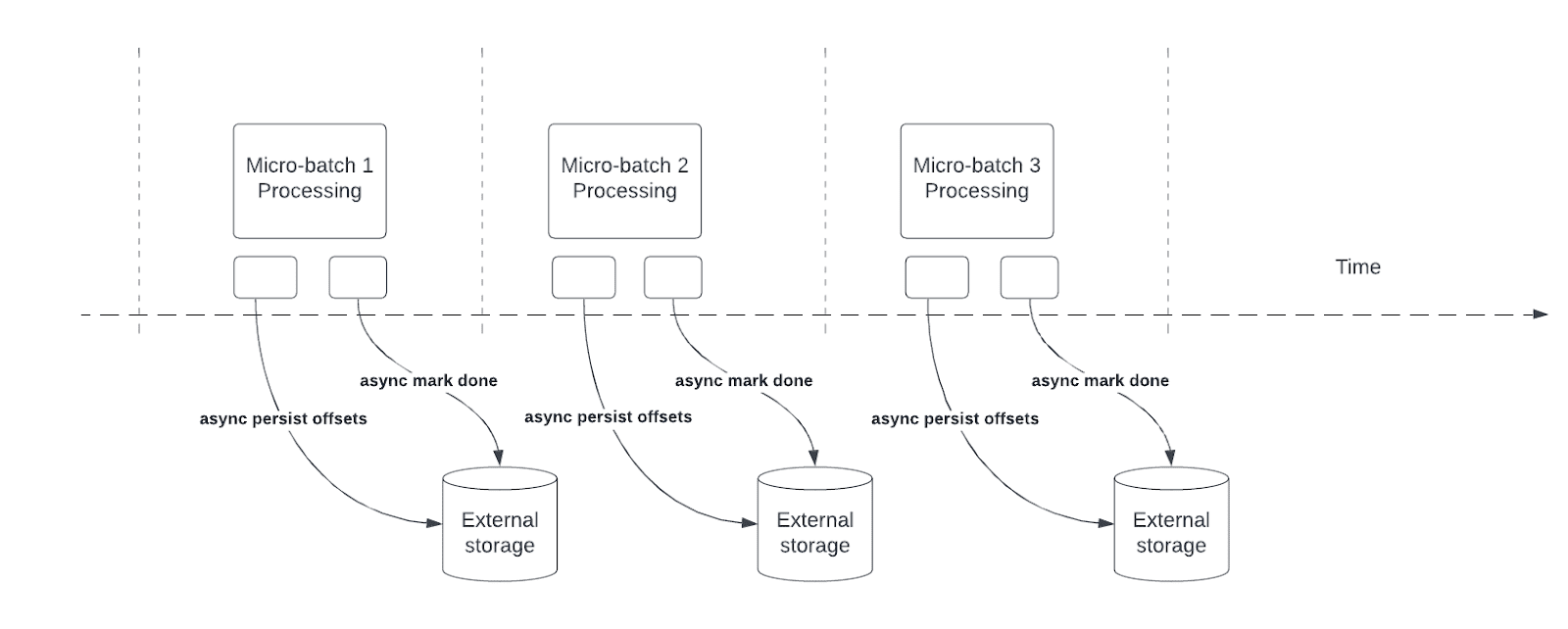
비동기 진행률 추적은 쿼리가 각 마이크로 일괄 처리에서 검사점 진행률을 비동기적으로 업데이트하고 데이터를 처리할 수 있도록 하여 구조적 스트리밍 파이프라인의 대기 시간을 줄입니다.
쿼리를 처리하는 동안 구조적 스트리밍은 오프셋을 유지 및 관리하여 각 마이크로 일괄 처리에서 offsetLogcommitLog 쿼리 진행률을 측정합니다. 비동기 진행률 추적이 없으면 데이터 처리가 완료될 때까지 계속할 수 없으므로 오프셋 관리 작업은 처리 대기 시간에 직접 영향을 줍니다.
메모
비동기 진행률 추적은 트리거와 Trigger.onceTrigger.availableNow 호환되지 않습니다. 구성할 경우, Trigger.once 혹은 Trigger.availableNow로 인해 구조적 스트리밍 쿼리가 실패합니다.
구성 옵션
| 선택 | 기본값 | 묘사 |
|---|---|---|
asyncProgressTrackingEnabled |
false |
비동기 진행률 추적을 사용하도록 설정할지 여부입니다. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
오프셋 및 완료 커밋에 대한 쓰기 사이의 간격(밀리초)입니다. |
비동기 진행 추적 활성화
비동기 진행률 추적을 사용하도록 설정하려면 다음으로 asyncProgressTrackingEnabled설정합니다true.
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
검사점 빈도를 사용하여 처리량 향상
기본 검사점 빈도 1000 (밀리초)는 대부분의 쿼리에서 처리량이 좋습니다. 오프셋 관리 작업이 비동기 진행률 추적에서 처리할 수 있는 것보다 빠르게 수행되면 오프셋 관리 작업의 백로그가 빌드됩니다. 백로그가 더 이상 증가하지 않도록 비동기 진행률 추적은 데이터 처리를 차단하거나 느리게 하여 예상되는 대기 시간 이점을 침식시킬 수 있습니다.
이 시나리오에서 Databricks는 검사점 간격을 늘리는 것이 좋습니다.
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
메모
검사점 간격 시간에 따라 오류 복구 시간이 증가합니다. 오류가 발생할 경우 파이프라인은 이전에 성공한 검사점 이후 모든 데이터를 다시 처리해야 합니다. 프로덕션 환경에서 이러한 변경을 하기 전에, 정기적인 처리 시 더 짧은 지연 시간과 오류 발생 시 복구 시간 간의 균형을 고려하세요.
비동기 진행률 추적 끄기
비동기 진행률 추적을 사용하는 경우 스트림은 모든 일괄 처리에 대한 검사점 진행률을 보장하지 않습니다. 이 기능을 해제하려면 먼저 검사점 진행률을 확인해야 합니다.
끄려면 다음 단계를 수행합니다.
asyncProgressTrackingEnabled를true로 설정하고asyncProgressTrackingCheckpointIntervalMs를0로 설정하여 두 개 이상의 마이크로 배치를 처리합니다.Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()쿼리를 중지합니다.
Python
query.stop()Scala
query.stop()비동기 진행률 추적을 해제하고 쿼리를 다시 시작합니다.
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
위의 단계를 수행하지 않고 비동기 진행률 추적을 해제하면 다음 오류가 발생할 수 있습니다.
java.lang.IllegalStateException: batch x doesn't exist
드라이버 로그에 다음 오류가 표시될 수 있습니다.
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Limitations
- Kafka 싱크의 경우 비동기 진행 추적은 오직 상태가 없는 파이프라인을 지원합니다.
- 일괄 처리에 대한 오프셋 범위는 실패 시 변경 될 수 있으므로 비동기 진행률 추적은 정확히 한 번 종단 간 처리를 보장하지 않습니다. Kafka와 같은 일부 싱크는 정확히 한 번의 보장을 제공하지 않습니다.