Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Databasespiegeling in Microsoft Fabric is een cloudgebaseerde SaaS-technologie zonder ETL, bedoeld voor ondernemingen. Deze handleiding helpt u bij het opzetten van een gespiegelde database van Azure Databricks, waarmee een alleen-lezen, continu gerepliceerde kopie van uw Azure Databricks-gegevens in OneLake wordt gemaakt.
Vereiste voorwaarden
- Een Fabric-werkruimte.
- Externe gegevenstoegang inschakelen in de metastore. Zie Externe gegevenstoegang inschakelen in de metastore voor meer informatie.
- Maak of gebruik een bestaande Azure Databricks-werkruimte waarvoor Unity Catalog is ingeschakeld.
- De
EXTERNAL USE SCHEMA-bevoegdheid voor het schema in Unity Catalog hebben die de tabellen bevat waartoe Fabric toegang heeft. - Gebruik het machtigingsmodel van Fabric om toegangsbeheer in te stellen voor catalogi, schema's en tabellen in Fabric.
Een gespiegelde database maken vanuit Azure Databricks
Volg deze stappen om een nieuwe gespiegelde database te maken vanuit uw Azure Databricks Unity-catalogus.
Ga naar uw werkruimte in Fabric.
Selecteer Nieuw item>Gespiegelde Azure Databricks-catalogus.

Selecteer een bestaande verbinding als u er een hebt geconfigureerd of maak een nieuwe verbinding.
Als u een verbinding wilt maken, moet u een gebruiker of beheerder van de Azure Databricks-werkruimte zijn. U kunt zich verifiëren bij uw Azure Databricks-werkruimte met behulp van Organizational-account of Service-principal verificatie.
Note
De verificatiekeuze die u hier maakt, is van toepassing op Databricks-verificatie en Unity Catalog-autorisatie. Als u toegang nodig hebt tot Azure Data Lake Storage (ADLS) Gen2-accounts achter een firewall, volgt u verderop in dit artikel de stappen om toegang via netwerkbeveiliging voor uw Azure Data Lake Storage Gen2-account in te schakelen. Wanneer ADLS Gen2 zich achter een firewall bevindt, is Fabric werkruimte-id vereist voor toegang tot de opslagfirewall, ongeacht de verificatiemethode die is gekozen voor de Databricks-verbinding.
Nadat u verbinding hebt gemaakt met een Azure Databricks-werkruimte, selecteert u op de pagina Choose tabellen uit een Databricks-catalogus de catalogus, schema's en tabellen die u wilt toevoegen en openen vanuit Fabric met behulp van de opname- of uitsluitingslijst. Kies de catalogus en de bijbehorende schema's en tabellen die u wilt toevoegen aan uw Fabric-werkruimte.
U kunt alleen de catalogi, schema's en tabellen zien waartoe u toegang hebt. Zie Unity Catalog-bevoegdheden en beveiligbare objecten voor meer informatie.
Standaard is de optie Voor het automatisch synchroniseren van toekomstige cataloguswijzigingen voor de geselecteerde schemaoptie ingeschakeld. Zie Mirroring Azure Databricks > Metadata sync voor meer informatie.
Selecteer Volgende om door te gaan.
Controleer op de pagina Controleren en maken de details en wijzig desgewenst de naam van het gespiegelde database-item, die uniek moet zijn in uw werkruimte. Standaard is de naam van het gespiegelde item de naam van de catalogus.
Selecteer Maken om door te gaan.
Er wordt een Databricks-catalogusitem gemaakt en voor elke tabel wordt ook een snelkoppeling naar het bijbehorende Databricks-type gemaakt.
Schema's zonder tabellen worden niet weergegeven.
U kunt ook een voorbeeld van de gegevens bekijken wanneer u een snelkoppeling opent door het SQL Analytics-eindpunt te selecteren. Open het eindpuntitem van SQL Analytics om de pagina Explorer en queryeditor te starten. U kunt een query uitvoeren op uw gespiegelde Azure Databricks tabellen met behulp van T-SQL in de SQL-editor.
Lakehouse-snelkoppelingen maken naar het Databricks-catalogusonderdeel
U kunt ook snelkoppelingen maken van uw Lakehouse naar uw Databricks-catalogusitem om uw Lakehouse-gegevens te gebruiken en Spark Notebooks te gebruiken.
