Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O processamento de linguagem natural abrange técnicas que analisam, compreendem e geram linguagem humana a partir de dados textuais. O Azure fornece serviços geridos orientados por API e frameworks distribuídos de código aberto que abordam cargas de trabalho de processamento de linguagem natural que vão desde análise de sentimento e reconhecimento de entidades até classificação de documentos e sumarização de texto. Este guia ajuda-o a avaliar e escolher entre as principais opções de processamento de linguagem natural no Azure, para que possa adaptar a tecnologia certa às suas necessidades de carga de trabalho.
Observação
Este guia foca-se nas capacidades de processamento de linguagem natural disponíveis através de Azure Language e Apache Spark com NLP Spark em Azure Databricks ou Microsoft Fabric. Não fornece orientações sobre como selecionar modelos de linguagem ou desenhar soluções Azure OpenAI. Algumas descrições de plataformas podem referir integrações suportadas com modelos de fundação ou modelos de voz como detalhes de implementação, mas este guia foca-se na seleção de serviços de processamento de linguagem natural. Para mais informações, consulte Escolha uma tecnologia de serviços de IA.
Compreender o processamento de linguagem natural e os modelos de linguagem
Antes de avaliar os serviços do Azure, compreenda o que é o processamento de linguagem natural, como difere dos modelos de linguagem e que tarefas aborda.
Distinguir o processamento de linguagem natural dos modelos de linguagem
Esta secção clarifica a fronteira entre o processamento de linguagem natural e os modelos de linguagem, e faz um resumo das capacidades essenciais que as técnicas de processamento de linguagem natural possibilitam.
| Dimensão | Processamento de linguagem natural | Modelos linguísticos |
|---|---|---|
| Scope | Um campo vasto que abrange diversas técnicas de processamento de texto, incluindo tokenização, stemming, reconhecimento de entidades, análise de sentimento e classificação de documentos. | Um subconjunto de aprendizagem profunda do processamento de linguagem natural focava-se em tarefas de compreensão e geração de linguagem de alto nível. |
| Exemplos | Analisadores baseados em regras, classificadores de frequência de termos-inverso da frequência de documentos (TF-IDF), reconhecedores de entidades mencionadas, analisadores de sentimento. | GPT, BERT e modelos semelhantes baseados em transformadores que geram texto semelhante ao humano, contextualmente consciente. |
| Output | Sinais estruturados como rótulos, escores, intervalos extraídos e sintaxe analisada. | Linguagem natural fluente, como texto gerado, resumos, respostas e conclusões. |
| Relacionamento | O domínio principal. O processamento de linguagem natural abrange todo o espectro de métodos de processamento de texto. | Uma ferramenta dentro do processamento de linguagem natural. Os modelos de linguagem melhoram o processamento da linguagem natural sem o substituir. Eles tratam de tarefas cognitivas mais amplas, mas não são sinónimos de processamento de linguagem natural. |
Capacidades de processamento de linguagem natural
Classifica os documentos rotulando-os como sensíveis ou spam. O processamento de linguagem natural categoriza automaticamente os documentos com base no conteúdo para suportar fluxos de trabalho de conformidade e filtragem.
Resuma o texto identificando entidades no documento. O processamento de linguagem natural extrai entidades-chave para produzir resumos concisos que captam a informação mais importante.
Marque documentos com palavras-chave usando entidades identificadas. Depois de identificar entidades, pode gerar etiquetas-chave que simplificam a organização dos documentos. Use estas etiquetas para pesquisa e recuperação baseada em conteúdo.
Detetar tópicos para navegação e descoberta de documentos relacionados. O processamento de linguagem natural identifica tópicos-chave através do uso de entidades extraídas, o que suporta a categorização de documentos e a navegação baseada em temas.
Avalia o sentimento do texto. A análise de sentimento avalia o tom emocional do texto e classifica o conteúdo como positivo, negativo ou neutro.
Alimente as saídas do processamento de linguagem natural para fluxos de trabalho posteriores. Resultados como entidades extraídas, pontuações de sentimento e rótulos de tópicos servem como entradas para processamento, indexação de pesquisa e análise.
