데이터 오케스트레이션 및 자동 로더에 대해 SDP(Lakeflow Spark 선언적 파이프라인)를 사용하여 새 파이프라인을 만드는 방법을 알아봅니다. 이 자습서에서는 데이터를 정리하고 상위 100명의 사용자를 찾기 위한 쿼리를 만들어 샘플 파이프라인을 확장합니다.
이 자습서에서는 Lakeflow 파이프라인 편집기를 사용하여 다음을 수행합니다.
- 기본 폴더 구조를 사용하여 새 파이프라인을 만들고 샘플 파일 집합으로 시작합니다.
- 기대치를 사용하여 데이터 품질 제약 조건을 정의합니다.
- 편집기 기능을 사용하여 새 변환으로 파이프라인을 확장하여 데이터에 대한 분석을 수행합니다.
요구 사항
이 자습서를 시작하기 전에 다음을 수행해야 합니다.
- Azure Databricks 작업 영역에 로그인합니다.
- 작업 영역에 Unity 카탈로그를 사용하도록 설정합니다.
- 컴퓨팅 리소스를 만들거나 컴퓨팅 리소스에 액세스할 수 있는 권한이 있습니다.
- 카탈로그에 새 스키마를 만들 수 있는 권한이 있습니다. 필요한 사용 권한은
ALL PRIVILEGES또는USE CATALOG및CREATE SCHEMA입니다.
1단계: 파이프라인 만들기
이 단계에서는 기본 폴더 구조 및 코드 샘플을 사용하여 파이프라인을 만듭니다. 코드 샘플은 users 샘플 데이터 원본의 wanderbricks 테이블을 사용합니다.
Azure Databricks 작업 영역에서
 New을 클릭합니다. 그런 다음
New을 클릭합니다. 그런 다음  ETL 파이프라인. 그러면 다음과 같은
ETL 파이프라인. 그러면 다음과 같은 New Pipeline <date> <time>기본 파이프라인 이름이 있는 파이프라인 편집기가 열립니다.(선택 사항) 이름을 선택하고 파이프라인의 설명이 포함된 이름을 입력합니다.
(선택 사항) 이름 오른쪽에서 카탈로그 및 스키마를 클릭하여 다른 기본값을 설정합니다.
(선택 사항) 만든
my_transformation원본 파일의 언어 드롭다운 목록에서 Python 또는 SQL을 선택하여 파일에 대한 언어를 설정합니다. 을 클릭합니다.샘플 코드를 사용합니다.
을 클릭합니다.샘플 코드를 사용합니다.선택한 언어의 샘플 코드는
transformations폴더의my_transformation소스 파일에 있습니다. 출력 데이터 세트가 아직 만들어지지 않았으며 화면 오른쪽에 있는 파이프라인 그래프 가 비어 있습니다.파이프라인 코드(폴더의 코드
transformations)를 실행하려면 화면의 오른쪽 위에 있는 파이프라인 실행을 클릭합니다.실행이 완료되면 작업 영역의 아래쪽에 새로 생성된 두 개의 테이블(
sample_users_<date_time>및sample_aggregation_<date_time>)이 표시됩니다. 이제 작업 영역 오른쪽의 파이프라인 그래프에 두 개의 테이블이 표시되며,sample_users이sample_aggregation의 소스라는 점도 함께 보여 줍니다. 전체sample_users_<date_time>테이블 이름을 적어 두세요. 다음 단계에서 참조합니다.
2단계: 데이터 품질 검사 적용
이 단계에서는 테이블에 데이터 품질 검사를 추가합니다 sample_users .
파이프라인 기대치를 사용하여 데이터를 제한합니다. 이 경우 유효한 전자 메일 주소가 없는 모든 사용자 레코드를 삭제하고 정리된 테이블을 다음과 같이 users_cleaned출력합니다.
왼쪽의 파이프라인 자산 브라우저 에서
을 클릭하고 변환을 선택합니다.새 변환 파일 만들기 대화 상자에서 다음을 선택합니다.
