Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
A memória permite que os agentes de IA se lembrem de informações anteriores na conversa ou de conversas anteriores. Isto permite aos agentes fornecer respostas conscientes do contexto e construir experiências personalizadas ao longo do tempo. Use o Databricks Lakebase, uma base de dados Postgres OLTP totalmente gerida, para gerir o estado e o histórico das conversas.
Requerimentos
- Ative as aplicações Databricks no seu espaço de trabalho. Consulte Configurar seu espaço de trabalho e ambiente de desenvolvimento do Databricks Apps.
- Uma instância Lakebase, veja Criar e gerir uma instância de base de dados.
Memória de curto prazo vs. memória de longo prazo
A memória de curto prazo capta o contexto numa única sessão de conversa, enquanto a memória de longo prazo extrai e armazena informações-chave em várias conversas. Podes construir o teu agente com um ou ambos os tipos de memória.
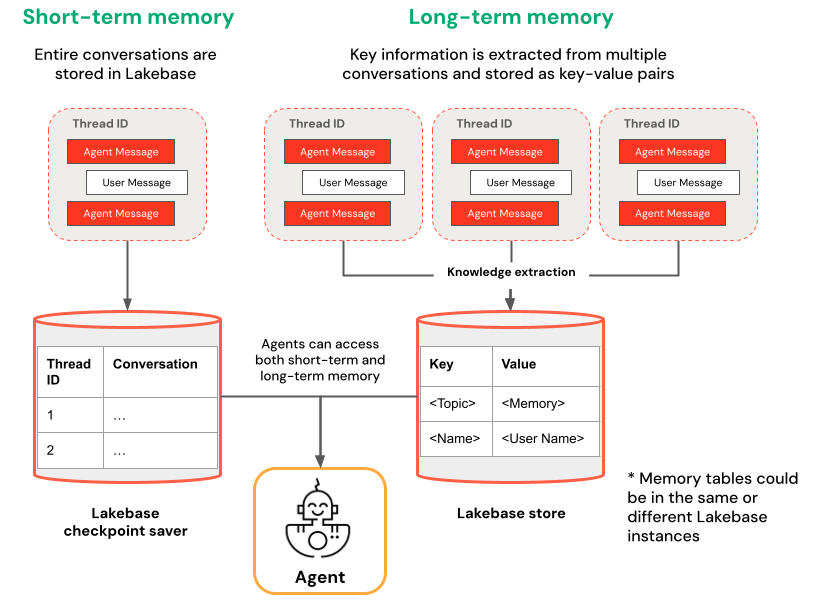
| Memória de curto prazo | Memória de longo prazo |
|---|---|
| Capturar contexto numa única sessão de conversa usando identificadores de thread e criação de pontos de verificação Mantenha o contexto para as perguntas de seguimento durante a sessão |
Extrair e armazenar automaticamente os insights chave ao longo de várias sessões Personalize as interações com base nas preferências passadas Construa uma base de conhecimento sobre os utilizadores que melhore as respostas ao longo do tempo |
Introdução
Para criar um agente com memória nas Databricks Apps, clone um modelo de aplicação pré-construído e siga o fluxo de trabalho de desenvolvimento descrito em Criar um agente de IA e implementá-lo nas Apps. Os modelos seguintes demonstram como adicionar memória de curto e longo prazo a agentes usando frameworks populares.
LangGraph
Clone o modelo agent-langgraph-advanced para construir um agente LangGraph com memória de curto e longo prazo. O template utiliza o ponto de verificação incorporado do LangGraph com o Lakebase para uma gestão de estados durável, incluindo contexto de conversação por threads e informações persistentes sobre o utilizador ao longo das sessões.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-langgraph-advanced
SDK de Agentes OpenAI
Clone o modelo agent-openai-advanced para construir um agente usando o SDK OpenAI Agents com memória de curto prazo. O template utiliza o Lakebase para uma gestão de estado duradoura, permitindo conversas de múltiplos turnos com preservação de estado e gestão automática do histórico de conversação.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-advanced
Execução em segundo plano para agentes de longa duração
O Databricks Apps impõe um tempo limite de ligação HTTP de aproximadamente 300 segundos. A execução em segundo plano permite que as tarefas do agente que excedam este limite continuem a correr após o encerramento da ligação; O cliente recupera os resultados de um endpoint separado ou religa-se para retomar o streaming.
Os modelos avançados — agent-langgraph-advanced e agent-openai-advanced — estendem os modelos base com memória de curto prazo e execução em segundo plano de longa duração através de LongRunningAgentServer de databricks-ai-bridge, que proporciona:
-
Modo em segundo plano: Definir
background=trueno corpo do pedido para devolver imediatamente um ID de resposta e executar o agente de forma assíncrona. -
Recuperar endpoint: Enviar
GET /responses/{id}para obter o resultado final ou para abrir uma conexão de streaming para uma execução em curso. -
Streaming retomável: Cada evento enviado pelo servidor inclui um
sequence_number. Se a ligação cair, volte a ligar-se comstarting_after=Npara continuar a partir do próximo evento. - TASK_TIMEOUT_SECONDS Variável de ambiente que limita a duração da tarefa em segundo plano. Isto é independente do timeout de 120 segundos nas ligações HTTP dos Databricks Apps, que se aplica apenas a um único pedido HTTP. (padrão: 1 hora)
O modelo avançado README mostra exemplos de pedidos para cinco modos cliente:
- Invoke: Um POST padrão sem streaming.
- Stream: Um POST padrão em streaming.
-
Contexto, depois interrogar: POST com
background=true, depois interrogarGET /responses/{id}até concluir. -
Streaming em segundo plano, retomar via stream: POST com
background=trueestream=true; se a ligação cair, reconecte-se aGET /responses/{id}usandostream=true. -
Streaming em segundo plano, retoma via sondagem: Mesmo início; Se a ligação falhar, verifique
GET /responses/{id}o resultado final.
Implemente e consulte o seu agente
Depois de configurar o seu agente com memória, siga os passos em Criar um agente de IA e implemente-o nas Apps para executar o seu agente localmente, avaliá-lo e implementá-lo nas Databricks Apps.