Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Op deze pagina wordt beschreven hoe u gegevens leest die met u zijn gedeeld met behulp van het open sharing-protocol voor Delta Sharing met bearer-tokens. Het bevat instructies voor het lezen van gedeelde gegevens met behulp van de volgende hulpprogramma's:
In dit open sharing-model gebruikt u een referentiebestand, gedeeld met een lid van uw team door de gegevensprovider, om veilige leestoegang te krijgen tot gedeelde gegevens. De toegang blijft behouden zolang de referentie geldig is en de provider de gegevens blijft delen. Providers beheren de vervaldatum en vervanging van inloggegevens. Updates voor de gegevens zijn bijna in realtime beschikbaar. U kunt kopieën van de gedeelde gegevens lezen en maken, maar u kunt de brongegevens niet wijzigen.
Notitie
Als gegevens met u zijn gedeeld met databricks-to-Databricks Delta Sharing, hebt u geen referentiebestand nodig voor toegang tot gegevens en is deze pagina niet van toepassing op u. Zie in plaats daarvan Gegevens lezen die worden gedeeld met Databricks-to-Databricks Delta Sharing (voor ontvangers).
Notitie
Bij open delen worden de mogelijkheden van de opslagbucket en de toegangsgegevens (bereik, vervaltermijn, alleen-lezen of lezen/schrijven) bepaald door de provider. Wanneer u in een SEG-werkruimte (Secure Egress Gateway) een open share koppelt, wordt de bucket van de provider automatisch op de toelatingslijst voor uitgaande toegang geplaatst — controleer de provider voordat u de share koppelt.
In de volgende secties wordt beschreven hoe u Azure Databricks-, Apache Spark-, pandas-, Power BI- en Iceberg-clients gebruikt om gedeelde gegevens te openen en te lezen met behulp van het referentiebestand. Zie de documentatie Delta Sharing open source voor een volledige lijst met Connectors voor Delen met Delta en informatie over het gebruik ervan. Als u problemen ondervindt bij het openen van de gedeelde gegevens, neemt u contact op met de gegevensprovider.
Voordat u begint
Een lid van uw team moet het referentiebestand downloaden dat wordt gedeeld door de gegevensprovider en een beveiligd kanaal gebruiken om dat bestand of de bestandslocatie met u te delen. Zie Toegang krijgen in het open sharing-model.
Zie de pagina met downloadreferenties voor specifieke connectordocumentatie.
Azure Databricks: Gedeelde gegevens lezen met behulp van open connectors voor delen
In deze sectie wordt beschreven hoe u een provider importeert en hoe u een query uitvoert op de gedeelde gegevens in Catalog Explorer of in een Python notebook:
Als uw Azure Databricks werkruimte is ingeschakeld voor Unity Catalog, gebruikt u de gebruikersinterface van de importprovider in Catalog Explorer. U kunt het volgende doen zonder een referentiebestand op te slaan of op te geven:
- Catalogussen maken op basis van shares met een klik op een knop.
- Gebruik toegangsbeheer voor Unity Catalog om toegang te verlenen tot gedeelde tabellen.
- Query's uitvoeren op gedeelde gegevens met behulp van de standaardsyntaxis van Unity Catalog.
- Pas een gerouleerde referentie toe op het bestaande providerobject zonder de catalogus opnieuw te maken. Zie Credentials roteren voor ontvangers met open credentials.
Als uw Azure Databricks werkruimte niet is ingeschakeld voor Unity Catalog, gebruikt u de Python notebookinstructies als voorbeeld.
Catalogusverkenner
machtigingen zijn vereist: een metastore-beheerder of een gebruiker met zowel de CREATE PROVIDER als USE PROVIDER bevoegdheden voor uw Unity Catalog-metastore.
Klik in uw Azure Databricks werkruimte op
 Catalog om Catalog Explorer te openen.
Catalog om Catalog Explorer te openen.Klik bovenaan het deelvenster Catalogus op
 en selecteer Delta Sharing.
en selecteer Delta Sharing.U kunt alternatief in de rechterbovenhoek op Share > Delta Sharing klikken.
Klik op het tabblad Gedeeld met mij op Share installeren.
Voer de naam van de aanbieder in.
De naam mag geen spaties bevatten.
Upload het referentiebestand dat de provider met u heeft gedeeld.
Veel providers hebben hun eigen Delta Sharing-netwerken waaruit u shares kunt ontvangen. Zie Providerspecifieke configuratiesvoor meer informatie.
(Optioneel) Voer een opmerking in.

Klik op importeren.
Catalogussen maken op basis van de gedeelde gegevens.
Klik op het tabblad Shares op Catalogus maken in de rij Share.
Zie Een catalogus maken op basis van een sharevoor informatie over het gebruik van SQL of de Databricks CLI om een catalogus te maken op basis van een share.
Verkrijg toegang tot de catalogi.
Zie Hoe kan ik gedeelde gegevens beschikbaar maken voor mijn team? en Machtigingen beheren voor de schema's, tabellen en volumes in een Delta Sharing-catalogus.
