries_to_commité definido como 0. Isso pode ser modificado manualmente para 1, se desejado.Se o primário falhar e
required_synchronized_secondaries_to_commitfor 0, a réplica secundária tornar-se-á o novo primário e ficará disponível para leitura e escrita. Se o valor for 1, o failover automático ocorrerá, mas não aceitará novas transações até que a outra réplica esteja online.Se uma réplica secundária falhar e
required_synchronized_secondaries_to_commitfor 0, a réplica primária ainda aceita transações, mas se a réplica primária falhar nesse momento, não há proteção para os dados nem failover possível (manual ou automático), pois não há uma réplica secundária disponível.Se a réplica somente de configuração falhar, o AG funcionará normalmente, mas nenhum failover automático será possível.
Se a réplica secundária síncrona e a réplica somente de configuração falharem, a principal não poderá aceitar transações e não haverá para onde a primária fazer failover.
Vários grupos de disponibilidade
Mais do que um AG pode ser criado em cada cluster Pacemaker ou em conjunto de servidores. A única limitação são os recursos do sistema. A propriedade da AG é demonstrada pelo detentor principal. Diferentes AGs podem pertencer a diferentes nós; nem todos precisam ser executados no mesmo nó.
Localização de discos e pastas para bancos de dados
Tal como nos AGs baseados em Windows, a estrutura de discos e pastas das bases de dados de utilizadores que participam numa AG deve ser idêntica. Por exemplo, se as bases de dados de utilizadores estiverem em /var/opt/mssql/userdata no Servidor A, essa mesma pasta deverá existir no Servidor B. A única exceção a isto está referida na secção Interoperabilidade com grupos de disponibilidade e réplicas baseados em Windows.
O ouvinte em Linux
O listener é uma funcionalidade opcional para um AG. Ele fornece um único ponto de entrada para todas as conexões (leitura/gravação na réplica primária e/ou somente leitura em réplicas secundárias) para que os aplicativos e os usuários finais não precisem saber qual servidor está hospedando os dados. Em um WSFC, essa é a combinação de um recurso de nome de rede e um recurso IP, que é registrado no AD DS (se necessário) e no DNS. Em combinação com o próprio recurso AG, proporciona essa abstração. Para obter mais informações sobre um ouvinte, consulte Ligar-se a um ouvinte de grupo de disponibilidade Always On.
O ouvinte no Linux é configurado de forma diferente, mas sua funcionalidade é a mesma. Não há nenhum conceito de um recurso de nome de rede no Pacemaker, nem um objeto é criado no AD DS; há apenas um recurso de endereço IP criado no Pacemaker que pode ser executado em qualquer um dos nós. Uma entrada associada ao recurso IP para o ouvinte no DNS com um "nome amigável" precisa ser criada. O recurso IP para o ouvinte só está ativo no servidor que hospeda a réplica primária para esse grupo de disponibilidade.
Se o Pacemaker for usado e um recurso de endereço IP for criado associado ao ouvinte, haverá uma breve interrupção à medida que o endereço IP para em um servidor e começa no outro, seja failover automático ou manual. Embora isso forneça abstração através da combinação de um único nome e endereço IP, não mascara a interrupção. Um aplicativo deve ser capaz de lidar com a desconexão, tendo algum tipo de funcionalidade para detetar isso e reconectar.
No entanto, a combinação do nome DNS e do endereço IP ainda não é suficiente para fornecer toda a funcionalidade que um listener num WSFC fornece, como roteamento somente leitura para réplicas secundárias. Quando configuras um AG, um ouvinte ainda precisa de ser configurado no SQL Server. Isto pode ser visto no assistente e na sintaxe do Transact-SQL. Existem duas formas de configurar isto para funcionar da mesma forma que no Windows:
- Para um AG com um tipo de cluster externo, o endereço IP associado ao listener criado no SQL Server deve ser o endereço IP do recurso criado no Pacemaker.
- Para um AG criado com um tipo de cluster Nenhum, use o endereço IP associado à réplica primária.
A instância associada ao endereço IP fornecido torna-se então o coordenador para coisas como as solicitações de roteamento somente leitura de aplicativos.
Interoperabilidade com grupos de disponibilidade e réplicas baseados no Windows
Um AG que tenha um tipo de cluster Externo ou que seja WSFC não pode ter as suas réplicas distribuídas entre plataformas. Isto é verdade, quer o AG seja edição SQL Server Standard ou edição SQL Server Enterprise. Isso significa que em uma configuração AG tradicional com um cluster subjacente, uma réplica não pode estar em um WSFC e a outra no Linux com Pacemaker.
Um AG com um tipo de cluster NONE pode ter as suas réplicas a atravessar fronteiras do sistema operativo, pelo que podem existir réplicas baseadas em Linux e Windows na mesma AG. Um exemplo é mostrado aqui, onde a réplica principal é baseada no Windows, enquanto a secundária está numa das distribuições Linux.
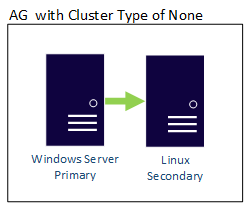
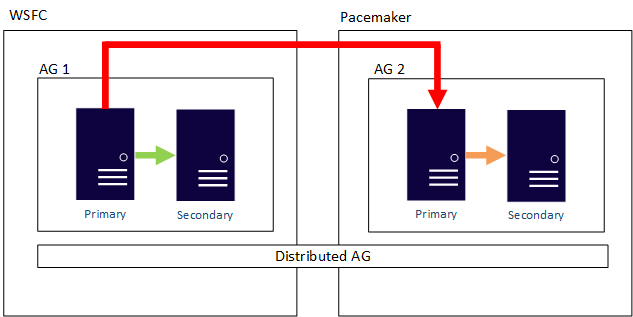
Um AG distribuído também pode cruzar os limites do sistema operacional. Os AGs subjacentes são vinculados pelas regras de como eles são configurados, como um configurado com External sendo somente Linux, mas o AG ao qual ele está unido pode ser configurado usando um WSFC. Considere o seguinte exemplo:
Conteúdo relacionado
- Configurar grupo de disponibilidade do SQL Server para alta disponibilidade no Linux
- Configure um grupo de disponibilidade de SQL Server para escala de leitura no Linux
- Configure um cluster Pacemaker para grupos de disponibilidade SQL Server
- Configure o grupo de disponibilidade Always On do SQL Server no Windows e Linux (em várias plataformas)