이 가이드의 끝부분에서는 샘플 데이터가 포함된 실행 중인 Postgres 데이터베이스를 갖게 되며, 애플리케이션에 연결하거나 Databricks Lakehouse와 통합할 준비가 됩니다.
단계: (1) 프로젝트 → 만들기 (2) 연결 → (3) 테이블 만들기
1단계: 첫 번째 프로젝트 만들기
앱 전환기에서 Lakebase 앱을 엽니다.

자동 크기 조정을 선택하여 Lakebase 자동 크기 조정 UI에 액세스합니다.
새 프로젝트를 클릭합니다. 프로젝트에 이름을 지정하고 Postgres 버전을 선택합니다. 프로젝트는 단일 production 분기, 기본 databricks_postgres 데이터베이스 및 분기에 대해 구성된 컴퓨팅 리소스를 사용하여 만들어집니다.

컴퓨팅이 활성화되는 데 몇 분 정도 걸릴 수 있습니다.
production 분기의 컴퓨팅은 기본적으로 24시간의 비활성 시간 제한과 함께 scale-to-zero가 활성화되어 있지만, 필요한 경우 이 설정을 변경할 수 있습니다.
프로젝트의 지역은 자동으로 작업 영역 지역으로 설정됩니다. 지역 가용성을 참조하세요.
자세한 정보:프로젝트 만들기 | 자동 크기 조정 | 0으로 크기 조정
2단계: 데이터베이스에 연결
프로젝트에서 프로덕션 분기를 선택하고 연결을 클릭합니다. 연결 문자열은 모든 표준 Postgres 클라이언트(psql, pgAdmin, DBeaver 또는 애플리케이션 프레임워크)에서 작동합니다.

Databricks ID와 연결하려면, 연결 대화 상자에서 psql 코드 조각을 복사하고, 메시지가 표시되면 OAuth 토큰을 붙여넣습니다.
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
자세한 정보: 연결 빠른 시작 | psql | pgAdmin | Postgres 클라이언트
3단계: 첫 번째 테이블 만들기
Lakebase SQL 편집기에서는 샘플 SQL이 미리 로드됩니다. 프로젝트에서 프로덕션 분기를 선택하고 SQL 편집기를 열고 제공된 문을 실행하여 테이블을 만들고 playing_with_lakebase 샘플 데이터를 삽입합니다.
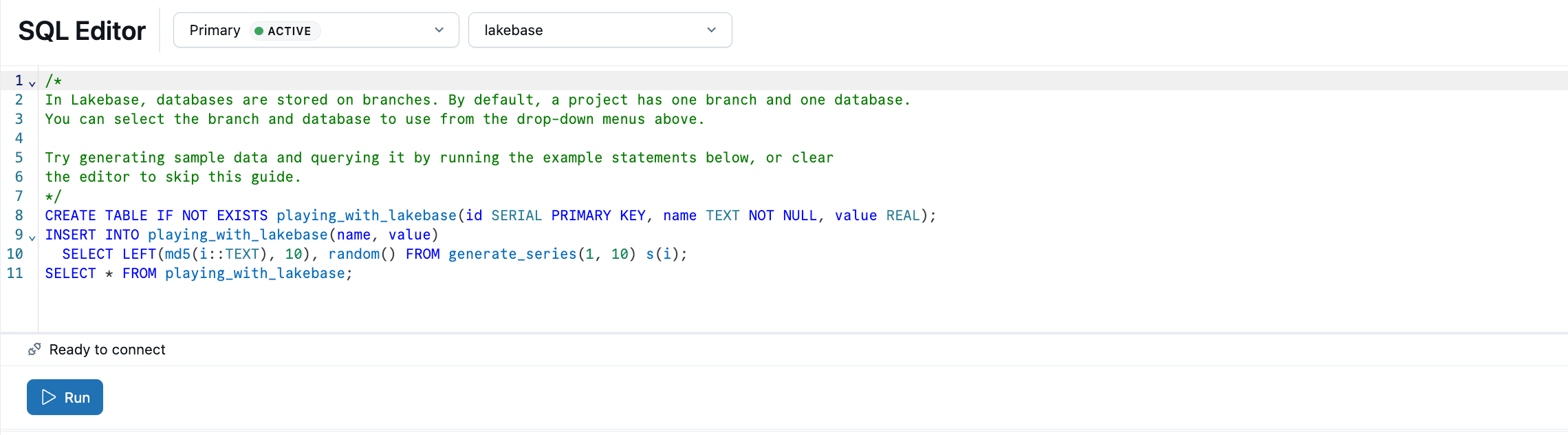
자세한 정보: SQL 편집기 | 테이블 편집기 | Postgres 클라이언트
다음 단계
| 다음 단계: | Description |
|---|---|
| 레이크하우스 데이터 제공 | 대기 시간이 짧은 앱 읽기를 위해 Unity 카탈로그 테이블을 Postgres에 동기화합니다. |
자세히 알아보기
| Resource | Description |
|---|---|
| 앱 빌드 | 자동 Lakebase 연결을 사용하여 Databricks 앱을 배포합니다. |
| Unity 카탈로그에 등록 | 통합 거버넌스, 계보 및 원본 간 쿼리. |
| 핵심 개념 | 자동 크기 조정, 0으로 크기 조정, 분기 및 작동 방식 |
| 프로젝트 | 아키텍처, 분기 모델 및 제품 개요입니다. |