Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Aplica-se a: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Este artigo apresenta as melhores práticas para usar o link Managed Instance para replicar dados entre Azure SQL Managed Instance e as suas instâncias SQL Server alojadas em qualquer lugar. A ligação fornece replicação de dados quase em tempo real entre as réplicas ligadas.
Faça backups de log regularmente
Se o SQL Server for o seu primário inicial, faça o primeiro backup de log no SQL Server após terminar a fase inicial de propagação, quando a base de dados não estiver mais no estado de Restauração... no Azure SQL Managed Instance. Depois, faça backups regulares do log de transações do SQL Server para manter o tamanho do ficheiro de log de transações adequado enquanto o SQL Server estiver no papel principal.
A funcionalidade de ligação replica dados utilizando a tecnologia de grupos de disponibilidade distribuídos baseada em grupos de disponibilidade Always On. A replicação de dados em grupos de disponibilidade distribuída baseia-se na replicação dos registos de registo de transações. A instância principal do SQL Server não consegue truncar nenhum registo de log de transações da base de dados até que sejam replicados para a réplica secundária da base de dados. Se problemas de ligação à rede fizerem com que a replicação do registo de registos de transações seja lenta ou bloqueada, o ficheiro de registo continua a crescer na instância principal. A intensidade da carga de trabalho e a velocidade da rede determinam a velocidade de crescimento. Se uma falha de ligação à rede for prolongada e a carga de trabalho na instância principal for pesada, o ficheiro de registo pode ocupar todo o espaço de armazenamento disponível.
Fazer backups regulares de registos de transações trunca o registo de transações e minimiza o risco de ficar sem espaço na instância principal do SQL Server devido ao crescimento dos ficheiros de registo. Não é necessária qualquer ação extra quando SQL Managed Instance é a primária, pois backups log já são feitos automaticamente. Ao fazer cópias de segurança de registos regularmente no seu principal SQL Server, torna a sua base de dados mais resiliente a eventos de crescimento de registos não planeados. Considere agendar tarefas diárias de backup de logs usando um job do SQL Server Agent.
Pode usar um script Transact-SQL (T-SQL) para fazer backup do ficheiro de log, como o exemplo fornecido nesta secção. Substitua os espaços reservados no script de exemplo pelo nome do banco de dados, nome e caminho do arquivo de backup e a descrição.
Para fazer backup do seu registo de transações, utilize o seguinte exemplo de script Transact-SQL (T-SQL) no SQL Server:
-- Execute on SQL Server
-- Take log backup
BACKUP LOG [<DatabaseName>]
TO DISK = N'<DiskPathandFileName>'
WITH NOFORMAT, NOINIT,
NAME = N'<Description>', SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 1
Use o seguinte comando Transact-SQL (T-SQL) para verificar o espaçamento do log usado pela sua base de dados no SQL Server:
-- Execute on SQL Server
DBCC SQLPERF(LOGSPACE);
A saída da consulta se parece com o exemplo a seguir para o banco de dados de exemplo tpcc:
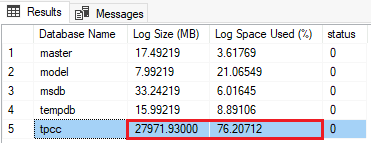
Neste exemplo, o banco de dados usou 76% do log disponível, com um tamanho absoluto de arquivo de log de aproximadamente 27 GB (27.971 MB). Os limites para ação variam de acordo com a sua carga de trabalho. No exemplo anterior, o tamanho do log de transações e a percentagem de utilização do log normalmente indicam que deve fazer uma cópia de segurança do log de transações para truncar o ficheiro log e libertar algum espaço, ou então deve fazer backups de log mais frequentes. Pode também indicar que o truncamento do log de transações está a ser bloqueado por transações abertas. Para mais informações sobre a resolução de problemas de um registo de transações em SQL Server, consulte Troubleshoot a Full Transaction Log (SQL Server Erro 9002). Para mais informações sobre a resolução de problemas de um registo de transações em Azure SQL Managed Instance, consulte Resolver erros de registo de transações com Azure SQL Managed Instance.
Observação
Ao participar numa ligação, o SQL Managed Instance aceita backups automatizados de registos completos e de transações, quer seja ou não a réplica principal. Os backups diferenciais não são feitos, o que pode levar a tempos de restauração mais longos.
Combine a capacidade de desempenho entre réplicas
Quando usar a funcionalidade de ligação, compare a capacidade de desempenho entre o SQL Server e o SQL Managed Instance. Esta correspondência ajuda a evitar problemas de desempenho se a réplica secundária não conseguir acompanhar a replicação a partir da réplica primária, ou após o failover. A capacidade de desempenho inclui núcleos de CPU (ou vCores no Azure), memória e largura de banda de I/O.
Podes monitorizar o desempenho da replicação verificando o tamanho da fila de redo na réplica secundária. O tamanho da fila de refazer mostra o número de registos de log que estão à espera de serem refeitos na réplica secundária. Um tamanho de fila de refazer consistentemente alto mostra que a réplica secundária não consegue acompanhar a réplica principal. Você pode verificar o tamanho da fila de refazer das seguintes maneiras:
- O valor
redo_queue_sizena exibição de gerenciamento dinâmico sys.dm_hadr_database_replica_states na réplica primária. - O valor
InstanceRedoLagReplicationSecondsem Get-AzSqlInstanceLink na réplica primária.
Se o tamanho da fila de refazer for consistentemente alto, considere aumentar os recursos na réplica secundária.
Monitorizar atraso na replicação
Monitorizar o atraso de replicação ajuda-o a determinar a velocidade com que a réplica secundária se sincroniza com a réplica primária. Uma grande discrepância indica que a réplica secundária está a ter dificuldades em acompanhar a réplica primária, o que é tipicamente causado por um débito lento de rede na ligação entre as duas instâncias, uma alocação incompatível de recursos entre as duas réplicas, ou por uma carga de trabalho excessivamente elevada na réplica primária.
Monitorizar o atraso de replicação é especialmente importante ao realizar um failover planeado, que exige que a réplica secundária esteja totalmente sincronizada com a réplica primária antes de o failover poder ser executado. Se houver um atraso elevado na replicação, o failover pode demorar mais para ser concluído e, em alguns casos, pode até falhar.
Use a seguinte consulta T-SQL tanto no SQL Server como na SQL Managed Instance para monitorizar o atraso de replicação entre as réplicas:
-- Execute on SQL Server and SQL Managed Instance
USE master
DECLARE @link_name varchar(max) = '<DAGname>'
SELECT
ag.name [Link name],
ars1.role_desc [Link role],
ars2.connected_state_desc [Link connected state],
ars2.synchronization_health_desc [Link sync health],
drs.secondary_lag_seconds [Link replication latency (seconds)]
FROM
sys.availability_groups ag
JOIN sys.dm_hadr_availability_replica_states ars1
ON ag.group_id = ars1.group_id
JOIN sys.dm_hadr_availability_replica_states ars2
ON ag.group_id = ars2.group_id
JOIN sys.dm_hadr_database_replica_states drs
ON ars2.replica_id = drs.replica_id
WHERE
ag.is_distributed = 1 AND ag.name = @link_name AND ars1.is_local = 1 AND ars2.is_local = 0
GO
Rotacionar certificado
Pode ser necessário rodar manualmente o certificado usado para proteger o endpoint de espelhamento da base de dados no SQL Server. Como o serviço gere e roda automaticamente o certificado usado para proteger o endpoint de espelhamento da base de dados numa instância gerida de SQL, não necessita de o rodar manualmente.
SQL Server
O certificado que usa para proteger o endpoint de espelhamento da base de dados no SQL Server pode expirar. Se o certificado expirar, pode levar à degradação do link. Para evitar este problema, rode o certificado antes de expirar.
Use o seguinte comando Transact-SQL (T-SQL) para verificar a data de expiração do certificado atual:
-- Run on SQL Server
USE MASTER
GO
SELECT * FROM sys.certificates WHERE pvt_key_encryption_type = 'MK'
Se o seu certificado estiver prestes a expirar, ou já expirou, crie um novo certificado e depois altere o endpoint existente para substituir o certificado atual.
Depois de configurar o endpoint para usar o novo certificado, pode retirar o certificado expirado.
SQL Managed Instance
O certificado do endpoint de espelhamento de base de dados na Instância Gerida de SQL é renovado automaticamente periodicamente. Não precisa de monitorizar a data de expiração do certificado endpoint de espelhamento da base de dados no SQL Managed Instance, desde que consiga validar a cadeia de certificados no SQL Server com sucesso.