Lees de gedeelde gegevensobjecten op dezelfde manier als elk gegevensobject dat is geregistreerd in Unity Catalog.
Zie Access-gegevens in een gedeelde tabel of een gedeeld volumevoor meer informatie en voorbeelden.
Python
In deze sectie wordt beschreven hoe u een open connector voor delen gebruikt voor toegang tot gedeelde gegevens met behulp van een notitieblok in uw Azure Databricks werkruimte. U of een ander lid van uw team slaat het referentiebestand op in Azure Databricks en gebruikt het vervolgens om te verifiëren bij het Azure Databricks-account van de gegevensprovider en de gegevens te lezen die de gegevensprovider met u heeft gedeeld.
Notitie
In deze instructies wordt ervan uitgegaan dat uw Azure Databricks-werkruimte niet is ingeschakeld voor Unity Catalog. Als u Unity Catalog gebruikt, hoeft u niet naar het referentiebestand te verwijzen wanneer u de share leest. U kunt lezen uit gedeelde tabellen, net zoals u dat doet vanuit elke tabel die is geregistreerd in Unity Catalog. Databricks raadt u aan de gebruikersinterface van de importprovider te gebruiken in Catalog Explorer in plaats van de instructies die hier worden gegeven.
Sla het referentiebestand eerst op als een Azure Databricks werkruimtebestand, zodat gebruikers in uw team toegang hebben tot gedeelde gegevens.
Zie Importeer een bestand om het referentiebestand in uw Azure Databricks werkruimte te importeren.
Geef andere gebruikers toegang tot het bestand door naast het bestand op het
 te klikken en vervolgens op Delen (Machtigingen). Voer de Azure Databricks-identiteiten in die toegang moeten hebben tot het bestand.
te klikken en vervolgens op Delen (Machtigingen). Voer de Azure Databricks-identiteiten in die toegang moeten hebben tot het bestand.Zie Bestands-ACL's voor meer informatie over bestandsmachtigingen.
Nu het referentiebestand is opgeslagen, gebruikt u een notitieblok om gedeelde tabellen weer te geven en te lezen.
Klik in uw Azure Databricks werkruimte op Nieuwe > Notebook.
Zie Databricks-notebooks voor meer informatie over Azure Databricks notebooks.
Als u Python of
pandaswilt gebruiken voor toegang tot de gedeelde gegevens, installeert u de delta-sharing Python-connector. Plak de volgende opdracht in de notebook-editor:%sh pip install delta-sharingVoer de cel uit.
De
delta-sharingPython-bibliotheek is geïnstalleerd in het cluster als deze nog niet is geïnstalleerd.Gebruik Python om de tabellen in de share weer te maken.
Plak de volgende opdracht in een nieuwe cel. Vervang het pad naar de werkruimte door het bestandspad naar uw referentiebestand.
Wanneer de code wordt uitgevoerd, Python het referentiebestand leest.
import delta_sharing client = delta_sharing.SharingClient(f"/Workspace/path/to/config.share") client.list_all_tables()Voer de cel uit.
Het resultaat is een matrix met tabellen, samen met metagegevens voor elke tabel. In de volgende uitvoer ziet u twee tabellen:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]Als de uitvoer leeg is of niet de verwachte tabellen bevat, neemt u contact op met de gegevensprovider.
Een query uitvoeren op een gedeelde tabel.
Scala gebruiken:
Plak de volgende opdracht in een nieuwe cel. Wanneer de code wordt uitgevoerd, wordt het referentiebestand gelezen uit het werkruimtebestand.
Vervang de variabelen als volgt:
-
<profile-path>: het werkruimtepad van het referentiebestand. Bijvoorbeeld:/Workspace/Users/user.name@email.com/config.share. -
<share-name>: de waarde vanshare=voor de tabel. -
<schema-name>: de waarde vanschema=voor de tabel. -
<table-name>: de waarde vanname=voor de tabel.
%scala spark.read.format("deltaSharing") .load("<profile-path>#<share-name>.<schema-name>.<table-name>").limit(10);Voer de cel uit. Telkens wanneer u de gedeelde tabel laadt, ziet u nieuwe gegevens uit de bron.
Zie Kolommen voor het bijhouden van rijen in gedeelde tabellen lezen als u deze kolommen wilt opvragen.
-
SQL gebruiken:
Als u een query wilt uitvoeren op de gegevens met behulp van SQL, maakt u een lokale tabel in de werkruimte op basis van de gedeelde tabel en voert u vervolgens een query uit op de lokale tabel. De gedeelde gegevens worden niet opgeslagen of in de cache geplaatst in de lokale tabel. Telkens wanneer u een query uitvoert op de lokale tabel, ziet u de huidige status van de gedeelde gegevens.
Plak de volgende opdracht in een nieuwe cel.
Vervang de variabelen als volgt:
-
<local-table-name>: de naam van de lokale tabel. -
<profile-path>: de locatie van het referentiebestand. -
<share-name>: de waarde vanshare=voor de tabel. -
<schema-name>: de waarde vanschema=voor de tabel. -
<table-name>: de waarde vanname=voor de tabel.
