이 페이지에서는 Azure Databricks 작업 영역에서 데이터를 쿼리하고 google Sheets용 Databricks Connector 사용하여 Google Sheets로 가져오는 방법을 설명합니다. 테이블을 직접 선택하고, SQL 쿼리를 작성하고, 매개 변수를 추가하고, 피벗 테이블을 만들 수 있습니다. 커넥터는 결과를 새로 고치고 기존 쿼리를 다시 사용할 수 있도록 모든 쿼리를 가져오기로 자동으로 저장합니다.
사전 요구 사항
가져오기 방법 선택
테이블을 선택하거나 SQL 쿼리를 작성하여 Azure Databricks Google Sheets로 데이터를 가져올 수 있습니다. 데이터를 가져온 후 쿼리는 시트에 연결됩니다. 이 커넥터는 최대 1,000만 개의 셀에 대한 Google Sheets 제한까지 가져올 수 있도록 지원합니다.
시트 이름을 변경하면 매핑이 중단됩니다. 이름 변경을 처리하는 방법에 대한 자세한 내용은 제한 사항을 참조하세요.
중요합니다
"데이터 선택"을 사용하여 Unity 카탈로그 메트릭 뷰를 가져오는 경우 Unity 카탈로그 메트릭이 피벗 데이터를 나타내기 때문에 피벗 테이블로만 가져올 수 있습니다.
Warning
적용된 테이블 서식을 제거하거나 수정하지 마세요. Google Sheets 테이블 식별자는 가져오기를 새로 고치는 데 사용됩니다. 서식을 제거하면 새로 고침 오류가 발생합니다.
시작할 가져오기 방법을 선택합니다.
데이터 선택
Azure Databricks 테이블에서 데이터를 가져오려면 다음을 수행합니다.
- Google Sheets Databricks 커넥터 사이드바의 새 가져오기에서 가져오기 메서드에 대해 데이터 선택을 선택합니다.
- 카탈로그 아래에서 카탈로그, 스키마 및 테이블 드롭다운 메뉴를 사용하여 가져올 테이블을 검색합니다.
- 필요에 따라 자산 이름을 업데이트하여 이 가져오기의 이름을 변경합니다.
- 필요에 따라 필드 아래에서 포함하거나 제외할 열을 선택합니다.
- 필요에 따라 피벗 테이블로 가져올 수 있습니다.
- 필터를 추가하려면 필터 아래에서 + 필터를 클릭합니다. 필터를 적용할 열 과 필터 유형을 선택합니다.
- 필요에 따라 행 제한을 설정하여 가져올 행 수에 대한 제한을 설정합니다. 이 제한은 기본적으로 사용하도록 설정되며 1,000개의 행으로 설정됩니다.
-
출력 대상에서 쿼리 결과를 새 시트에 저장할지 아니면 현재 시트에 저장할지 선택합니다.
- 새 시트를 선택하는 경우 시트의 이름을 입력합니다.
- 현재 시트를 선택하는 경우 데이터 추가를 시작할 셀을 지정합니다.
- 저장 및 가져오기를 클릭하여 시트를 채웁다.
SQL 쿼리 작성
새 SQL 쿼리를 작성하려면 다음을 수행합니다.
- Google Sheets Databricks 커넥터 사이드바의 새 가져오기에서 SQL 쓰기를 선택합니다.
- Databricks는 식별할 수 있도록 쿼리의 이름을 입력하는 것이 좋습니다.
- 카탈로그, 스키마 및 테이블을 탐색할 수 있습니다.
- 쿼리 텍스트에서 SQL 쿼리를 입력합니다.
- 필요에 따라 쿼리 매개 변수를 추가할 수 있습니다.
-
출력 대상에서 쿼리 결과를 새 시트에 저장할지 아니면 현재 시트에 저장할지 선택합니다.
- 새 시트를 선택하는 경우 시트의 이름을 입력합니다.
- 현재 시트를 선택하는 경우 데이터 추가를 시작할 셀을 지정합니다.
- 저장 및 가져오기를 클릭하여 쿼리를 실행하고 시트를 채웁다.
메모
쿼리 실행 시간이 15분 후에 초과됩니다. 쿼리가 이 제한을 초과하면 자동으로 취소됩니다. 큰 결과 집합의 경우 처음 1,000개의 행이 즉시 작성되고 나머지 데이터는 점진적으로 페치됩니다. 데이터 가져오기가 중단되면 부분 결과가 시트에 남아 있으며 쿼리를 다시 실행하여 지울 수 있습니다.

쿼리 매개 변수 추가(선택 사항)
SQL 쿼리에 쿼리 매개 변수를 추가하려면 다음을 수행합니다.
쿼리에 적어도 하나 이상의 쿼리 매개 변수가
:parameter_name형식으로 포함되어 있는지 확인하십시오. 쿼리 매개 변수에 대한 자세한 내용은 명명된 매개 변수 표식 사용을 참조하세요.+ 매개 변수 추가를 클릭합니다.
첫 번째 상자에 매개 변수를 입력합니다. 매개 변수 이름이 쿼리 편집기에서 입력한 이름과 일치하는지 확인합니다.
시트 이름 뒤의 느낌표를 포함하여 두 번째 상자에 매개 변수 값의 시트 이름과 셀 위치를 입력합니다.
쿼리 매개 변수를 더 추가하려면 + 매개 변수 추가 를 다시 클릭합니다.
