적용 대상: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
팁
Microsoft Fabric의 데이터 팩토리는 더 간단한 아키텍처, 기본 제공 AI 및 새로운 기능을 갖춘 차세대 Azure 데이터 팩토리입니다. 데이터 통합을 접하는 경우 Fabric Data Factory부터 시작합니다. 기존 ADF 워크로드는 Fabric 업그레이드하여 데이터 과학, 실시간 분석 및 보고 전반에 걸쳐 새로운 기능에 액세스할 수 있습니다.
- Fabric 무료 평가판을 시작합니다.
Microsoft Fabric의 Data Factory로 Azure Data Factory를 업그레이드합니다
Azure Data Factory 또는 Synapse Analytics 작업 영역의 파이프라인은 연결된 컴퓨팅 서비스를 사용하여 연결된 스토리지 서비스의 데이터를 처리합니다. 일련의 작업이 포함되어 있으며, 각 작업은 특정 처리 작업을 실행합니다. 이 문서에서는 U-SQL 스크립트를 Azure Data Lake Analytics 컴퓨팅 연결 서비스에서 실행하는 Data Lake Analytics U-SQL 작업을 설명합니다.
Data Lake Analytics U-SQL 작업을 사용하여 파이프라인을 만들기 전에 Azure Data Lake Analytics 계정을 만듭니다. Azure Data Lake Analytics에 대한 자세한 내용은 Azure Data Lake Analytics 시작하기를 참조하세요.
UI를 사용하여 파이프라인에 Azure Data Lake Analytics U-SQL 작업 추가
파이프라인에서 Azure Data Lake Analytics U-SQL 작업을 사용하려면 다음 단계를 완료합니다.
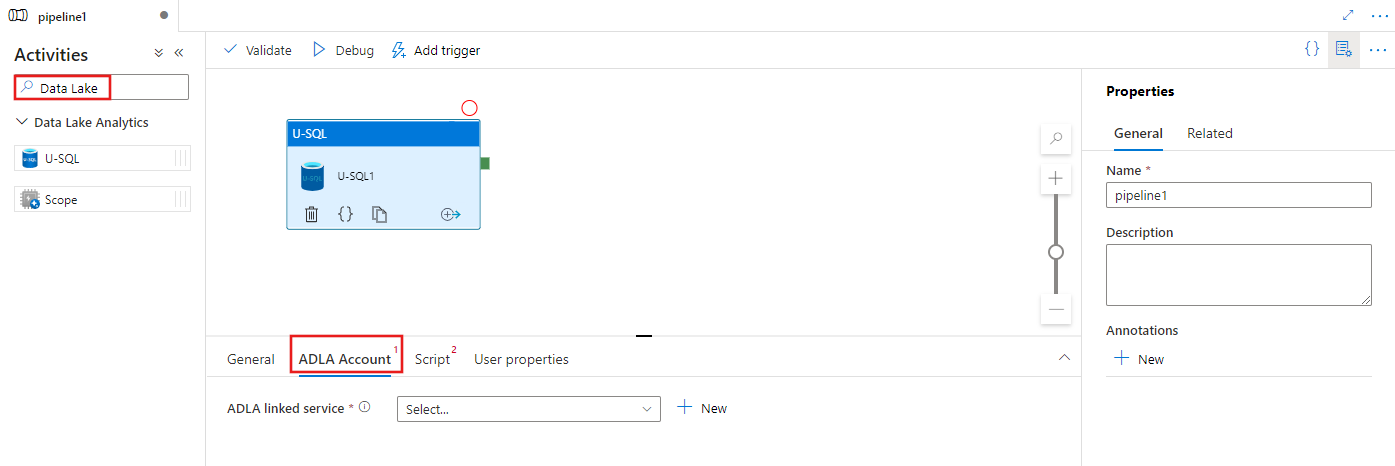
파이프라인 활동 창에서 데이터 레이크 검색하고 U-SQL 작업을 파이프라인 캔버스로 끌어옵니다.
아직 선택되지 않은 경우 캔버스에서 새 U-SQL 작업을 선택합니다.
ADLA 계정 탭을 선택하여 U-SQL 작업을 실행하는 데 사용할 새 Azure Data Lake Analytics 연결된 서비스를 선택하거나 만듭니다.