%sql DROP TABLE IF EXISTS table_name; CREATE TABLE <local-table-name> USING deltaSharing LOCATION "<profile-path>#<share-name>.<schema-name>.<table-name>"; SELECT * FROM <local-table-name> LIMIT 10;Wanneer u de opdracht uitvoert, worden de gedeelde gegevens rechtstreeks opgevraagd. Als test wordt de tabel opgevraagd en worden de eerste 10 resultaten geretourneerd.
-
Als de uitvoer leeg is of niet de verwachte gegevens bevat, neemt u contact op met de gegevensprovider.
Iceberg-clients: gedeelde gegevens lezen
Gebruik externe Iceberg-clients, zoals Snowflake, Trino, Flink en Spark, om gedeelde gegevensassets te lezen met zero-copy-toegang met behulp van de Apache Iceberg REST Catalog-API.
Verbindingsreferenties verkrijgen
Voordat u toegang krijgt tot gedeelde gegevensassets met externe Iceberg-clients, moet u de volgende referenties verzamelen:
- Het eindpunt van de Iceberg REST-catalogus
- Een geldig Bearer-token
- De naam van de share
- (Optioneel) De naamruimte of schemanaam
- (Optioneel) De tabelnaam
Het Iceberg REST Catalog-eindpunt (icebergEndpoint) en het Bearer-token vindt u in het referentiebestand dat met u is gedeeld door uw gegevensprovider. Zie Voordat u begint voor meer informatie. De naam, naamruimte en tabelnaam van de share kunnen programmatisch worden gedetecteerd met behulp van Delta Sharing-API's.
Belangrijk
Het icebergEndpoint bestand is te vinden in het referentiebestand en heeft de indeling <workspace-url>/api/2.0/delta-sharing/metastores/<metastore-id>/iceberg.
In de volgende voorbeelden ziet u hoe u de aanvullende referenties kunt verkrijgen. Voer waar nodig het eindpunt, het Iceberg-eindpunt en het Bearer-token in vanuit het referentiebestand:
// List shares
curl -X GET "<endpoint>/shares" \
-H "Authorization: Bearer <bearerToken>"
// List namespaces
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces" \
-H "Authorization: Bearer <bearerToken>"
// List tables
curl -X GET "<icebergEndpoint>/v1/shares/<share>/namespaces/<namespace>/tables" \
-H "Authorization: Bearer <bearerToken>"
Notitie
Met deze methode wordt altijd de meest actuele lijst met assets opgehaald. Hiervoor is echter internettoegang vereist en kan het moeilijker zijn om te integreren in omgevingen zonder code.
Iceberg-catalogus configureren
Nadat u de benodigde verbindingsreferenties hebt verkregen, configureert u uw client om de Iceberg REST Catalog-eindpunten te gebruiken om tabellen te maken en er query's op uit te voeren.
Maak voor elke share een catalogusintegratie.
USE ROLE ACCOUNTADMIN; CREATE OR REPLACE CATALOG INTEGRATION <CATALOG_PLACEHOLDER> CATALOG_SOURCE = ICEBERG_REST TABLE_FORMAT = ICEBERG REST_CONFIG = ( CATALOG_URI = '<icebergEndpoint>', WAREHOUSE = '<share_name>', ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS ) REST_AUTHENTICATION = ( TYPE = BEARER, BEARER_TOKEN = '<bearerToken>' ) ENABLED = TRUE;Voeg desgewenst toe
REFRESH_INTERVAL_SECONDSom metagegevens up-to-date te houden. Stel de waarde in op basis van de frequentie van de catalogusupdate.REFRESH_INTERVAL_SECONDS = 30Nadat de catalogus is geconfigureerd, maakt u een database op basis van de catalogus. Hiermee worden automatisch alle schema's en tabellen in die catalogus gemaakt.
CREATE DATABASE <DATABASE_PLACEHOLDER> LINKED_CATALOG = ( CATALOG = <CATALOG_PLACEHOLDER> );Als u wilt controleren of het delen is gelukt, voert u een query uit vanuit een tabel in de database. U ziet de gedeelde gegevens uit Azure Databricks.
Als het resultaat leeg is of er een fout optreedt, volgt u deze veelvoorkomende stappen voor probleemoplossing:
- Controleer de bevoegdheden, de generatiestatus van momentopnamen en REST-referenties.
- Neem contact op met uw gegevensprovider.
- Raadpleeg de documentatie die specifiek is voor uw Iceberg-client.
Voorbeeld: Gedeelde tabellen openen met verschillende Iceberg-clients
In de volgende voorbeelden ziet u hoe u toegang krijgt tot gedeelde Delta-tabellen met behulp van externe Iceberg-clients, zoals Snowflake, Apache Spark, PyIceberg en REST API, nadat u uw verbindingsreferenties hebt verkregen. Zie Voordat u begint voor meer informatie over het verkrijgen van verbindingsreferenties.
Snowflake
Als u gedeelde gegevensassets in Snowflake wilt lezen, uploadt u het referentiebestand dat u hebt gedownload en genereert u de benodigde SQL-opdracht:
Klik in de activeringskoppeling voor Delta Sharing op het snowflake-pictogram.
Upload op de integratiepagina van Snowflake het referentiebestand dat u hebt ontvangen van de gegevensprovider.

Nadat u de inloggegevens hebt geladen, kiest u de share die u wilt openen in Snowflake.
Klik op SQL genereren nadat u de gewenste assets hebt geselecteerd.
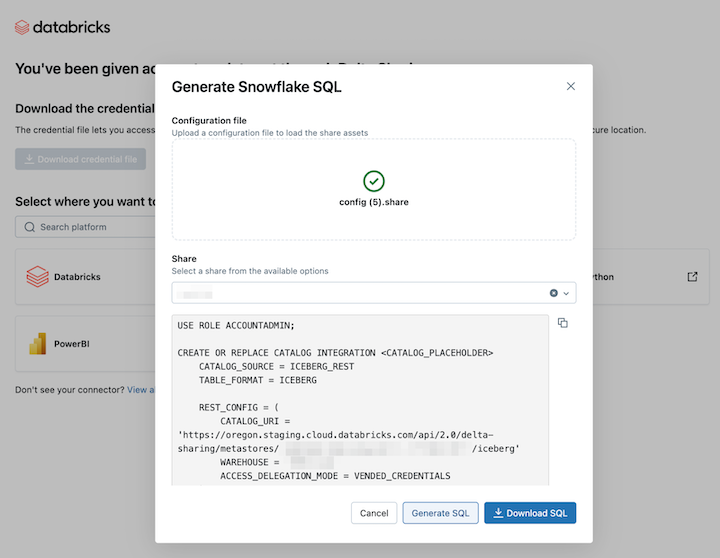
Kopieer en plak de gegenereerde SQL in uw Snowflake-werkblad. Vervang
CATALOG_PLACEHOLDERdoor de naam van de catalogus die u wilt gebruiken enDATABASE_PLACEHOLDERdoor de naam van de database die u wilt gebruiken.
Beperkingen
Verbinding maken met de Iceberg REST-catalogus in Snowflake heeft de volgende beperkingen:
- Het metagegevensbestand wordt niet automatisch bijgewerkt met de meest recente momentopname. U moet afhankelijk zijn van automatisch vernieuwen of handmatige vernieuwingen.
- R2 wordt niet ondersteund.
- Alle beperkingen van de Iceberg-client zijn van toepassing.
Apache Spark
Als u toegang wilt krijgen tot gedeelde tabellen met behulp van Apache Spark, configureert u de ICEBERG REST Catalog-API met de volgende instellingen. Vervang <spark-catalog-name> door een naam voor uw catalogus en geef uw verbindingsreferenties op:
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
# Configuration for accessing tables shared using Delta Sharing
"spark.sql.catalog.<spark-catalog-name>":"org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<spark-catalog-name>.type": "rest",
"spark.sql.catalog.<spark-catalog-name>.uri": "<icebergEndpoint>",
"spark.sql.catalog.<spark-catalog-name>.token": "<bearerToken>",
"spark.sql.catalog.<spark-catalog-name>.warehouse":"<share_name>",
"spark.sql.catalog.<spark-catalog-name>.scope":"all-apis"
PyIceberg
PyIceberg is een Python implementatie voor toegang tot Iceberg-tabellen zonder een JVM te gebruiken. PyIceberg vereist pyarrow voor tabelbewerkingen, zoals het lezen van gegevens en het inspecteren van metagegevens van tabellen. Installeer PyIceberg met de pyarrow toevoeging:
pip install "pyiceberg[pyarrow]"
Als u toegang wilt krijgen tot gedeelde tabellen, voegt u de volgende catalogusconfiguratie toe aan uw PyIceberg-configuratiebestand:
catalog:
delta_sharing:
type: rest
uri: <icebergEndpoint>
warehouse: <share_name>
token: <bearerToken>
REST API
Gebruik een REST API-aanroep zoals in het volgende curl voorbeeld om een tabel te laden en de bijbehorende metagegevens op te halen, samen met tijdelijke referenties voor toegang tot de gegevensbestanden:
curl -X GET -H "Authorization: Bearer <bearerToken>" -H "Accept: application/json" \
<icebergEndpoint>/v1/shares/<share_name>/namespaces/<schema_name>/tables/<table_name>
Het antwoord bevat de metagegevens van de Iceberg-tabel, de S3-locatie en tijdelijke AWS-referenties waarmee uw client de gegevensbestanden kan lezen:
{
"metadata-location": "s3://bucket/path/to/iceberg/table/metadata/file",
"metadata": <iceberg-table-metadata-json>,
"config": {
"expires-at-ms": "<epoch-ts-in-millis>",
"s3.access-key-id": "<temporary-s3-access-key-id>",
"s3.session-token": "<temporary-s3-session-token>",
"s3.secret-access-key": "<temporary-secret-access-key>",
"client.region": "<aws-bucket-region-for-metadata-location>"
}
}
Beperkingen van Iceberg-clients
De volgende beperkingen zijn van toepassing bij het uitvoeren van query's op Delta Sharing-gegevens van Iceberg-clients:
- Als de naamruimte meer dan 100 gedeelde weergaven bevat, is het antwoord beperkt tot de eerste 100 weergaven wanneer u tabellen in een naamruimte opgeeft.