- Maak eerst een lakehouse. Als u al een lakehouse in deze werkomgeving heeft, kunt u een bestaand lakehouse gebruiken.
- Selecteer uw werkruimte in het navigatiemenu.
- Selecteer + Nieuw>Lakehouse.
- Geef een naam op voor uw lakehouse in het veld Naam en selecteer Maken.
- In de verkennerweergave van uw lakehouse, selecteer in het menu Gegevens ophalen voor uw lakehouse, onder Gegevens in uw lakehouse laden, de knop Nieuwe snelkoppeling.
- Selecteer Microsoft OneLake. Selecteer een catalogus. Dit is het gegevensitem dat u in de vorige stappen hebt gemaakt. Klik daarna op Volgende.
- Selecteer tabellen in het schema en selecteer Volgende.
- Klik op Creëren.
- In uw Lakehouse zijn nu snelkoppelingen beschikbaar voor gebruik met de andere gegevens van uw Lakehouse. U kunt notebooks en Spark ook gebruiken om gegevensverwerking uit te voeren op de gegevens voor deze catalogustabellen die u hebt toegevoegd vanuit uw Azure Databricks-werkruimte.
Een semantisch model maken
U kunt een Power BI semantisch model maken op basis van uw gespiegelde item en tabellen handmatig toevoegen of verwijderen. Zie Een semantisch Power BI-model maken voor meer informatie over het maken en beheren van semantische modellen.
Gebruik de Microsoft Edge browser voor semantische modelleringstaken voor de beste ervaring.
Beheer uw semantische modelrelaties
Nadat u een nieuw semantisch model hebt gemaakt op basis van uw gespiegelde database, configureert u de relaties tussen tabellen.
- Selecteer Modelindelingen in de Verkenner in uw werkruimte.
- Zodra u Modelindelingen hebt geselecteerd, ziet u een afbeelding van de tabellen die zijn opgenomen als onderdeel van het semantische model.
- Als u relaties tussen tabellen wilt maken, sleept u een kolomnaam van de ene tabel naar de andere kolomnaam van een andere tabel. Er verschijnt een pop-up om de relatie en kardinaliteit voor de tabellen te identificeren.
Netwerkbeveiligingstoegang inschakelen voor uw Azure Data Lake Storage Gen2-account
Configureer netwerkbeveiliging voor uw ADLS Gen2-account (Azure Data Lake Storage) wanneer u een Azure Storage firewall hebt geconfigureerd. Deze sectie is van toepassing op ADLS Gen2-opslagaccounts achter een Azure Storage firewall. Azure Databricks werkruimteopslag achter een Azure Storage firewall wordt niet ondersteund.
Vereiste voorwaarden
Wanneer een Azure Storage firewall ADLS Gen2 beveiligt, Fabric werkruimte-id gebruikt om toegang te krijgen tot de firewall. Zelfs als u Service-principal selecteert voor ADLS-verificatie op het tabblad Network Security, moet u de werkruimte-id toestaan in de Azure Storage accountfirewall.
Werkruimte-identiteit wordt gebruikt voor toegang tot de opslagfirewall. Een service-principal of OAuth wordt gebruikt voor Databricks-verificatie en Unity Catalog-autorisatie.
Als u het verificatietype voor werkruimte-identiteit (aanbevolen) wilt inschakelen, koppelt u de Fabric-werkruimte aan een F-capaciteit. Zie Verifiëren met werkruimte-identiteit om een werkruimte-identiteit te maken.
U kunt een catalogus alleen koppelen aan één opslagaccount.
Netwerkbeveiligingstoegang inschakelen
Wanneer u een nieuwe gespiegelde Azure Databricks-catalogus maakt, selecteert u in de stap Gegevens kiezen het tabblad Netwerkbeveiliging .