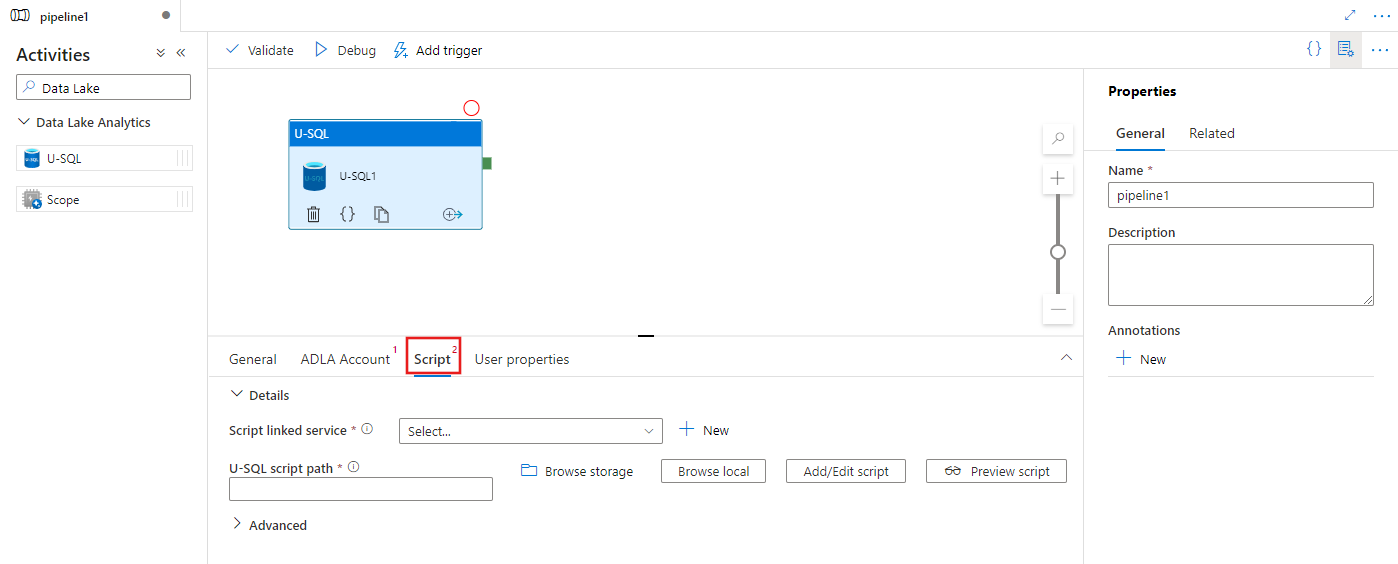
스크립트 탭을 선택하여 새 스토리지 연결된 서비스 및 스크립트를 호스트할 스토리지 위치 내의 경로를 선택하거나 만듭니다.
연결된 서비스 Azure Data Lake Analytics
Azure Data Lake Analytics 컴퓨팅 서비스를 Azure Data Factory 또는 Synapse Analytics 작업 영역에 연결하는 Azure Data Lake Analytics 연결된 서비스를 만듭니다. 파이프라인의 Data Lake Analytics U-SQL 작업은 이 연결된 서비스를 참조합니다.
다음 표에는 JSON 정의에서 사용하는 일반 속성에 대한 설명이 나와 있습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| 유형 | type 속성은 AzureDataLakeAnalytics로 설정해야 합니다. | 예 |
| accountName | Azure Data Lake Analytics 계정 이름입니다. | 예 |
| dataLakeAnalyticsUri | Azure Data Lake Analytics URI입니다. | 아니요 |
| subscriptionId | Azure 구독 ID | 아니요 |
| resourceGroupName | 리소스 그룹 이름 Azure | 아니요 |
서비스 주체 인증
Azure Data Lake Analytics 연결된 서비스에는 Azure Data Lake Analytics 서비스에 연결하려면 서비스 주체 인증이 필요합니다. 서비스 주체 인증을 사용하려면, Microsoft Entra ID에 애플리케이션 엔터티를 등록하고, 애플리케이션이 사용하는 Data Lake Analytics 및 데이터 레이크 스토어에 대한 액세스 권한을 부여해야 합니다. 자세한 단계는 서비스 간 인증을 참조하세요. 연결된 서비스를 정의하는 데 사용되므로 다음 값을 적어둡니다.
- 애플리케이션 ID
- 애플리케이션 키
- 테넌트 ID
사용자 추가 마법사를 사용하여 Azure Data Lake Analytics에 서비스 주체 권한을 부여합니다.