Python 또는Language SQL 중 하나를 선택합니다. 이전 선택 항목과 일치하지 않아도 됩니다. - 파일 이름을 지정합니다. 이 경우 을 선택합니다
users_cleaned. - 대상 경로의 경우 기본값을 그대로 둡니다.
- 데이터 세트 형식의 경우 [없음]을 선택한 상태로 두거나 구체화된 보기를 선택합니다. 구체화된 뷰를 선택하면 샘플 코드가 생성됩니다.
만들기를 클릭하여 변환 코드 파일을 만듭니다.
새 코드 파일에서 다음과 일치하도록 코드를 편집합니다(이전 화면에서 선택한 항목에 따라 SQL 또는 Python 사용). 이전 섹션에 있는
sample_users테이블의 전체 이름으로sample_users_<date_time>을 바꾸세요.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )파이프라인 실행을 클릭하여 파이프라인을 업데이트합니다. 이제 세 개의 테이블이 있어야 합니다.
3단계: 상위 사용자 분석
다음으로, 만든 예약 수만큼 상위 100명의 사용자를 가져옵니다.
wanderbricks.bookings 테이블을 users_cleaned 구체화된 뷰에 조인합니다.
왼쪽의 파이프라인 자산 브라우저에서
을 클릭하고 변환을 선택합니다.새 변환 파일 만들기 대화 상자에서 다음을 선택합니다.
Python 또는Language SQL 중 하나를 선택합니다. 이전 선택 항목과 일치하지 않아도 됩니다. - 파일 이름을 지정합니다. 이 경우 을 선택합니다
users_and_bookings. - 대상 경로의 경우 기본값을 그대로 둡니다.
- 데이터 세트 형식의 경우 없음을 선택한 상태로 둡니다.
만들기를 클릭하여 변환 코드 파일을 만듭니다.
새 코드 파일에서 다음과 일치하도록 코드를 편집합니다(이전 화면에서 선택한 항목에 따라 SQL 또는 Python 사용).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )파이프라인 실행을 클릭하여 데이터 세트를 업데이트합니다. 실행이 완료되면 파이프라인 그래프 에서 새
users_and_bookings테이블을 포함하여 4개의 테이블이 있음을 확인할 수 있습니다.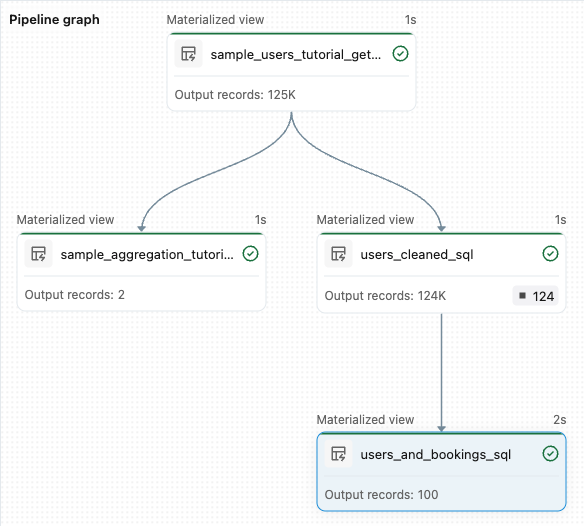
다음 단계
이제 Lakeflow 파이프라인 편집기의 일부 기능을 사용하는 방법을 알아보고 파이프라인을 만들었으므로 다음에 대해 자세히 알아볼 수 있는 몇 가지 다른 기능은 다음과 같습니다.
파이프라인을 만드는 동안 변환 작업 및 디버깅을 위한 도구:
- 선택적 실행
- 데이터 미리 보기
- 대화형 파이프라인 그래프(파이프라인 의 데이터 세트 그래프)
편집기에서 직접 효율적인 공동 작업, 버전 제어 및 CI/CD 통합을 위한 기본 제공 선언적 자동화 번들 통합: