Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Aanbeveling
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
Als u nieuw bent bij Azure Data Factory, zie Introductie van Azure Data Factory.
In deze zelfstudie gebruikt u het canvas voor gegevensstromen om gegevensstromen te maken waarmee u gegevens in Azure Data Lake Storage (ADLS) Gen2 kunt analyseren en transformeren en opslaan in Delta Lake.
Vereisten
- Azure-abonnement. Als u geen Azure abonnement hebt, maakt u een vrij Azure account voordat u begint.
- Azure-opslagaccount. U gebruikt ADLS-opslag als bron - en sinkgegevensopslag . Als u geen opslagaccount hebt, raadpleegt u Maak een Azure-opslagaccount voor stappen om er een te maken.
Het bestand dat we in deze zelfstudie transformeren, is MoviesDB.csv, die hier te vinden is. Als u het bestand wilt ophalen uit GitHub, kopieert u de inhoud naar een teksteditor van uw keuze om lokaal op te slaan als een .csv bestand. Zie Upload-blobs met de Azure-portal om het bestand naar uw opslagaccount te uploaden. De voorbeelden verwijzen naar een container met de naam sample-data.
Een data factory maken
In deze stap maakt u een data factory en opent u de Data Factory UX om een pijplijn in de data factory te maken.
Open Microsoft Edge of Google Chrome. Momenteel wordt de Data Factory-gebruikersinterface alleen ondersteund in de webbrowsers Microsoft Edge en Google Chrome.
Selecteer in het linkermenu Een resource maken>Integratie>Data Factory
Op de pagina Nieuwe gegevensfabriek, voer onder NaamADFTutorialDataFactory in.
Selecteer de Azure subscription waarin u de data factory wilt maken.
Voer voor de resourcegroep een van de volgende stappen uit:
een. Selecteer Bestaande gebruiken en selecteer een bestaande resourcegroep in de vervolgkeuzelijst.
b. Selecteer Nieuwe maken en voer de naam van een resourcegroep in.
Zie Resourcegroepen gebruiken om uw Azure resources te beheren voor meer informatie over resourcegroepen.
Selecteer onder VersieV2.
Selecteer onder Locatie een locatie voor de data factory. In de vervolgkeuzelijst worden alleen ondersteunde locaties weergegeven. Gegevensarchieven (bijvoorbeeld Azure Storage en SQL Database) en berekeningen (bijvoorbeeld Azure HDInsight) die door de data factory worden gebruikt, kunnen zich in andere regio's bevinden.
Selecteer Maken.
Als het maken is voltooid, ziet u de melding in het meldingencentrum. Selecteer Ga naar de resource om naar de Data Factory-pagina te navigeren.
Selecteer Auteur & Monitor om de Data Factory-gebruikersinterface op een afzonderlijk tabblad te starten.
Een pijplijn maken met een gegevensstroomactiviteit
In deze stap maakt u een pijplijn die een gegevensstroomactiviteit bevat.
Selecteer Orchestrate op de startpagina.
Voer op het tabblad Algemeen voor de pijplijn DeltaLake in voor de naam van de pijplijn.
Vouw in het deelvenster Activiteiten de accordeon Verplaatsen en Transformeren uit. Sleep de activiteit Gegevensstroom van het deelvenster naar het pijplijncanvas.
Zet in de bovenbalk van het pijplijncanvas de schuifregelaar Gegevensstroom foutopsporing aan. Met de foutopsporingsmodus kunt u interactieve transformatielogica testen op een live Spark-cluster. Gegevensstroom-clusters nemen 5-7 minuten in beslag om op te starten en gebruikers wordt aangeraden eerst debug in te schakelen als ze van plan zijn om Gegevensstroom-ontwikkeling uit te voeren. Zie De foutopsporingsmodus voor meer informatie.
Transformatielogica bouwen in het gegevensstroomcanvas
In deze zelfstudie genereert u twee gegevensstromen. De eerste gegevensstroom is een eenvoudige bron om een nieuwe Delta Lake te genereren op basis van het CSV-bestand met films. Ten slotte maakt u het stroomontwerp dat volgt om gegevens in Delta Lake bij te werken.

Zelfstudiedoelstellingen
- Gebruik de bron van de MoviesCSV-dataset uit de vereisten en maak er een nieuwe Delta Lake van.
- Bouw de logica om beoordelingen voor 1988 films te bijwerken naar '1'.
- Verwijder alle films uit 1950.
- Voeg nieuwe films voor 2021 in door de films uit 1960 te dupliceren.
Beginnen met een leeg gegevensstroomcanvas
Selecteer de brontransformatie boven aan het venster van de gegevensstroomeditor en selecteer vervolgens + Nieuw naast de eigenschap Gegevensset in het venster Broninstellingen :

Selecteer Azure Data Lake Storage Gen2 in het venster Nieuwe gegevensset dat wordt weergegeven en selecteer vervolgens Continue.

Kies DelimitedText voor het gegevenssettype en selecteer Opnieuw doorgaan .

Geef de gegevensset de naam 'MoviesCSV' en selecteer + Nieuw onder Gekoppelde service om een nieuwe gekoppelde service aan het bestand te maken.
Geef de details op voor uw opslagaccount dat u eerder hebt gemaakt in de sectie Vereisten en blader en selecteer het FilmsCSV-bestand dat u daar hebt geüpload.
Nadat u de gekoppelde service hebt toegevoegd, schakelt u het selectievakje Eerste rij als koptekst in en selecteert u VERVOLGENS OK om de bron toe te voegen.
Navigeer naar het tabblad Projectie van het venster met instellingen voor gegevensstromen en selecteer Gegevenstypen detecteren.
Selecteer nu de + na de bron in het venster van de gegevensstroomeditor en schuif omlaag om Sink te selecteren onder de sectie Bestemming , waarbij u een nieuwe sink toevoegt aan uw gegevensstroom.

Selecteer op het tabblad Sink voor de sink-instellingen die worden weergegeven nadat de sink is toegevoegd, de optie Inline voor het sinktype en vervolgens Delta voor het gegevenssettype Inline. Selecteer vervolgens uw Azure Data Lake Storage Gen2 voor de Linked-service.

Kies een mapnaam in uw opslagcontainer waar u wilt dat de service de Delta Lake maakt.
Ga ten slotte terug naar de ontwerpfunctie voor pijplijnen en selecteer Fouten opsporen om de pijplijn uit te voeren in de foutopsporingsmodus met alleen deze gegevensstroomactiviteit op het canvas. Hiermee wordt uw nieuwe Delta Lake in Azure Data Lake Storage Gen2 gegenereerd.
Selecteer nu in het menu Factory-resources aan de linkerkant + van het scherm om een nieuwe resource toe te voegen en selecteer vervolgens Gegevensstroom.

Net als voorheen selecteert u het MoviesCSV-bestand opnieuw als bron en selecteert u Vervolgens gegevenstypen opnieuw detecteren op het tabblad Projectie .
Nadat u de bron hebt gemaakt, selecteert u deze keer het + venster van de gegevensstroomeditor en voegt u een filtertransformatie toe aan uw bron.

Voeg een Filter op voorwaarde toe in het venster Filterinstellingen waarmee alleen filmrijen zijn toegestaan die overeenkomen met films uit 1950, 1960 en 1988.

Voeg nu een afgeleide kolomtransformatie toe om classificaties voor elke 1988-film bij te werken aan '1'.

Update, insert, delete, and upsertbeleidsregels worden gemaakt in de alter Row transform. Voeg een wijzigingsrijtransformatie toe na de afgeleide kolom.Uw beleidsregels voor het wijzigen van rijen moeten er als volgt uitzien.

Nu u het juiste beleid hebt ingesteld voor elk type wijzigingsrij, controleert u of de juiste updateregels zijn ingesteld voor de sinktransformatie.
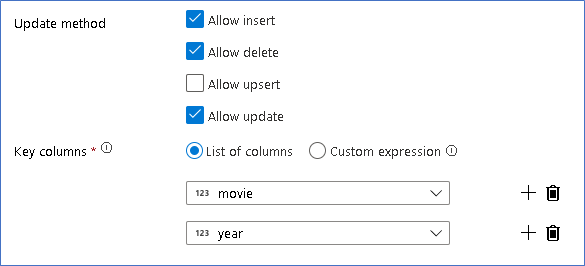
Hier gebruiken we de Delta Lake-sink voor je Azure Data Lake Storage Gen2-data lake en staan we het invoegen, bijwerken en verwijderen toe.
Houd er rekening mee dat de sleutelkolommen een samengestelde sleutel zijn die bestaat uit de kolom Primaire sleutel van film en jaar. Dit komt doordat we nepfilms van 2021 hebben gemaakt door de 1960 rijen te dupliceren. Dit voorkomt botsingen bij het opzoeken van de bestaande rijen door voor uniekheid te zorgen.
Voltooid voorbeeld downloaden
Hier is een voorbeeldoplossing voor de Delta-pijplijn met een gegevensstroom voor het bijwerken/verwijderen van rijen in het datameer.
Gerelateerde inhoud
Meer informatie over de expressietaal voor gegevensstromen.