Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is de volgende generatie van Azure Data Factory, met een eenvoudigere architectuur, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensintegratie, begint u met Fabric Data Factory. Bestaande ADF-workloads kunnen upgraden naar Fabric om toegang te krijgen tot nieuwe mogelijkheden voor gegevenswetenschap, realtime analyses en rapportage.
De Azure Databricks Notebook-activiteit in een pipeline voert een Databricks-notebook uit in uw Azure Databricks werkruimte. Dit artikel is gebaseerd op het artikel over activiteiten voor gegevenstransformatie , waarin een algemeen overzicht wordt weergegeven van de gegevenstransformatie en de ondersteunde transformatieactiviteiten. Azure Databricks is een beheerd platform voor het uitvoeren van Apache Spark.
U kunt een Databricks-notebook maken met een ARM-sjabloon met behulp van JSON of rechtstreeks via de Azure Data Factory Studio-gebruikersinterface. Raadpleeg de zelfstudie Een Databricks-notebookactiviteit uitvoeren met de databricks-notebookactiviteit in Azure Data Factory voor stapsgewijze instructies voor het maken van een Databricks-notebookactiviteit met behulp van de gebruikersinterface.
Een notebookactiviteit voor Azure Databricks toevoegen aan een pijplijn met gebruikersinterface
Voer de volgende stappen uit om een Notebook-activiteit te gebruiken voor Azure Databricks in een pijplijn:
Zoek naar Notebook in het deelvenster Activiteiten van de pijplijn en sleep een Notebook-activiteit naar het pijplijncanvas.
Selecteer de nieuwe notitieblokactiviteit op het canvas als deze nog niet is geselecteerd.
Selecteer het tabblad Azure Databricks om een nieuwe Azure Databricks gekoppelde service te selecteren of te maken waarmee de notebookactiviteit wordt uitgevoerd.
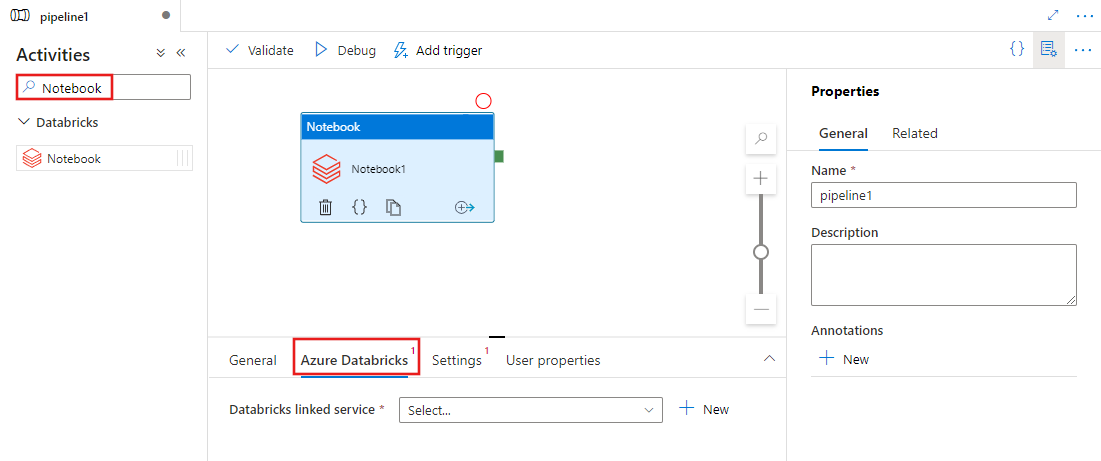
Selecteer het tabblad Settings en geef het notebookpad op dat moet worden uitgevoerd op Azure Databricks, optionele basisparameters die moeten worden doorgegeven aan het notebook en eventuele andere bibliotheken die op het cluster moeten worden geïnstalleerd om de taak uit te voeren.
Databricks Notebook-activiteitsdefinitie
Hier volgt de JSON-voorbeelddefinitie van een Databricks Notebook-activiteit:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Activiteitseigenschappen van Databricks Notebook
In de volgende tabel worden de JSON-eigenschappen beschreven die worden gebruikt in de JSON-definitie:
| Eigenschap | Beschrijving | Vereist |
|---|---|---|
| naam | Naam van de activiteit in de pijplijn. | Ja |
| beschrijving | Tekst die beschrijft wat de activiteit doet. | Nee |
| type | Voor Databricks Notebook Activity is het activiteitstype DatabricksNotebook. | Ja |
| naam van de gekoppelde service | Naam van de gekoppelde Databricks-service waarop het Databricks-notebook wordt uitgevoerd. Zie het artikel Compute als Gekoppelde Services voor meer informatie over deze gekoppelde service. | Ja |
| notebookPath | Het absolute pad van het notebook dat moet worden uitgevoerd in de Databricks-werkruimte. Dit pad moet beginnen met een slash. | Ja |
| baseParameters | Een matrix van sleutel-waardeparen. Basisparameters kunnen worden gebruikt voor elke uitvoering van activiteiten. Als het notebook een parameter gebruikt die niet is opgegeven, wordt de standaardwaarde van het notebook gebruikt. Meer informatie over parameters in Databricks Notebooks. | Nee |
| bibliotheken | Een lijst met bibliotheken die moeten worden geïnstalleerd op het cluster waarmee de taak wordt uitgevoerd. Dit kan een matrix van <tekenreeks, object> zijn. | Nee |
Ondersteunde bibliotheken voor Databricks-activiteiten
In de bovenstaande activiteiten definitie van Databricks geeft u deze bibliotheektypen op: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Zie de Databricks-documentatie voor bibliotheektypen voor meer informatie.
Parameters doorgeven tussen notebooks en pijplijnen
U kunt parameters doorgeven aan notebooks met behulp van de eigenschap BaseParameters in databricks-activiteit.
In bepaalde gevallen moet u mogelijk bepaalde waarden van notebook terugsturen naar de service, die kan worden gebruikt voor controlestroom (voorwaardelijke controles) in de service of worden gebruikt door downstreamactiviteiten (groottelimiet is 2 MB).
In uw notebook kunt u dbutils.notebook.exit("returnValue") aanroepen en de bijbehorende "returnValue" wordt geretourneerd naar de service.
U kunt de uitvoer in de service gebruiken met behulp van expressies zoals
@{activity('databricks notebook activity name').output.runOutput}.Belangrijk
Als u JSON-object doorgeeft, kunt u waarden ophalen door eigenschapsnamen toe te voegen. Voorbeeld:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Een bibliotheek uploaden in Databricks
U kunt de gebruikersinterface van de werkruimte gebruiken:
De gebruikersinterface van de Databricks-werkruimte gebruiken
Als u het dbfs-pad van de bibliotheek wilt ophalen die is toegevoegd met behulp van de gebruikersinterface, kunt u Databricks CLI gebruiken.
Normaal gesproken worden de Jar-bibliotheken opgeslagen onder dbfs:/FileStore/jars tijdens het gebruik van de gebruikersinterface. U kunt alles weergeven via de CLI: databricks fs ls dbfs:/FileStore/job-jars
U kunt ook de Databricks CLI gebruiken:
De bibliotheek kopiëren volgen met behulp van Databricks CLI
Databricks CLI gebruiken (installatiestappen)
Als u bijvoorbeeld een JAR naar dbfs wilt kopiëren:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar