Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Esta página explica como se conectar a um sql warehouse, procurar arquivos e dados e gravar consultas no novo editor de SQL do Databricks.
Conectar-se à computação
Você deve ter pelo menos permissões CAN USE em um sql warehouse para executar consultas. Você pode usar o menu suspenso perto da parte superior do editor para ver as opções disponíveis. Para filtrar a lista, insira o texto na caixa de pesquisa.
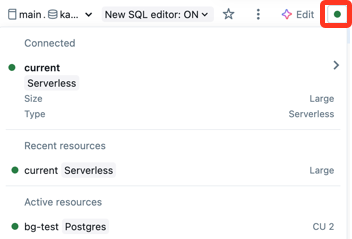
Se você tiver um SQL Warehouse padrão, o editor do SQL o usará automaticamente ao criar uma consulta. Se nenhum armazém padrão estiver definido, você selecionará em uma lista alfabética de armazéns disponíveis. As consultas subsequentes usam o último warehouse selecionado. Para definir um warehouse padrão, consulte Definir um warehouse padrão no nível do usuário.
O ícone ao lado do SQL warehouse indica o status:
- Executando

- Parado
Note
Se não houver SQL warehouses na lista, entre em contato com o administrador do workspace.
O SQL warehouse selecionado será reiniciado automaticamente quando você executar a consulta. Consulte Iniciar um SQL warehouse para conhecer outras maneira de iniciar um SQL warehouse.
Procurar ativos e obter ajuda
Use o painel esquerdo no editor do SQL para localizar arquivos de workspace, exibir objetos de dados e obter ajuda do Genie Code.
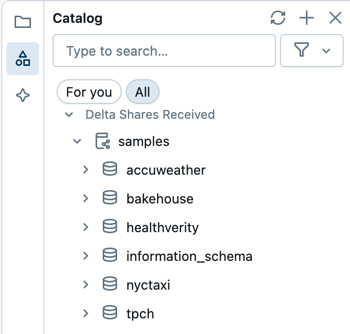
Procurar arquivos do espaço de trabalho
Clique no ![]() no ícone da pasta para abrir a pasta de usuário do workspace. Você pode acessar todos os arquivos de workspace aos quais tem acesso nesta parte da interface do usuário.
no ícone da pasta para abrir a pasta de usuário do workspace. Você pode acessar todos os arquivos de workspace aos quais tem acesso nesta parte da interface do usuário.
Procurar objetos de dados
Se você tiver a permissão de leitura de metadados, o navegador de esquema no Editor SQL exibirá os bancos de dados e as tabelas disponíveis. Você também pode procurar objetos de dados no Explorador do Catálogo.
Você pode navegar pelos objetos de banco de dados controlados pelo Catálogo do Unity no Explorador de Catálogos sem computação ativa. Para explorar dados no hive_metastore e em outros catálogos não regidos pelo Catálogo do Unity, você deve anexar à computação com privilégios apropriados. Consulte a governança de dados com Azure Databricks.
Note
Se nenhum objeto de dados existir no navegador de esquema ou no Explorador do Catálogo, entre em contato com o administrador do workspace.
Clique em ![]() próximo à parte superior do navegador de esquema para atualizar o esquema. Você pode inserir texto na barra de pesquisa para filtrar ativos por nome. Clique no
próximo à parte superior do navegador de esquema para atualizar o esquema. Você pode inserir texto na barra de pesquisa para filtrar ativos por nome. Clique no ![]() filtre o ícone para filtrar objetos por tipo.
filtre o ícone para filtrar objetos por tipo.
Clique no nome de um objeto no navegador para ver mais detalhes sobre o objeto. Por exemplo, clique em um nome de esquema para mostrar as tabelas nesse esquema. Clique em um nome de tabela para mostrar as colunas nessa tabela.
Obter ajuda do Genie Code
Clique ![]() Clique no
Clique no ![]() para abrir uma janela de chat com o Genie Code. Clique em uma pergunta sugerida ou insira sua própria pergunta para interagir com o Genie Code.
para abrir uma janela de chat com o Genie Code. Clique em uma pergunta sugerida ou insira sua própria pergunta para interagir com o Genie Code.
Criar uma consulta
Você pode inserir texto para criar uma consulta no Editor SQL. Você pode inserir elementos do navegador de esquema para referenciar catálogos e tabelas.
Insira sua consulta no editor do SQL.
O Editor SQL dá suporte ao preenchimento automático. Conforme você digita, o preenchimento automático sugere preenchimentos. Por exemplo, se um preenchimento válido no local do cursor é uma coluna, o preenchimento automático sugere um nome de coluna. Se você digita
select * from table_name as t where t., o preenchimento automático reconhece queté um alias detable_namee sugere as colunas dentro detable_name. Você também pode usar o preenchimento automático para referenciar fragmentos de consulta.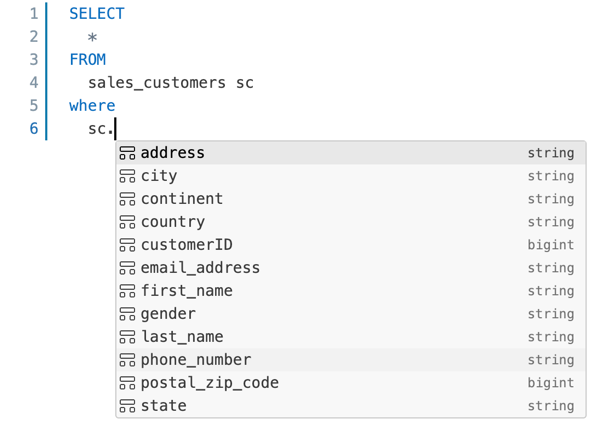
(Opcional) Quando terminar a edição, clique em Salvar. Por padrão, a consulta é salva na pasta Home do usuário. Para salvar a consulta em um local diferente, selecione a pasta de destino e clique em Mover.
Note
Novas consultas são automaticamente nomeadas Nova consulta com o carimbo de data/hora de criação acrescentado no título. Por padrão, novas consultas criadas sem um contexto de pasta específico são criadas na pasta Rascunhos em seu diretório base. Quando novas consultas são salvas ou renomeadas, elas são removidas de Rascunhos.
Consulta de fontes de dados
Você pode identificar uma fonte de consulta usando um nome de tabela totalmente qualificado na própria consulta ou selecionando uma combinação de catálogo e esquema dos seletores suspensos, juntamente com o nome da tabela na consulta. Um nome de tabela totalmente qualificado na consulta substitui os seletores de catálogo e esquema no editor do SQL. Se um nome de tabela ou coluna incluir espaços, encapsule esses identificadores em backticks em suas consultas SQL.
Note
O número máximo de resultados retornados em uma tabela é de 64.000 linhas ou 10 MB, o que for menor.
Os exemplos a seguir demonstram como consultar vários objetos semelhantes a tabelas que você pode armazenar em um catálogo.
Consultar uma tabela ou exibição padrão
O exemplo a seguir consulta uma tabela do samples catálogo.
SELECT
o_orderdate,
o_orderkey,
o_custkey,
o_totalprice,
o_shippriority
FROM
samples.tpch.orders
Consultar uma visualização de métrica
O exemplo a seguir consulta uma exibição de métrica que usa uma tabela do catálogo de exemplos como sua origem. Ele avalia as três medidas listadas e agrega sobre Order Month e Order Status. Ele retorna resultados classificados por Order Month. Para criar uma exibição de métrica semelhante em seu workspace, consulte Tutorial: Criar uma exibição de métrica completa com junções.
Todas as avaliações de medida devem ser encapsuladas na função MEASURE. Consulte measure a função de agregação.
SELECT
`Order Month`,
`Order Status`,
MEASURE(`Order Count`),
MEASURE(`Total Revenue`),
MEASURE(`Total Revenue per Customer`)
FROM
orders_metric_view
GROUP BY ALL
ORDER BY 1 ASC;
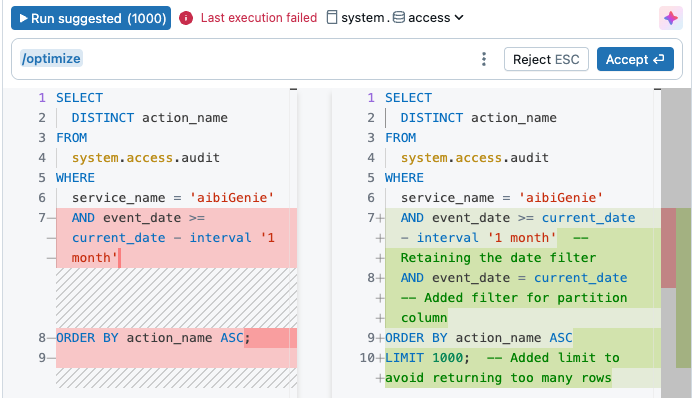
Otimizar uma consulta com o Genie Code
Clique no ![]() no lado direito do editor para obter ajuda embutida e sugestões ao escrever consultas. O
no lado direito do editor para obter ajuda embutida e sugestões ao escrever consultas. O /optimize comando de barra solicita que o Assistente avalie e otimize consultas. Para obter mais informações, consulte Otimizar Python, PySpark e código SQL.
Editar várias abas de consulta
Por padrão, o editor do SQL usa guias para que você possa abrir e editar várias consultas simultaneamente. Para abrir uma nova guia, clique em + e escolha Criar nova consulta ou Abrir consulta existente. Clique em Abrir consulta existente para ver uma lista de consultas. A aba For you oferece uma lista curada de sugestões com base em seus padrões de uso. Use a guia Todos para localizar qualquer consulta à qual você tenha acesso.

Salvar uma consulta
O conteúdo da consulta no novo editor SQL é salvo automaticamente continuamente. O botão Salvar controla se o conteúdo da consulta de rascunho deve ser aplicado a ativos relacionados, como fluxos de trabalho ou alertas herdados. Se a consulta for compartilhada com a credencial Executar como proprietário, somente o proprietário da consulta poderá usar o botão Salvar para propagar as alterações. Se a credencial estiver definida como Executar como visualizador, qualquer usuário com pelo menos CAN MANAGE permissão poderá salvar a consulta.
Controle do código-fonte de uma consulta
Os arquivos de consulta SQL do Databricks (extensão: .dbquery.ipynb) têm suporte em pastas Git do Databricks. Você pode usar uma pasta Git para controlar os arquivos de consulta e compartilhá-los em outros workspaces com pastas Git que acessam o mesmo repositório Git. Se você optar por não usar o novo editor de SQL depois de confirmar ou clonar uma consulta em uma pasta Git do Databricks, exclua e reclone essa pasta Git para evitar comportamentos inesperados.