Apache Spark: gedeelde gegevens lezen
Volg deze stappen voor toegang tot gedeelde gegevens met spark 3.x of hoger.
In deze instructies wordt ervan uitgegaan dat u toegang hebt tot het referentiebestand dat is gedeeld door de gegevensprovider. Zie Toegang krijgen in het open sharing-model.
Belangrijk
Zorg ervoor dat uw referentiebestand toegankelijk is voor Apache Spark met behulp van een absoluut pad. Het pad kan verwijzen naar een cloudobject of Unity Catalog-volume.
Notitie
Als u Spark gebruikt in een Azure Databricks werkruimte die is ingeschakeld voor Unity Catalog en u de gebruikersinterface van de importprovider hebt gebruikt om de provider te importeren en te delen, zijn de instructies in deze sectie niet van toepassing op u. U hebt net zo toegang tot gedeelde tabellen als elke andere tabel die is geregistreerd in Unity Catalog. U hoeft de delta-sharing Python-connector niet te installeren of het pad naar het referentiebestand op te geven. Zie Azure Databricks: Gedeelde gegevens lezen met behulp van open connectors voor delen.
De Delta Sharing-Python- en Spark-connectors installeren
Ga als volgt te werk om toegang te krijgen tot metagegevens met betrekking tot de gedeelde gegevens, zoals de lijst met tabellen die met u zijn gedeeld. In dit voorbeeld wordt Python gebruikt.
Installeer de delta-sharing Python connector. Zie Beperkingen voor deltadeling Python connector voor meer informatie over Python connectorbeperkingen.
pip install delta-sharingInstalleer de Apache Spark-connector.
Gedeelde tabellen weergeven met Spark
De tabellen in de gedeelde map weergeven. Vervang in het volgende voorbeeld door <profile-path> de locatie van het referentiebestand.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Het resultaat is een matrix met tabellen, samen met metagegevens voor elke tabel. In de volgende uitvoer ziet u twee tabellen:
Out[10]: [Table(name='example_table', share='example_share_0', schema='default'), Table(name='other_example_table', share='example_share_0', schema='default')]
Als de uitvoer leeg is of niet de verwachte tabellen bevat, neemt u contact op met de gegevensprovider.
Gebruik Spark om gedeelde gegevens te openen
Voer het volgende uit, waarbij u deze variabelen vervangt:
-
<profile-path>: de locatie van het referentiebestand. -
<share-name>: de waarde vanshare=voor de tabel. -
<schema-name>: de waarde vanschema=voor de tabel. -
<table-name>: de waarde vanname=voor de tabel. -
<version-as-of>:facultatief. De versie van de tabel waarop de gegevens geladen moeten worden. Werkt alleen als de gegevensprovider de geschiedenis van de tabel deelt. Vereistdelta-sharing-spark0.5.0 of hoger. -
<timestamp-as-of>:facultatief. Laad de gegevens in de versie vóór of op de opgegeven tijdstempel. Werkt alleen als de gegevensprovider de geschiedenis van de tabel deelt. Vereistdelta-sharing-spark0.6.0 of hoger.
Python
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", version=<version-as-of>)
spark.read.format("deltaSharing")\
.option("versionAsOf", <version-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
delta_sharing.load_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>", timestamp=<timestamp-as-of>)
spark.read.format("deltaSharing")\
.option("timestampAsOf", <timestamp-as-of>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")\
.limit(10)
Scala
spark.read.format("deltaSharing")
.option("versionAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
spark.read.format("deltaSharing")
.option("timestampAsOf", <version-as-of>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.limit(10)
Toegang tot gedeelde gegevensfeed voor wijzigingen met Spark
Als de tabelgeschiedenis met u is gedeeld en CDF (Data Feed) is ingeschakeld in de brontabel, opent u de wijzigingengegevensfeed door het volgende uit te voeren, waarbij u deze variabelen vervangt. Vereist delta-sharing-spark 0.5.0 of hoger.
Er moet één beginparameter worden opgegeven.
-
<profile-path>: de locatie van het referentiebestand. -
<share-name>: de waarde vanshare=voor de tabel. -
<schema-name>: de waarde vanschema=voor de tabel. -
<table-name>: de waarde vanname=voor de tabel. -
<starting-version>:facultatief. De startversie van de query, inclusief. Specificeer als een gegevenstype 'Long'. -
<ending-version>:facultatief. De eindversie van de query, waarbij inbegrepen. Als de eindversie niet is opgegeven, gebruikt de API de nieuwste tabelversie. -
<starting-timestamp>:facultatief. De begintijdstempel van de query wordt omgezet in een versie die groter of gelijk is aan deze tijdstempel. Specificeer als een tekenreeks in het formaatyyyy-mm-dd hh:mm:ss[.fffffffff]. -
<ending-timestamp>:facultatief. Het eindtijdstempel van de query wordt geconverteerd naar een versie die eerder is gemaakt of gelijk is aan deze tijdstempel. Opgeven als een tekenreeks in het formaatyyyy-mm-dd hh:mm:ss[.fffffffff]
Python
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_spark(f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingVersion", <starting-version>)\
.option("endingVersion", <ending-version>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")\
.option("startingTimestamp", <starting-timestamp>)\
.option("endingTimestamp", <ending-timestamp>)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingVersion", <starting-version>)
.option("endingVersion", <ending-version>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
spark.read.format("deltaSharing").option("readChangeFeed", "true")
.option("startingTimestamp", <starting-timestamp>)
.option("endingTimestamp", <ending-timestamp>)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Als de uitvoer leeg is of niet de verwachte gegevens bevat, neemt u contact op met de gegevensprovider.
Toegang tot een gedeelde tabel met behulp van Spark Structured Streaming
Als de tabelgeschiedenis met u wordt gedeeld, kunt u de gedeelde gegevens streamen. Vereist delta-sharing-spark 0.6.0 of hoger.
Ondersteunde opties:
-
ignoreDeletes: Transacties negeren die gegevens verwijderen. -
ignoreChanges: Updates opnieuw verwerken als bestanden zijn herschreven in de brontabel vanwege een bewerking voor het wijzigen van gegevens, zoalsUPDATE,MERGE INTODELETE(binnen partities) ofOVERWRITE. Ongewijzigde rijen kunnen nog steeds worden uitgezonden. Daarom moeten uw downstreamgebruikers dubbele waarden kunnen verwerken. Verwijderingen worden niet naar de volgende stap doorgegeven.ignoreChangesvalt onderignoreDeletes. Daarom, als uignoreChangesgebruikt, wordt uw stream niet onderbroken door verwijderingen of updates van de brontabel. -
startingVersion: De versie van de gedeelde tabel waaruit moet worden gestart. Alle tabelwijzigingen die vanaf en inclusief deze versie zijn gemaakt, worden gelezen door de streamingbron. -
startingTimestamp: vanaf welk tijdstempel gestart moet worden. Alle tabelwijzigingen die zijn doorgevoerd op of na de tijdstempel (inclusief) worden gelezen door de streamingbron. Voorbeeld:"2023-01-01 00:00:00.0". -
maxFilesPerTrigger: Het aantal nieuwe bestanden dat in elke microbatch moet worden overwogen. -
maxBytesPerTrigger: De hoeveelheid gegevens die in elke microbatch wordt verwerkt. Met deze optie stelt u een 'voorlopig maximum' in, wat betekent dat een batch ongeveer deze hoeveelheid gegevens verwerkt en meer dan de limiet kan verwerken om de streamingquery vooruit te laten gaan in gevallen waarin de kleinste invoereenheid groter is dan deze limiet. -
readChangeFeed: Stream leest de wijzigingengegevensfeed van de gedeelde tabel.
Niet-ondersteunde opties:
Trigger.availableNow
Voorbeelden van gestructureerde streamingquery's
Python
spark.readStream.format("deltaSharing")\
.option("startingVersion", 0)\
.option("ignoreDeletes", true)\
.option("maxBytesPerTrigger", 10000)\
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Scala
spark.readStream.format("deltaSharing")
.option("startingVersion", 0)
.option("ignoreChanges", true)
.option("maxFilesPerTrigger", 10)
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
Zie ook Structured Streaming-concepten.
Tabellen lezen met ingeschakelde verwijderingsvectoren of kolomtoewijzing
Belangrijk
Deze functie is beschikbaar als openbare preview.
Verwijderingsvectoren zijn een functie voor opslagoptimalisatie die uw provider kan inschakelen voor gedeelde Delta-tabellen. Zie Verwijderingsvectoren in Databricks.
Azure Databricks ondersteunt ook kolomtoewijzing voor Delta-tabellen. Zie Kolommen hernoemen en verwijderen met kolomtoewijzing van Delta Lake.
Als uw provider een tabel heeft gedeeld met verwijderingsvectoren of kolomtoewijzing ingeschakeld, kunt u de tabel lezen door gebruik te maken van compute die draait op delta-sharing-spark versie 3.1 of hoger. Als u Databricks-clusters gebruikt, kunt u batchleesbewerkingen uitvoeren met behulp van een cluster met Databricks Runtime 14.1 of hoger. Voor CDF- en streamingquery's is Databricks Runtime 14.2 of hoger vereist.
U kunt batchquery's uitvoeren zoals ze zijn, omdat ze automatisch responseFormat kunnen oplossen op basis van de tabelfuncties van de gedeelde tabel.
Als u een CDF (Change Data Feed) wilt lezen of streamingquery's wilt uitvoeren op gedeelde tabellen waarvoor verwijderingsvectoren of kolomtoewijzing zijn ingeschakeld, moet u de extra optie responseFormat=deltainstellen.
In de volgende voorbeelden ziet u batch-, CDF- en streamingquery's:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("...")
.master("...")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate()
val tablePath = "<profile-file-path>#<share-name>.<schema-name>.<table-name>"
// Batch query
spark.read.format("deltaSharing").load(tablePath)
// CDF query
spark.read.format("deltaSharing")
.option("readChangeFeed", "true")
.option("responseFormat", "delta")
.option("startingVersion", 1)
.load(tablePath)
// Streaming query
spark.readStream.format("deltaSharing").option("responseFormat", "delta").load(tablePath)
Kolommen voor het bijhouden van rijen in gedeelde tabellen lezen
Als de gegevensprovider het bijhouden van rijen voor een gedeelde tabel heeft ingeschakeld, kunt u query's uitvoeren op de kolommen met metagegevens voor het bijhouden van rijen met behulp van Scala Spark. Zie Rijtracering in Databricks voor een lijst met beschikbare kolommen.
U moet de responseFormat optie instellen op delta.
spark.read.format("deltaSharing")
.option("responseFormat", "delta")
.load("<profile-path>#<share-name>.<schema-name>.<table-name>")
.select("_metadata.row_id")
.show()
Notitie
Alleen de delta-antwoordindeling wordt ondersteund voor het uitvoeren van query's op kolommen voor het bijhouden van rijen in de Spark-client. Dump-connectors worden niet ondersteund.
Pandas: gedeelde gegevens lezen
Volg deze stappen voor toegang tot gedeelde gegevens in pandas 0.25.3 of hoger.
In deze instructies wordt ervan uitgegaan dat u toegang hebt tot het referentiebestand dat is gedeeld door de gegevensprovider. Zie Toegang krijgen in het open sharing-model.
Notitie
Als u pandas gebruikt in een Azure Databricks werkruimte die is ingeschakeld voor Unity Catalog en u de gebruikersinterface van de importprovider hebt gebruikt om de provider te importeren en te delen, zijn de instructies in deze sectie niet van toepassing op u. U hebt net zo toegang tot gedeelde tabellen als elke andere tabel die is geregistreerd in Unity Catalog. U hoeft de delta-sharing Python-connector niet te installeren of het pad naar het referentiebestand op te geven. Zie Azure Databricks: Gedeelde gegevens lezen met behulp van open connectors voor delen.
De Python-connector voor Delta Sharing installeren
Voor toegang tot metagegevens met betrekking tot de gedeelde gegevens, zoals de lijst met tabellen die met u worden gedeeld, moet u de delta-sharing Python connector installeren. Zie Beperkingen voor deltadeling Python connector voor meer informatie over Python connectorbeperkingen.
pip install delta-sharing
Gedeelde tabellen weergeven met pandas
Als u de tabellen in de share wilt weergeven, voert u het volgende uit, waarbij u <profile-path>/config.share vervangt door de locatie van het referentiebestand.
import delta_sharing
client = delta_sharing.SharingClient(f"<profile-path>/config.share")
client.list_all_tables()
Als de uitvoer leeg is of niet de verwachte tabellen bevat, neemt u contact op met de gegevensprovider.
Gedeelde gegevens openen met pandas
Als u toegang wilt krijgen tot gedeelde gegevens in pandas met behulp van Python, voert u het volgende uit en vervangt u de variabelen als volgt:
-
<profile-path>: de locatie van het referentiebestand. -
<share-name>: de waarde vanshare=voor de tabel. -
<schema-name>: de waarde vanschema=voor de tabel. -
<table-name>: de waarde vanname=voor de tabel.
import delta_sharing
delta_sharing.load_as_pandas(f"<profile-path>#<share-name>.<schema-name>.<table-name>")
Toegang tot een gedeelde veranderingsgegevensfeed met behulp van pandas
Als u toegang wilt krijgen tot de gegevensfeed voor een gedeelde tabel in pandas met behulp van Python voert u het volgende uit, waarbij u de variabelen als volgt vervangt. Mogelijk is er geen wijzigingenfeed beschikbaar, afhankelijk van de vraag of de gegevensprovider de feed voor de tabel heeft gedeeld.
-
<starting-version>:facultatief. De startversie van de query, inclusief. -
<ending-version>:facultatief. De eindversie van de query, waarbij inbegrepen. -
<starting-timestamp>:facultatief. Het begintijdstempel van de query. Dit wordt geconverteerd naar een versie die groter of gelijk is aan deze tijdstempel. -
<ending-timestamp>:facultatief. De eindtijdstempel van de query. Dit wordt geconverteerd naar een versie die eerder is gemaakt of gelijk is aan deze tijdstempel.
import delta_sharing
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_version=<starting-version>,
ending_version=<ending-version>)
delta_sharing.load_table_changes_as_pandas(
f"<profile-path>#<share-name>.<schema-name>.<table-name>",
starting_timestamp=<starting-timestamp>,
ending_timestamp=<ending-timestamp>)
Als de uitvoer leeg is of niet de verwachte gegevens bevat, neemt u contact op met de gegevensprovider.
Power BI: Gedeelde gegevens lezen
Met de Power BI Delta Sharing-connector kunt u gegevenssets detecteren, analyseren en visualiseren die met u zijn gedeeld via het open protocol delta delen.
Behoeften
- Power BI Desktop 2.99.621.0 of hoger.
- Toegang tot het referentiebestand dat is gedeeld door de gegevensprovider. Zie Toegang krijgen in het open sharing-model.
Verbinding maken met Databricks
Ga als volgt te werk om verbinding te maken met Azure Databricks met behulp van de Delta Sharing-connector:
- Open het bestand met gedeelde referenties met een teksteditor om de eindpunt-URL en het token op te halen.
- Open Power BI Desktop.
- Zoek in het menu Gegevens ophalen naar Delta Sharing.
- Selecteer de connector en klik op Verbinding maken.
- Voer de eindpunt-URL in die u hebt gekopieerd uit het referentiebestand in het veld URL van de Delta Sharing Server.
- U kunt desgewenst op het tabblad Geavanceerde opties een rijlimiet instellen voor het maximum aantal rijen dat u kunt downloaden. Dit is standaard ingesteld op 1 miljoen rijen.
- Klik op OK.
- Kopieer voor verificatie het token dat u hebt opgehaald uit het referentiebestand naar het Bearer-token.
- Klik op Verbinding maken.
Beperkingen van de Power BI Delta Sharing-connector
De Power BI Delta Sharing Connector heeft de volgende beperkingen:
- De gegevens die door de connector worden geladen, moeten in het geheugen van uw computer passen. Om deze vereiste te beheren, beperkt de connector het aantal geïmporteerde rijen tot de Row Limit die u hebt ingesteld op het tabblad Geavanceerde opties in Power BI Bureaublad.
Tableau: Gedeelde gegevens lezen
Met de Tableau Delta Sharing-connector kunt u gegevenssets detecteren, analyseren en visualiseren die met u worden gedeeld via het open protocol Delta Sharing.
Behoeften
- Tableau Desktop en Tableau Server 2024.1 of hoger
- Toegang tot het referentiebestand dat is gedeeld door de gegevensprovider. Zie Toegang krijgen in het open sharing-model.
Verbinding maken met Azure Databricks
Ga als volgt te werk om verbinding te maken met Azure Databricks met behulp van de Delta Sharing-connector:
- Ga naar Tableau Exchange, volg de instructies voor het downloaden van de Delta Sharing Connector en plaats deze in een geschikte bureaubladmap.
- Open Tableau Desktop.
- Zoek op de pagina Connectors naar Delta Sharing by Databricks.
- Selecteer Upload Share-bestand en kies het referentiebestand dat door de provider is gedeeld.
- Klik op Gegevens ophalen.
- Selecteer de tabel in de Data Explorer.
- Voeg desgewenst SQL-filters of rijlimieten toe.
- Klik op Tabelgegevens ophalen.
Beperkingen
De Tableau Delta Sharing Connector heeft de volgende beperkingen:
- De gegevens die door de connector worden geladen, moeten in het geheugen van uw computer passen. Om aan deze eis te voldoen, beperkt de connector het aantal geïmporteerde rijen tot de rijlimiet die u in Tableau instelt.
- Alle kolommen worden geretourneerd als type
String. - SQL-filter werkt alleen als uw Delta Sharing-server predicateHint ondersteunt.
- Verwijderingsvectoren worden niet ondersteund.
- Kolomtoewijzing wordt niet ondersteund.
Beperkingen voor de Delta Sharing Python-connector
Deze beperkingen zijn specifiek voor de Python-connector voor Delta Sharing:
- De Delta Sharing Python connector 1.1.0+ ondersteunt momentopnamequery's in tabellen met kolomtoewijzing, maar CDF-query's op tabellen met kolomtoewijzing worden niet ondersteund.
- De Delta Sharing Python-connector geeft een foutmelding bij CDF-queries met
use_delta_format=Trueals het schema is gewijzigd binnen het opgevraagde versiebereik.
Beperkingen voor streaming-tabellen
U kunt alleen de huidige momentopname van een gedeelde streamingtabel lezen. De volgende functies worden niet ondersteund voor streamingtabellen bij openen delen:
- Query's uitvoeren op de geschiedenisgegevens van de tabel
- Query's uitvoeren op de wijzigingenfeed van de tabel (CDF)
- De tabel gebruiken als bron voor Spark Structured Streaming
Beperkingen voor gematerialiseerde weergave
U kunt alleen de momentopname van de huidige gedeelde gematerialiseerde weergave lezen. Het gebruik van een gerealiseerde weergave als bron voor Spark Structured Streaming wordt niet ondersteund bij openen delen.
Een nieuwe referentie aanvragen
Als uw referentieactiverings-URL of gedownloade referenties verloren gaan, beschadigd of aangetast zijn of als uw referenties verlopen zonder dat uw provider u een nieuwe referentie stuurt, neemt u contact op met uw provider om een nieuwe referentie aan te vragen.
Als u een Azure Databricks ontvanger bent die de referentie als providerobject in Unity Catalog heeft geïmporteerd, past u de nieuwe referentie toe met behulp van de Databricks REST API. Zie Credentials roteren voor ontvangers met open credentials.