Identificar potenciais casos de uso
Cenários empresariais em muitos setores beneficiam de soluções de processamento de linguagem natural. Os casos de uso seguintes mostram como as técnicas de processamento de linguagem natural enfrentam desafios reais, desde o processamento de documentos não estruturados até à habilitação de aplicações emergentes em cibersegurança e acessibilidade.
Documentos de processo e texto não estruturado
Extrair informações de documentos criados por máquinas. O processamento de linguagem natural permite o processamento de documentos em finanças, saúde, retalho, governo e outros setores. Pode analisar documentos criados digitalmente para extrair informação estruturada a partir de entradas não estruturadas. Para documentos manuscritos, use Azure Document Intelligence para converter conteúdo manuscrito em texto antes de aplicar técnicas de processamento de linguagem natural.
Aplique tarefas de processamento de linguagem natural independentes da indústria para processamento de texto. O reconhecimento de entidades nomeadas (NER), classificação, sumarização e extração de relações ajudam-no a processar e analisar automaticamente o conteúdo não estruturado do documento. Estas tarefas funcionam entre domínios e não requerem personalização específica de cada setor.
Construir modelos específicos de domínio para análises especializadas. Exemplos destas tarefas incluem modelos de estratificação de risco para cuidados de saúde, classificação de ontologias para gestão do conhecimento e resumos de retalho para dados de produtos e clientes. O treino personalizado de modelos em Azure Linguagem e Spark NLP ajuda a melhorar a precisão destes formatos de documento específicos de domínio.
Gerar relatórios automatizados a partir de dados estruturados. Pode sintetizar e gerar relatórios textuais abrangentes a partir de dados estruturados. Esta capacidade ajuda setores como as finanças e a conformidade, que exigem documentação detalhada.
Ativar pesquisa, tradução e análise
Crie grafos de conhecimento e permita a pesquisa semântica através da recuperação de informação. O processamento de linguagem natural suporta a criação de grafos de conhecimento e a pesquisa semântica, o que permite aos sistemas interpretar o significado da consulta em vez de dependerem apenas da correspondência de palavras-chave.
Apoiar a descoberta de medicamentos e os ensaios clínicos com grafos de conhecimento médico. Os sistemas de processamento de linguagem natural analisam texto clínico. Os grafos de conhecimento médico construídos a partir desse texto apoiam os pipelines de descoberta de fármacos e o emparelhamento de ensaios clínicos. Estes gráficos ligam entidades como medicamentos, condições e resultados para acelerar os fluxos de trabalho de investigação. O utilizador pode utilizar text analytics for health em Azure Language para extrair entidades médicas, relações e asserções que pode usar para construir estes gráficos.
Traduzir texto para IA conversacional em aplicações orientadas para o cliente. A tradução de texto permite IA conversacional em múltiplas indústrias. Pode construir aplicações multilingues voltadas para o cliente que processam e respondem na língua preferida do utilizador. O Spark NLP fornece capacidades de tradução diretamente. No Azure, use Azure Translator, que é um serviço separado da Azure Linguagem.
Analise o sentimento e a inteligência emocional para a perceção da marca. A análise de sentimento ajuda-o a monitorizar a perceção da marca e a analisar o feedback dos clientes, revelando sinais emocionais positivos, negativos e nuançados a partir do texto.
Estender o processamento de linguagem natural a domínios emergentes
Construir interfaces ativadas por voz para a Internet das Coisas (IoT) e dispositivos inteligentes. O processamento de linguagem natural trata da saída de texto dos sistemas de reconhecimento de voz para compreender a intenção do utilizador e extrair significado em cenários de IoT e dispositivos inteligentes. Cenários ativados por comando de voz requerem Azure Fala para conversão de voz em texto antes do processamento da linguagem natural.
Ajustar a saída da linguagem dinamicamente usando modelos de linguagem adaptativos. Os modelos de linguagem adaptativos ajustam dinamicamente a saída da linguagem para se adequar a diferentes níveis de compreensão do público, o que apoia a entrega e acessibilidade de conteúdos educativos.