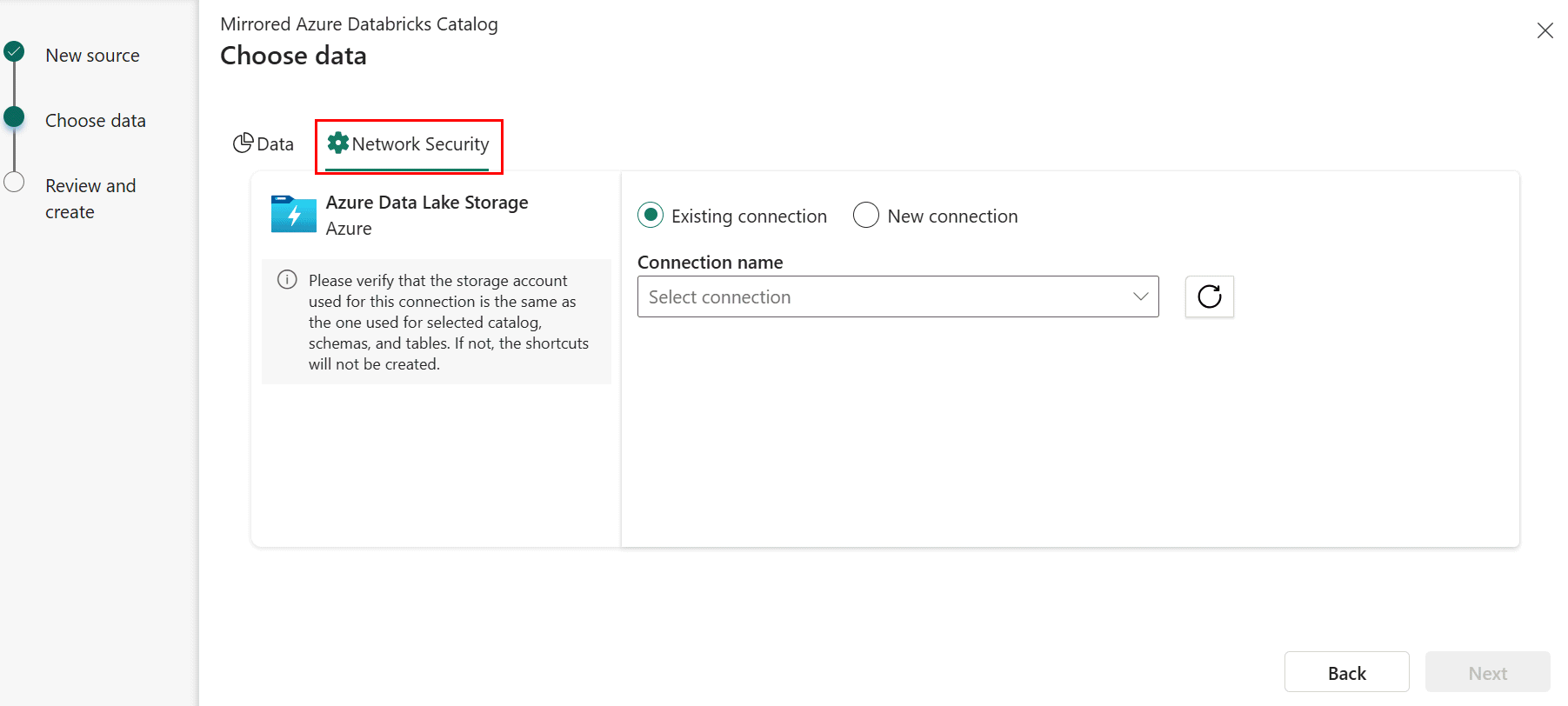
Selecteer een bestaande verbinding met het opslagaccount als u er een hebt geconfigureerd.
- Als u geen bestaande ADLS-verbinding hebt, maakt u een nieuwe verbinding.
- De URL van het opslageindpunt is waar de gegevens van de geselecteerde catalogus worden opgeslagen. Het eindpunt moet de specifieke map zijn waarin de gegevens worden opgeslagen, in plaats van het eindpunt op te geven op het niveau van het opslagaccount. Geef bijvoorbeeld
https://<storage account>.dfs.core.windows.net/container1/folder1in plaatshttps://<storage account>.dfs.core.windows.net/van . - Geef de verbindingsreferenties op. De ondersteunde verificatietypen zijn organisatieaccount, service-principal en werkruimte-id (aanbevolen).
Note
Wanneer ADLS Gen2 wordt beveiligd door een Azure Storage firewall, gebruikt Fabric werkruimte-id om de firewall te doorlopen, ongeacht het verificatietype dat hier is geselecteerd. Het authenticatietype (service-principal of organisatieaccount) bepaalt de Databricks-authenticatie en de autorisatie van Unity Catalog, terwijl Workspace-identiteit vertrouwde toegang via de opslagfirewall regelt. De werkruimte-id moet zijn toegestaan in de firewall van het Azure Storage account, zelfs als u een ander verificatietype voor de ADLS-verbinding selecteert.
Geef in Azure Portal toegangsrechten op voor het opslagaccount op basis van het verificatietype dat u in de vorige stap hebt gekozen. Navigeer naar het opslagaccount in Azure Portal. Selecteer Toegangsbeheer (IAM). Selecteer +Toevoegen en Roltoewijzing toevoegen. Zie Azure-rollen toewijzen met behulp van Azure Portal voor meer informatie.
Wijs een rol toe op basis van het bereik van de verbinding:
- Opslagaccount: De gekozen verificatie-id heeft de rol Opslagblobgegevenslezer in het opslagaccount nodig.
- Container: De gekozen authenticatie-identiteit moet de rol Storage Blob Data Reader voor de container hebben.
- Map binnen een container (aanbevolen): De gekozen authenticatie-identiteit heeft machtigingen voor Lezen (R) en Uitvoeren (E) nodig op mapniveau. Als u Service Principal of Werkruimte-identiteit als authenticatietype gebruikt, verleent u deze identiteit ook Uitvoeren-machtigingen op de hoofdmap van de container en op elke map in de hiërarchie die naar de opgegeven map leidt.
Zie ADLS-toegangsbeheer voor meer informatie en stappen voor het verlenen van ADLS-toegang.
Schakel Trusted Workspace Access in door een regel voor resource-exemplaren te configureren voor uw Fabric-werkruimte op het opslagaccount. Zie Toegang tot vertrouwde werkruimten en Secure Fabric mirrored databases van Azure Databricks voor gedetailleerde stappen.
Nadat de verbinding tot stand is gebracht, wordt er een snelkoppeling naar Unity Catalog-tabellen gemaakt voor de tabellen waarvan de naam van het opslagaccount overeenkomt met het opslagaccount dat is opgegeven in de ADLS-verbinding. Snelkoppelingen worden niet gemaakt voor tabellen waarvan de naam van het opslagaccount niet overeenkomt.
Belangrijk
Als u van plan bent om de ADLS-verbinding buiten de scenario's voor gespiegelde Azure Databricks catalogusitems te gebruiken, moet u ook de rol Storage Blob Delegator toewijzen aan het opslagaccount.
Tip
Als u een 403-autorisatiefout ontvangt bij het gebruik van een service-principal voor Databricks-verificatie met een ADLS Gen2-account dat is beveiligd met een firewall, controleert u of de werkruimte-id is toegestaan in de firewall van het Azure Storage account. Zelfs wanneer een service-principal is geselecteerd voor authenticatie, gebruikt Fabric de Werkruimte-identiteit om de opslagfirewall te passeren.
OneLake-beveiliging inschakelen voor het gespiegelde Databricks-item
Wijs UC-beleid (Unity Catalog) toe aan Microsoft OneLake-beveiliging door de volgende stappen uit te voeren:
- Synchroniseer de Entra-groep en pas machtigingen toe in Unity Catalog. In Azure Databricks gebruikt u Automatic Identity Management om een Microsoft Entra ID groep te synchroniseren en de benodigde Unity Catalog-bevoegdheden (USE, BROWSE en SELECT) toe te kennen aan de relevante catalogus en tabellen.
- Wijs een OneLake Data Access-rol toe. Maak in de werkruimte Fabric een rol voor gegevenstoegang voor de zojuist gespiegelde gegevens. Voeg dezelfde Entra-groep toe aan deze rol en geef het leestoegang tot de OneLake-snelkoppelingen die corresponderen met de Azure Databricks-tabellen. Als u aan de slag wilt gaan met beveiliging op tabelniveau, selecteert u de knop OneLake-beveiliging beheren op het lint. Zorg ervoor dat u de toegangsconfiguraties gesynchroniseerd houdt terwijl catalogusstructuren en machtigingen zich ontwikkelen. Zie het OneLake-model voor gegevenstoegangsbeheer (preview) voor meer informatie.
Verwante inhoud
- Gespiegelde Fabric-databases van Azure Databricks beveiligen
- Blog: Beveilig gespiegelde Azure Databricks-gegevens in Fabric met OneLake-beveiliging
- Beperkingen in gespiegelde Microsoft Fabric-databases van Azure Databricks
- Veelgestelde vragen over gespiegelde databases van Azure Databricks in Microsoft Fabric
- Het spiegelen van Azure Databricks Unity Catalog
- Externe toegang tot gegevens in Unity Catalog beheren