다음 속성을 지정하여 서비스 주체 인증을 사용합니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| servicePrincipalId | 애플리케이션의 클라이언트 ID를 지정합니다. | 예 |
| servicePrincipalKey | 애플리케이션의 키를 지정합니다. | 예 |
| 테넌트 | 애플리케이션이 있는 테넌트 정보(도메인 이름 또는 테넌트 ID)를 지정합니다. Azure 포털의 오른쪽 위 모서리에 마우스를 가져가서 검색할 수 있습니다. | 예 |
예제: 서비스 주체 인증
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
연결된 서비스에 대한 자세한 내용은 컴퓨팅 연결 서비스 문서를 참조하세요.
Data Lake Analytics U-SQL 작업
다음 JSON 코드 조각은 Data Lake Analytics U-SQL 작업을 사용하여 파이프라인을 정의합니다. 활동 정의에는 이전에 만든 Azure Data Lake Analytics 연결된 서비스에 대한 참조가 있습니다. Data Lake Analytics U-SQL 스크립트를 실행하기 위해 서비스는 지정한 스크립트를 Data Lake Analytics 제출하고, Data Lake Analytics 가져오고 출력하는 데 필요한 입력 및 출력이 스크립트에 정의됩니다.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
다음 표에는 이 작업과 관련된 속성 이름과 설명이 나와 있습니다.
| 속성 | 설명 | 필수 |
|---|---|---|
| 이름 | 파이프라인의 작업 이름입니다. | 예 |
| 설명 | 작업이 어떤 일을 수행하는지 설명하는 텍스트입니다. | 아니요 |
| 종류 | Data Lake Analytics U-SQL 작업의 경우 활동 유형은 DataLakeAnalyticsU-SQL입니다. | 예 |
| 연결된서비스명 | Azure Data Lake Analytics 연결된 서비스입니다. 이 연결된 서비스에 대한 자세한 내용은 컴퓨팅 연결 서비스 문서를 참조하세요. | 예 |
| 스크립트 경로 | U-SQL 스크립트가 포함된 폴더 경로입니다. 파일 이름은 대/소문자를 구분합니다. | 예 |
| scriptLinkedService | 스크립트가 포함된 Azure 데이터 레이크 Store 또는 Azure Storage 연결하는 연결된 서비스 | 예 |
| 병렬성의 정도 | 작업을 실행하는 데 동시에 사용되는 최대 노드 수입니다. | 아니요 |
| 우선순위 | 대기열에 있는 모든 작업 중에서 먼저 실행해야 하는 작업을 결정합니다. 번호가 낮을수록 우선 순위가 높습니다. | 아니요 |
| 매개 변수 | U-SQL 스크립트에 전달할 매개 변수입니다. | 아니요 |
| runtimeVersion | 사용할 U-SQL 엔진의 런타임 버전입니다. | 아니요 |
| 컴파일 모드 | U-SQL의 컴파일 모드 다음과 같은 값 중 하나여야 합니다. 의미 체계: 의미 체계 확인 및 필요한 온전성 검사만을 수행합니다 전체: 구문 검사, 최적화, 코드 생성 등을 비롯하여 전체 컴파일을 수행합니다. SingleBox: SingleBox에 TargetType 설정을 사용하여 전체 컴파일을 수행합니다. 이 속성에 대한 값을 지정하지 않으면 서버가 최적의 컴파일 모드를 결정합니다. |
아니요 |
스크립트 정의에 대해서는 SearchLogProcessing.txt를 참조하세요.
샘플 U-SQL 스크립트
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
위의 스크립트 예제에서 스크립트에 대한 입력 및 출력은 @in 및 @out 매개 변수에서 정의됩니다. U-SQL 스크립트의 @in 및 @out 매개 변수 값은 서비스가 ‘parameters’ 섹션을 사용하여 동적으로 전달합니다.
degreeOfParallelism 및 우선 순위와 같은 다른 속성은 물론 Azure Data Lake Analytics 서비스에서 실행되는 작업에 대한 파이프라인 정의에서도 지정할 수 있습니다.
동적 매개 변수
샘플 파이프라인 정의에서 in 및 out 매개 변수는 하드 코드된 값으로 할당됩니다.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
동적 매개 변수를 대신 사용할 수 있습니다. 예시:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
이 경우 입력 파일은 여전히 /datalake/input 폴더에서 가져오며 출력 파일은 /datalake/output 폴더에 생성됩니다. 파일 이름은 파이프라인이 트리거될 때 전달되는 창 시작 시간을 기준으로 동적입니다.
관련 콘텐츠
다른 방법으로 데이터를 변환하는 방법을 설명하는 다음 문서를 참조하세요.