Validar a cadeia de certificados no SQL Server
Observação
Valide periodicamente a cadeia de certificados para elos existentes ou para resolver problemas com um elo degradado. Se estiver a configurar um novo link ou a completar recentemente os passos nas secções Obtenha a chave pública do certificado da SQL Managed Instance e importe-a para SQL Server e Importar chaves de autoridade certificadora raiz Azure confiáveis para SQL Server, salte esta secção.
Problemas com a cadeia de certificados podem degradar a ligação. Para evitar este problema, valide regularmente a cadeia de certificados em SQL Server.
Os seguintes cenários podem causar problemas na cadeia de certificados no SQL Server:
- Rotação de certificados agendada no SQL Managed Instance.
- Alterações não intencionais ou acidentais aos certificados no SQL Server, como a queda ou alteração do certificado usado para proteger o endpoint de espelhamento da base de dados.
Primeiro, determine o certificate_id do certificado de endpoint MI importado, substituindo o valor de <ManagedInstanceFQDN> e depois executando a seguinte consulta em SQL Server:
-- Run on SQL Server
USE master
SELECT name, subject, certificate_id, start_date, expiry_date
FROM sys.certificates
WHERE issuer_name LIKE '%Microsoft Corporation%' AND name = '<ManagedInstanceFQDN>'
GO
De seguida, valide o certificado substituindo o valor de <certificate_id> do resultado da consulta anterior e executando a seguinte consulta em SQL Server:
-- Run on SQL Server
USE master
EXEC sp_validate_certificate_ca_chain <certificate_id>
GO
Uma resposta de Commands completed successfully. Completion time: ... indica que o certificado do endpoint MI foi validado com sucesso.
Importante
O procedimento sp_validate_certificate_ca_chain armazenado depende dos serviços do sistema operativo host para realizar a validação de certificados, o que pode envolver uma verificação online de revogação de certificados. Se o sistema operativo anfitrião não estiver configurado para aceder à internet, a execução falha mesmo que a cadeia de certificados seja válida.
Se encontrar um erro, a mitigação mais fiável é restaurar a cadeia de certificados ao primeiro eliminar todos os certificados criados nas secções Obter a chave pública do certificado de SQL Managed Instance e importá-la para o SQL Server e Importar as chaves da autoridade de certificação raiz confiáveis do Azure para o SQL Server, e depois de os reimportar novamente.
Adicionar sinalizadores de rastreamento de inicialização
Em SQL Server, existem duas bandeiras de traço (-T1800 e -T9567) que, quando adicionadas como parâmetros de arranque, podem otimizar o desempenho da replicação de dados através da ligação. Consulte Ativar sinalizadores de rastreamento de inicialização para saber mais.
Utilize commit síncrono com cautela
O modo de commit padrão para a ligação é assíncrono. Embora seja possível alterar o modo de commit para síncrono, não é recomendado nem necessário para proteger contra uma possível perda de dados.
Durante um failover associado planeado, a replicação muda temporariamente para modo síncrono de commit até que o failover seja concluído. Após o failover, o modo de commit volta a ser assíncrono, mesmo que esteja explicitamente definido como modo de commit síncrono antes do failover.
Usar o modo de commit síncrono para a conexão pode impactar o desempenho da sua réplica primária, especialmente se houver elevada latência de rede entre as réplicas. No modo de compromisso síncrono, as transações na réplica primária devem aguardar a confirmação de que os registos de transações estão gravados na réplica secundária antes de a transação poder ser confirmada na réplica primária. Este tempo de espera aumenta com a maior latência da rede, o que pode resultar em tempos mais longos de resposta de transações e numa redução da taxa de transferência na réplica principal.
Conteúdo relacionado
Para usar o link:
- Preparar o ambiente para o link do Managed Instance
- Configurar a ligação entre SQL Server e a Instância Gerida do SQL com SSMS
- Configurar a ligação entre SQL Server e a instância gerida de SQL com scripts
- Redundância do link
- Migrar com o link
- Solucionar problemas com o link
Para saber mais sobre o link:
- Visão geral de link da Instância Gerida
- Recuperação de desastres com Managed Instance link
- Práticas recomendadas para manter o link
Para outros cenários de replicação e migração, considere: