Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
A memória permite que os agentes de IA lembrem-se de informações anteriores na conversa ou de conversas anteriores. Isso permite que os agentes forneçam respostas com reconhecimento de contexto e criem experiências personalizadas ao longo do tempo. Use o Databricks Lakebase, um banco de dados OLTP do Postgres totalmente gerenciado, para gerenciar o estado e o histórico da conversa.
Requirements
- Habilite os Aplicativos do Databricks em seu workspace. Consulte Configurar seu ambiente de desenvolvimento e workspace do Databricks Apps.
- Uma instância do Lakebase, consulte Criar e gerenciar uma instância de banco de dados.
Memória de curto prazo versus de longo prazo
A memória de curto prazo captura o contexto em uma única sessão de conversa, enquanto a memória de longo prazo extrai e armazena informações importantes em várias conversas. Você pode criar seu agente com um ou ambos os tipos de memória.
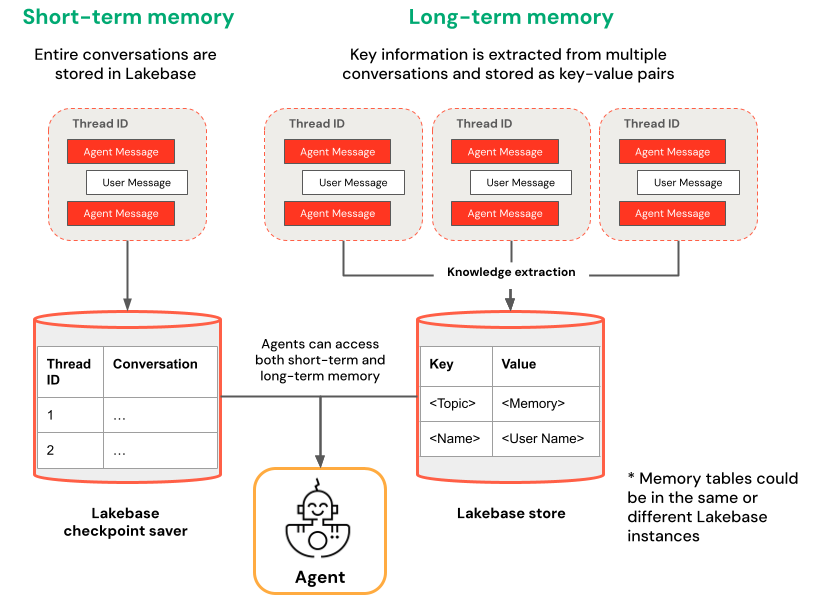
| Memória de curto prazo | Memória de longo prazo |
|---|---|
| Capturar o contexto em uma única sessão de conversa usando IDs de thread e ponto de verificação Manter o contexto para perguntas de acompanhamento em uma sessão |
Extrair e armazenar automaticamente os principais insights em várias sessões Personalizar interações com base em preferências passadas Criar uma base de dados de conhecimento sobre usuários que melhoram as respostas ao longo do tempo |
Introdução
Para criar um agente com memória nos Aplicativos do Databricks, clone um modelo de aplicativo predefinido e siga o fluxo de trabalho de desenvolvimento descrito em Criar um agente de IA e implantá-lo em Aplicativos. Os modelos a seguir demonstram como adicionar memória de curto e longo prazo aos agentes que usam estruturas populares.
LangGraph
Clone o template agent-langgraph-avançado para criar um agente LangGraph com memória de curto e longo prazo. O template usa o checkpointing interno do LangGraph com o Lakebase para gerenciamento de estado durável, incluindo contexto de conversa com base em threads e insights persistentes do usuário entre sessões.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-langgraph-advanced
SDK de Agentes do OpenAI
Clone o modelo agent-openai-avançado para criar um agente usando o SDK de Agentes OpenAI com memória de curto prazo. O template usa o Lakebase para gerenciamento de estado durável, permitindo conversas com múltiplos turnos com manutenção de estado e gerenciamento automático do histórico de conversas.
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-advanced
Execução em segundo plano para agentes de longa duração
Os Aplicativos do Databricks impõem um tempo limite de conexão HTTP de aproximadamente 300 segundos. A execução em segundo plano permite que as tarefas do agente que excedem esse limite continuem em execução após o fechamento da conexão; o cliente recupera os resultados de um ponto de extremidade separado ou se reconecta para retomar o streaming.
Os modelos avançados — agent-langgraph-advanced e agent-openai-advanced — estendem os modelos base com memória de curto prazo e execução em segundo plano de longa duração por meio do LongRunningAgentServer de databricks-ai-bridge, que fornece:
-
Modo de plano de fundo: defina
background=trueno corpo da solicitação para retornar uma ID de resposta imediatamente e executar o agente de forma assíncrona. -
Recuperar ponto de extremidade: enviar
GET /responses/{id}para buscar o resultado final ou para abrir uma conexão de streaming para uma execução em andamento. -
Streaming retomável: cada evento enviado pelo servidor inclui um
sequence_number. Se a conexão cair, reconecte-se comstarting_after=Npara retomar do próximo evento. - TASK_TIMEOUT_SECONDS Variável de ambiente que limita a duração da tarefa em segundo plano. Isso é independente do tempo limite de conexão HTTP do Databricks Apps de 120 segundos, que se aplica apenas a uma única solicitação HTTP. (padrão: 1 hora)
O modelo avançado README mostra exemplos de solicitação para cinco modos de cliente:
- Invocação: um POST padrão sem streaming.
- Stream: um POST de streaming padrão.
-
Fundo, em seguida, consulta: POST com
background=true, em seguida, consulteGET /responses/{id}até concluir. -
Streaming em segundo plano, retomar via stream: POST com
background=trueestream=true; se a conexão cair, reconecte-se aGET /responses/{id}comstream=true. -
Streaming em segundo plano, retomar via votação: Mesmo pontapé inicial; se a conexão cair, pesquise
GET /responses/{id}o resultado final.
Implantar e consultar seu agente
Depois de configurar seu agente com memória, siga as etapas em Criar um agente de IA e implante-o em Aplicativos para executar seu agente localmente, avaliá-lo e implantá-lo nos Aplicativos do Databricks.