Detetar phishing e desinformação através de análise de texto de cibersegurança. O processamento de linguagem natural analisa os padrões de comunicação e o uso da linguagem em tempo real para identificar potenciais ameaças de segurança na comunicação digital. Esta análise ajuda a detetar tentativas de phishing e campanhas de desinformação.
Avaliar a Linguagem Azure
Azure Language é um serviço baseado na cloud que fornece funcionalidades de processamento de linguagem natural para compreender e analisar texto. Pode aceder através do portal Foundry, APIs REST e bibliotecas de clientes para Python, C#, Java e JavaScript, sem qualquer infraestrutura para gerir. Para o desenvolvimento de agentes de IA, também pode aceder a estas capacidades através do servidor Azure Language Model Context Protocol (MCP). Pode aceder a ela como servidor remoto no catálogo de ferramentas Microsoft Foundry ou como um servidor local auto-hospedado.
Recursos pré-construídos
Funcionalidades pré-construídas não requerem treino de modelos e estão prontas a usar:
NER: Identifica e categoriza entidades em texto em tipos pré-definidos como pessoas, organizações, locais e datas.
Deteção de PII: Identifica e redige informações pessoais identificáveis (PII), incluindo dados pessoais e de saúde sensíveis, em texto e conversas transcritas.
Deteção de linguagem: Deteta a língua de um documento numa vasta gama de línguas e dialetos.
Análise de sentimento e mineração de opinião: Identifica sentimentos positivos, negativos ou neutros no texto e liga opiniões a elementos específicos como atributos do produto ou aspetos do serviço.
Extração de palavras-chave: Avalia texto não estruturado e devolve uma lista de conceitos principais e frases-chave.
Resumo: Condensa documentos e conversas através de abordagens extrativas ou abstratas, que suportam a sumarização por texto, chat e call center.
Análise de texto para a saúde: Extrai e rotula informações de saúde relevantes de texto clínico não estruturado, incluindo entidades médicas, relações e asserções.
Treinar modelos personalizados
Pode usar funcionalidades personalizáveis para treinar modelos nos seus dados para lidar com tarefas específicas de processamento de linguagem natural de domínio:
- Reconhecimento personalizado de entidades nomeadas (CNER): Construir modelos personalizados para extrair categorias de entidades específicas de domínio a partir de texto não estruturado. Usa o CNER quando as categorias NER pré-construídas não cobrem o vocabulário do teu domínio.
Azure Language MCP servidor e agentes
Observação
O servidor MCP do Azure Language Service e os agentes de encaminhamento de intenções, assim como os de resposta exata a perguntas, estão em versão preliminar. As funcionalidades de pré-visualização não incluem um acordo de nível de serviço (SLA), e não as recomendamos para cargas de trabalho em produção. Algumas funcionalidades podem não ser suportadas ou ter capacidades limitadas. Para mais informações, consulte Termos suplementares de utilização para pré-visualizações Microsoft Azure.
O Azure Language fornece agentes pré-construídos e opções flexíveis de implementação para cargas de trabalho de processamento de linguagem natural em produção:
Agente de encaminhamento de intenção: Gere fluxos de conversa. Compreende as intenções do utilizador e os caminhos para respostas precisas através de lógica determinística e auditável. Use este agente quando precisar de um encaminhamento conversacional transparente e determinista.
Agente de resposta exata à pergunta: Fornece respostas fiáveis, palavra por palavra, a questões críticas para o negócio, mantendo a supervisão humana e o controlo de qualidade. Use este agente quando a precisão e consistência da resposta forem essenciais.
Pode aceder a ambos os agentes através do catálogo de ferramentas Foundry. Para mais informações, veja Azure Language MCP server and agents (pré-visualização).
O servidor Azure Language MCP suporta múltiplas opções de implementação:
Servidor MCP alojado remotamente na cloud: O catálogo de ferramentas Foundry lista este servidor. O servidor fornece acesso gerido na cloud às capacidades do Azure Language e não requer infraestrutura local.
Servidor MCP local auto-hospedado: Suporta implementações on-premises ou autogeridas para requisitos de conformidade, segurança ou residência de dados.
Implementação contentorizada: As seguintes funcionalidades suportam a implementação contentorizada para cenários que requerem processamento local ou ambientes isolados. Para a lista completa de contentores disponíveis e o seu estado de disponibilidade, veja Azure suporte a contentores de IA.
- Análise de sentimentos
- Deteção de idioma
- Extração de expressões-chave
- NER
- Deteção de PII
- CNER
- Análise de texto para cuidados de saúde
- Resumo (pré-visualização)
Avalie o Apache Spark com o Spark NLP
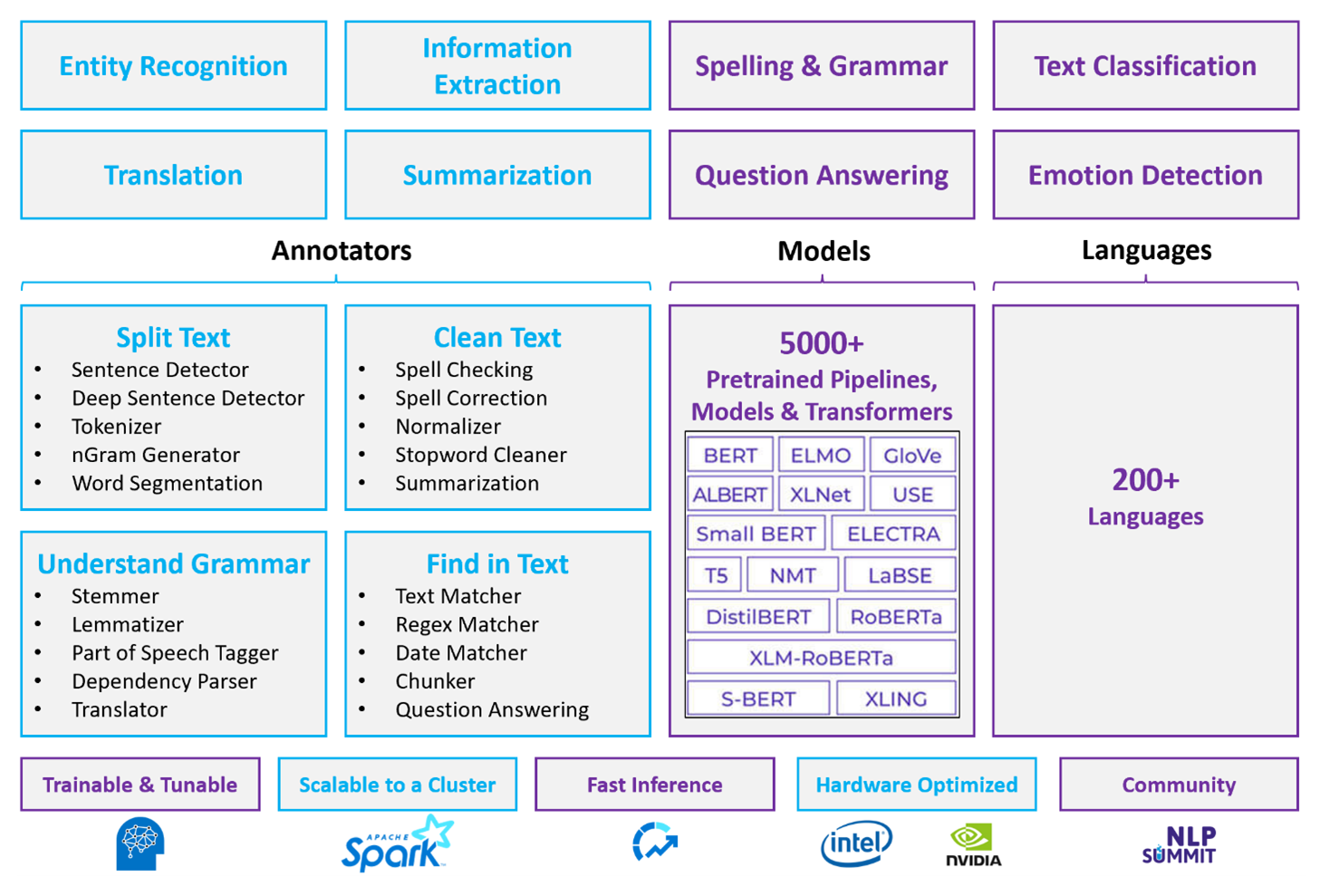
O Apache Spark com Spark NLP é uma abordagem distribuída e de código aberto ao processamento de linguagem natural que opera à escala de cluster. A arquitetura da plataforma NLP Spark, o desempenho e o ecossistema de modelos pré-construídos tornam-na uma opção forte para cargas de trabalho de processamento de linguagem natural personalizáveis em grande escala em Azure Databricks ou Fabric.
Compreender a plataforma e a arquitetura
Recomendamos que utilize Fabric ou Azure Databricks para cargas de trabalho de processamento de linguagem natural baseadas no Apache Spark.
O Apache Spark fornece processamento paralelo em memória para análise de big data. O Fabric e o Azure Databricks dão-lhe acesso a capacidades de processamento do Apache Spark para cargas de trabalho de processamento em linguagem natural em grande escala.
O Spark NLP funciona como uma extensão nativa do Spark ML em dataframes. Esta integração permite processos unificados de linguagem natural e aprendizagem automática com melhor desempenho em clusters distribuídos.
Spark NLP é uma biblioteca open-source com suporte para Python, Java e Scala. A biblioteca oferece funcionalidades comparáveis ao spaCy e ao Natural Language Toolkit (NLTK), incluindo verificação ortográfica, análise de sentimento e classificação de documentos.

Apache®, Apache Spark e o logótipo da chama são marcas registadas ou marcas da Apache Software Foundation no United States e/ou noutros países. Nenhum endosso da Apache Software Foundation está implícito no uso dessas marcas.
Avaliar o desempenho e a escalabilidade
Os benchmarks públicos mostram melhorias significativas de velocidade em relação a outras bibliotecas de processamento de linguagem natural. Comparado com frameworks como spaCy e NLTK, o Spark NLP demonstra treino e inferência mais rápidos em clusters distribuídos. Modelos personalizados treinados pelo Spark NLP atingem níveis de precisão que correspondem aos de outros frameworks de processamento de linguagem natural, o que o torna adequado para cargas de trabalho de produção que exigem rapidez e precisão.
Compilações otimizadas para CPUs, GPUs e chips Intel Xeon utilizam totalmente clusters Apache Spark. Estas builds permitem que o treino e a inferência escalem de forma eficiente entre nós de cluster.
Os embeddings MPNet e o suporte ONNX permitem um processamento preciso e consciente do contexto. O MPNet produz representações vetoriais densas que captam significado semântico, e o suporte ao ONNX permite importar e executar modelos otimizados para inferência.
Use modelos e pipelines pré-construídos
Modelos pré-construídos de aprendizagem profunda tratam de NER, classificação de documentos e deteção de sentimento. A biblioteca vem com modelos pré-construídos de aprendizagem profunda.
Modelos de linguagem pré-treinados suportam embeddings de palavras, blocos, frases e documentos. A biblioteca inclui modelos de linguagem pré-treinados que suportam níveis de incorporação de palavras, segmentos, frases e documentos. Estas incorporações fornecem representações vetoriais densas que permitem tarefas a jusante como pesquisa por similaridade e classificação.
Pipelines unificados de processamento de linguagem natural e aprendizagem automática suportam a previsão de riscos e a classificação de documentos. A integração com o Spark ML suporta processamento unificado de linguagem natural e pipelines de aprendizagem automática para tarefas como classificação de documentos e previsão de risco. Com esta abordagem unificada, pode combinar o processamento de texto com modelos tradicionais de aprendizagem automática num único pipeline, o que reduz a complexidade arquitetónica.
Abordar desafios comuns no processamento de linguagem natural
Tanto Azure Language como Apache Spark com NLP Spark enfrentam desafios comuns no processamento de linguagem natural em larga escala. Se compreenderes estes desafios, podes planear recursos, desenhar pipelines e definir expectativas de precisão antes de te comprometeres com qualquer uma das opções.