예를 들어 다음 쿼리에는 시트
:trip_distance, 셀 H1에 정의된 쿼리 매개 변수sheet_1가 포함됩니다.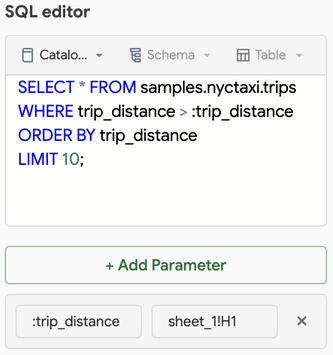
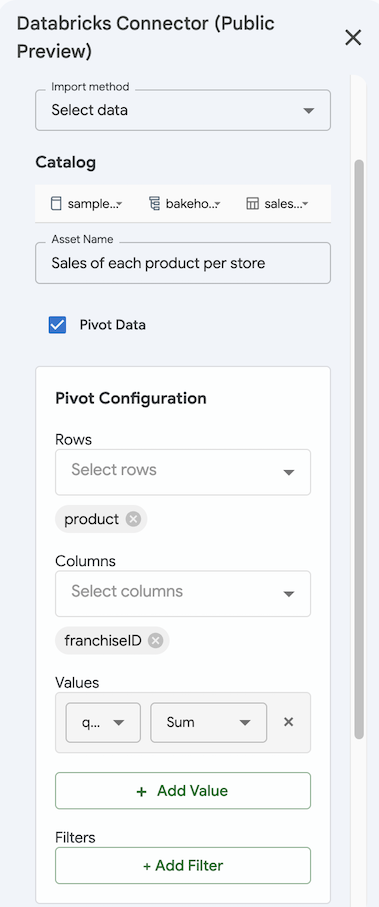
피벗 테이블로 가져오기(선택 사항)
데이터를 피벗 테이블로 가져오려면 다음을 수행합니다.
- 데이터 선택 메서드를 사용하여 데이터를 가져오려면 피벗 테이블 확인란을 선택합니다.
- 피벗 구성에서 피벗 테이블의 행과 열 차원을 선택합니다.
- 집계 기준 값을 지정합니다. + 값 추가를 클릭하고 열 및 집계 메서드를 선택합니다.
- 필요에 따라 + 필터 추가 를 클릭하여 필터를 추가하고 열 및 필터 유형을 선택합니다.
- 저장 및 가져오기를 클릭하여 결과를 피벗 테이블로 가져옵니다. 가져온 피벗 테이블은 자동으로 새 시트에 추가됩니다.
가져온 데이터 관리
Azure Databricks 가져오는 데이터를 관리하려면 다음을 수행합니다.
커넥터 사이드바에서 저장된 가져오기 탭을 클릭합니다.
가져온 데이터를 수동으로 새로 고치려면:
- 단일 가져오기 새로 고침: 쿼리 이름 옆에 있는 새로 고침 아이콘을 클릭합니다.
- 모든 가져오기 새로 고침: 저장된 가져오기 탭 위쪽의 일정 아이콘 옆에 있는 새로 고침 아이콘을 클릭합니다.
되풀이 일정에 따라 가져오기를 자동으로 새로 고치려면 Google Sheets에서 데이터 새로 고침 예약을 참조하세요.
가져오기가 연결된 시트를 보려면
 을 클릭합니다.> 쿼리 이름 옆에 있는 시트로 이동합니다.
을 클릭합니다.> 쿼리 이름 옆에 있는 시트로 이동합니다.가져오기를 편집하려면
을 클릭합니다.> 쿼리 이름 옆에서 편집합니다.가져오기를 삭제하려면
을 클릭합니다.> 쿼리 이름 옆에 삭제합니다. 이렇게 하면 Google Sheets로 가져온 데이터가 아니라 쿼리가 삭제됩니다. 가져온 데이터를 수동으로 삭제해야 합니다.

의미 공유
추가 기능은 Google Sheet를 공유하는 기능에 영향을 주지 않습니다. 그러나 파일을 공유하는 방식은 받는 사람이 추가 기능을 사용하여 수행할 수 있는 작업에 영향을 줍니다.
- 뷰어 또는 주석 처리기 역할이 있는 받는 사람은 추가 기능에 액세스할 수 없습니다.
- 편집기 역할과 동등한 데이터 자산 액세스 권한이 있는 받는 사람은 Google 계정으로 추가 기능을 사용할 수 있습니다. 소유자와 마찬가지로 커넥터를 사용할 수 있습니다.
- 편집기 역할과 기본 리소스에 대한 동일한 액세스 권한이 있는 받는 사람은 동일한 Azure Databricks 작업 영역에 로그인한 경우 가져오기를 새로 고칠 수 있습니다.
제한점
기존 가져오기에 연결된 시트의 이름을 바꾸거나 삭제하면 가져오기를 새로 고치지 못하게 됩니다. 이 문제를 해결하려면 다음 중 하나를 수행합니다.
- 정확히 동일한 이름으로 시트를 다시 만듭니다.
- 원본으로 쿼리 선택을 선택하고 가져오기를 다시 사용하고 새로 저장을 클릭하여 새 가져오기를 만듭니다.
두 쿼리가 동일하거나 겹치는 범위에 매핑되는 경우 추가 기능은 가장 최근에 실행된 쿼리의 결과를 표시합니다. 이렇게 하면 이전에 가져온 데이터를 덮어씁니다.