Processamento de recursos
O processamento de texto livre requer recursos computacionais e tempo significativos. Documentos de texto livre são computacionalmente dispendiosos e demorados de analisar. Cada documento requer tokenização, normalização e inferência de modelos antes de produzir resultados utilizáveis.
As cargas de trabalho NLP do Spark frequentemente exigem a implementação de computação por GPU. Para pipelines de NLP Spark em grande escala, clusters acelerados por GPU em Azure Databricks ou Fabric fornecem o poder de processamento paralelo necessário para treino e inferência. Otimizações como a quantização do modelo Llama 3.x ajudam a reduzir o consumo de memória e a melhorar o rendimento para estas tarefas intensivas.
O Azure Language requer planeamento de throughput e gestão de quotas. O serviço gere recursos, mas chamadas de API de alto volume exigem um planeamento cuidadoso do rendimento. Monitorize as suas taxas de pedido em relação aos limites de serviço e limites de taxa para evitar limitações e garantir um desempenho de processamento consistente.
Padronização de documentos
Documentos do mundo real raramente seguem uma estrutura consistente. Esta inconsistência cria desafios para as condutas de extração e requer estratégias deliberadas para manter a precisão entre fontes.
Formatos inconsistentes: Sem um formato de documento padronizado, extrair factos específicos de texto livre pode ser difícil. Por exemplo, pode ser um desafio extrair números de fatura e datas de diferentes fornecedores porque os layouts dos campos, etiquetas e formatação variam entre fontes.
Custom model training: Quando treina modelos personalizados em Spark NLP e Azure Language, pode adaptar-se a formatos de documentos específicos de domínio. Quando treina com amostras representativas dos seus documentos reais, pode melhorar a precisão da extração para campos, entidades e padrões que modelos pré-construídos não lidam bem.
Variedade e complexidade dos dados
Estruturas documentais diversas e nuances linguísticas acrescentam complexidade. Os dados de texto do mundo real existem em muitos formatos, estilos de escrita e línguas. Para resolver estas variações, requer modelos que consigam lidar com ambiguidade, gírias, abreviaturas e terminologia específica do domínio, mantendo a precisão.
Os embeddings MPNet no Spark NLP proporcionam uma compreensão contextual aprimorada. Os embeddings MPNet captam relações contextuais entre palavras e frases, o que ajuda os pipelines de NLP do Spark a lidar com textos nuançados de forma mais eficaz. Estas incorporações produzem representações vetoriais densas que preservam o significado semântico entre diferentes formatos de documentos.
Modelos personalizados no Azure Language adaptam-se a padrões de texto específicos do domínio. Com o CNER pode treinar modelos com dados rotulados próprios para reconhecer padrões específicos do seu domínio. Esta abordagem melhora a fiabilidade ao ensinar o modelo a reconhecer entidades e categorias que os modelos pré-definidos não reconhecem.
Aplicar critérios-chave de seleção
Use os seguintes critérios para determinar qual a opção de processamento de linguagem natural do Azure que melhor se adequa às suas necessidades. Cada critério descreve uma característica da carga de trabalho e identifica o serviço que a aborda.
Capacidades geridas de processamento de linguagem natural: Utilizar APIs Azure Language para reconhecimento de entidades, identificação de intenções, deteção de tópicos ou análise de sentimento. Estas capacidades estão disponíveis como serviços geridos com configuração mínima, e não precisa de provisionar ou gerir qualquer infraestrutura.
Modelos pré-construídos ou pré-treinados: Use Azure Linguagem se planeia usar modelos pré-construídos ou pré-treinados sem gerir a infraestrutura. Esta abordagem adequa-se a conjuntos de dados pequenos a médios e a tarefas padrão de processamento de linguagem natural, onde modelos pré-construídos fornecem precisão suficiente. Oferece a escalabilidade automática, segurança integrada e preços de pagamento por chamada sem a sobrecarga de gestão de clusters.
Treino personalizado de modelos em grandes conjuntos de dados de texto: Use Azure Databricks ou Fabric com Spark NLP. Estas plataformas proporcionam o poder computacional e a flexibilidade necessárias para um treino extensivo de modelos em grandes conjuntos de dados textuais. Também pode descarregar modelos através do Spark NLP, incluindo Llama 3.x e MPNet.
Primitivas de processamento de linguagem natural de baixo nível: Use Azure Databricks ou Fabric com Spark NLP para tokenização, stemming, lematização e TF-IDF. Em alternativa, usa uma biblioteca open-source como spaCy ou NLTK. A Linguagem Azure no Foundry Tools utiliza a tokenização interna como parte do seu pipeline de modelos, mas não expõe estes passos como APIs autónomas e controláveis.
Construção de pipelines de processamento de linguagem natural usando Spark NLP
O NLP do Spark segue o mesmo padrão de desenvolvimento dos modelos tradicionais de ML do Spark quando se executa um pipeline de processamento de linguagem natural. Geres modelos treinados usando MLflow para acompanhamento de experiências e implementação em produção.

Montar componentes principais do pipeline
O pipeline do Spark NLP encadeia anotadores em sequência. Cada anotador transforma a saída da etapa anterior e constrói desde o texto bruto até vetores semânticos.
O DocumentAssembler é o ponto de entrada para cada pipeline de NLP do Spark. Use
setCleanupModepara aplicar o pré-processamento opcional de texto, como remoção de etiquetas HTML ou normalização de espaços em branco, antes que os anotadores posteriores sejam executados.O SentenceDetector identifica os limites das sentenças no documento reunido. Devolve frases detetadas dentro
Arrayde uma única linha ou como linhas separadas, dependendo da configuração do pipeline. A deteção precisa de frases é importante porque muitos anotadores posteriores operam ao nível da frase.O tokenizer divide o texto bruto em tokens discretos como palavras, números e símbolos. Se as regras padrão forem insuficientes para o seu domínio, adicione regras personalizadas para lidar com vocabulário especializado, termos com hífens ou padrões específicos do domínio.
O normalizador refina tokens aplicando expressões regulares e transformações de dicionário. Limpa o texto para reduzir o ruído antes de o incorporar. Por exemplo, pode remover acentos, converter para minúsculas ou aplicar mapeamentos personalizados de dicionário para padronizar a terminologia.
WordEmbeddings mapeiam tokens para vetores semânticos, permitindo processamento contextual. Cada token é representado como um vetor denso que capta o seu significado em relação a outros tokens. Tokens não resolvidos que não aparecem no vocabulário de embeddings são, por defeito, vetores zero.
Gerir modelos utilizando MLflow
O Spark NLP utiliza pipelines do Spark MLlib com suporte nativo ao MLflow. Não precisas de escrever código personalizado de serialização ou integração.
O MLflow gere o acompanhamento de experiências, a versão de modelos e a implementação. Podes registar parâmetros do pipeline, métricas e artefactos durante as execuções de treino. O MLflow acompanha cada experiência, por isso podes comparar resultados entre iterações e reproduzir configurações bem-sucedidas.
O MLflow integra-se diretamente com Azure Databricks e Fabric. No Azure Databricks, o MLflow vem pré-instalado e integra-se de forma estreita com o espaço de trabalho. Fabric também oferece uma experiência MLflow incorporada com acompanhamento nativo de experiências e autologging, por isso não precisa de instalar o MLflow separadamente. Se correr o Spark NLP noutro ambiente baseado no Apache Spark, pode instalar o MLflow separadamente e configurá-lo para rastrear experiências contra um servidor de rastreio remoto.
Utilize o MLflow Model Registry para promover modelos na produção e manter a governação. O Registo de Modelos fornece um repositório central para gerir as versões dos modelos ao longo dos seus pipelines de processamento de linguagem natural. Nas implementações clássicas, os modelos são transicionados através de etapas como preparação, produção e arquivado. No Azure Databricks, as implementações mais recentes utilizam Models no Unity Catalog, que substitui os estágios fixos por aliases e tags personalizados para uma gestão do ciclo de vida mais flexível. No Fabric, o espaço de trabalho fornece o seu próprio registo de modelos baseado em MLflow.
Matriz de capacidades
As tabelas seguintes resumem as principais diferenças de capacidades entre o Spark NLP no Azure Databricks ou o Fabric e o Azure Language.
Capacidades gerais
| Capacidade | Spark NLP (Azure Databricks ou Fabric) | Azure Language |
|---|---|---|
| Modelos pré-treinados como serviço | Sim | Sim |
| API REST | Sim | Sim |
| Programabilidade | Python, Scala | Ver Linguagens de programação suportadas. |
| Suporta o processamento de grandes conjuntos de dados e documentos grandes | Sim | Limitado 1 |
1.Azure A linguagem tem limites de tamanho de documento por pedido que variam consoante o modo. Pedidos síncronos suportam até 5.120 caracteres por documento, e pedidos assíncronos suportam até 125.000 caracteres por documento. Ambos os modos suportam até 25 documentos por chamada API. Pode processar grandes volumes de conjuntos de dados através de lote e paginação, mas documentos individuais que excedam o limite de caracteres para o modo escolhido exigem fragmentação. Para mais informações, consulte Limites de dados e taxa para Azure Linguagem.
Recursos do anotador
| Capacidade | Spark NLP (Azure Databricks ou Fabric) | Azure Language |
|---|---|---|
| Detetor de orações | Sim | Não |
| Detetor de frases profundas | Sim | Não |
| Tokenizador | Sim | Apenas interno (não exposto como API autónoma) |
| Gerador de N-gramas | Sim | Não |
| Segmentação de Word | Sim | Sim |
| Stemmer (Algoritmo de radicalização) | Sim | Não |
| Lemmatizador | Sim | Não |
| Etiquetagem de categorias gramaticais | Sim | Não |
| Analisador de dependência | Sim | Não |
| Tradução | Sim | Não |
| Limpador de palavras paradas | Sim | Não |
| Correção ortográfica | Sim | Não |
| Normalizador | Sim | Sim |
| Comparador de texto | Sim | Não |
| TF-IDF | Sim | Não |
| Verificador de expressão regular | Sim | Limitada |
| Correspondente de data | Sim | Limitada |
| Fragmento | Sim | Não |
Recursos de processamento de linguagem natural de alto nível
| Capacidade | Spark NLP (Azure Databricks ou Fabric) | Azure Language |
|---|---|---|
| Verificação de ortografia | Sim | Não |
| Sumarização | Sim | Sim |
| Perguntas e respostas | Sim | Sim |
| Deteção de sentimentos | Sim | Sim |
| Deteção de emoções | Sim | Limited 2 |
| Classificação de tokens | Sim | Limitado 3 |
| Classificação de texto | Sim | Limitado 3 |
| Representação de texto | Sim | Não |
| NER | Sim | Sim (pré-montado). O CNER está disponível em modelos personalizados. 3 |
| Deteção de idioma | Sim | Sim |
| Suporta línguas que não o inglês | Yes. Veja linguagens suportadas por NLP Spark. | Yes. Veja Idiomas suportados pelo Azure. |
2.Azure A linguagem suporta a mineração de opinião, que identifica sentimentos ligados a aspetos específicos do texto, mas não fornece deteção dedicada de emoções (como classificação de alegria, raiva ou tristeza).
3.Disponível através de modelos personalizados. Pode treinar modelos de reconhecimento de entidades CNER ou personalizados com os seus próprios dados rotulados.
Contribuidores
A Microsoft mantém este artigo. Os seguintes colaboradores escreveram este artigo.
Principais autores:
- Ananya Ghosh Chowdhury | Arquiteto Principal de Soluções Cloud
- Kranthi Manchikanti | Engenheiro Sénior de Soluções de IA
Outros contribuidores:
- Freddy Ayala | Arquiteto de Soluções em Nuvem
- Tincy Elias | Arquiteto de Soluções de Nuvem Senior
- Moritz Steller | Arquiteto de Soluções Cloud Senior
Para ver perfis de LinkedIn não públicos, inicie sessão no LinkedIn.
Próximos passos
- Introdução à IA em Azure
- Desenvolva soluções de processamento de linguagem natural utilizando as ferramentas Foundry
Recursos relacionados
Documentação do Azure Language:
Documentação do Spark NLP:
Componentes do Azure:
Saiba mais sobre os recursos: