적용 대상: Azure Logic Apps(사용량 + 표준)
B2B(비즈니스 간) 통합 워크플로의 경우 이 데이터를 거래 파트너와 교환하기 전에 XML과 플랫 파일 형식 간에 데이터를 변환해야 하는 경우가 많습니다.
이 가이드에서는 플랫 파일 기본 제공 커넥터 작업을 사용하여 XML을 인코딩 또는 디코딩하고 샘플 데이터에서 BizTalk 호환 플랫 파일 스키마를 생성하는 방법을 보여 줍니다.
커넥터 기술 참조
플랫 파일 커넥터에는 다음 인코딩, 디코딩 및 스키마 생성 작업이 포함됩니다.
| 조치 | Consumption | 스탠다드 |
|---|---|---|
| 플랫 파일 인코딩 | Yes | Yes |
| 플랫 파일 디코딩 | Yes | Yes |
| 플랫 파일 스키마 생성 | No | Yes |
| 논리 앱 | 환경 |
|---|---|
| Consumption | 다중 테넌트 Azure Logic Apps |
| 스탠다드 | 싱글 테넌트 Azure Logic Apps, App Service Environment v3 (Windows 플랜만 해당) 및 하이브리드 배포 |
자세한 내용은 통합 계정 기본 제공 커넥터를 참조하세요.
필수 구성 요소
Azure 계정 및 구독 무료 Azure 계정을 가져옵니다.
플랫 파일 작업을 사용하려는 논리 앱 리소스 및 워크플로입니다.
플랫 파일 작업에는 트리거가 포함되지 않습니다. 워크플로는 트리거로 시작하거나 모든 작업을 사용하여 원본 XML을 가져올 수 있습니다.
이 문서의 예제에서는 HTTP 요청을 받을 때라는 요청 트리거를 사용합니다.
자세한 내용은 다음을 참조하세요.
엔터프라이즈 통합 및 B2B 워크플로에 대한 아티팩트를 정의하고 저장하는 통합 계정 리소스 입니다.
통합 계정과 논리 앱 리소스는 모두 동일한 Azure 구독 및 Azure 지역에 있어야 합니다.
플랫 파일 작업을 시작하기 전에 소비 논리 앱을 연결하거나 표준 논리 앱을 통합 계정에 연결하여 거래 업체 및 계약과 같은 아티팩트 작업을 수행해야 합니다. 통합 계정을 여러 소비 또는 표준 논리 앱 리소스에 연결하여 동일한 아티팩트를 공유할 수 있습니다.
팁 (조언)
표준 워크플로에서 거래 업체 및 계약과 같은 B2B 아티팩트를 사용하지 않는 경우 통합 계정이 필요하지 않을 수 있습니다. 대신 표준 논리 앱 리소스에 스키마를 직접 업로드할 수 있습니다. 어느 쪽이든 동일한 논리 앱 리소스의 모든 자식 워크플로에서 동일한 스키마를 사용할 수 있습니다. 여러 논리 앱 리소스에서 동일한 스키마를 사용하려면 통합 계정을 사용하고 연결해야 합니다.
XML 콘텐츠를 인코딩하거나 디코딩하는 방법을 지정하는 플랫 파일 스키마입니다.
표준 워크플로에서 플랫 파일 작업을 사용하면 연결된 통합 계정 또는 이전에 논리 앱에 업로드한 스키마를 선택할 수 있지만 둘 다 선택할 수는 없습니다.
자세한 내용은 통합 계정에 스키마 추가를 참조하세요.
솔루션을 테스트하려면 HTTP 요청을 보낼 수 있는 도구를 설치하거나 사용하세요. 예를 들어:
- Visual Studio Code 를 Visual Studio Marketplace의 확장과 함께 사용
- PowerShell Invoke-RestMethod
- Microsoft Edge - 네트워크 콘솔 도구
- 브루노
- curl
주의
자격 증명, 비밀, 액세스 토큰, API 키 및 기타 유사한 정보와 같은 중요한 데이터가 있는 시나리오의 경우 필요한 보안 기능으로 데이터를 보호하는 도구를 사용해야 합니다. 이 도구는 오프라인 또는 로컬로 작동하며 온라인 계정에 로그인하거나 데이터를 클라우드에 동기화할 필요가 없습니다. 이러한 특성을 가진 도구를 사용하면 중요한 데이터를 대중에게 노출할 위험을 줄일 수 있습니다.
제한 사항
디코딩하려는 XML 콘텐츠는 UTF-8 형식으로 인코딩되어야 합니다.
플랫 파일 스키마에서 포함된 XML 그룹에
max count값으로 설정된 속성의 수가 너무 많지 않은지 확인합니다.max count속성이 1보다 큰 다른 XML 그룹 내부에max count속성 값이 1보다 큰 XML 그룹을 중첩하지 마세요.Azure Logic Apps가 플랫 파일 스키마를 구문 분석하고 스키마에서 다음 조각을 선택할 수 있게 되면 Azure Logic Apps는 해당 조각에 대한 기호 와 예측을 생성합니다. 스키마가 너무 많은 구문(예: 100,000개 이상)을 허용하는 경우 스키마 확장이 매우 커져서 리소스가 너무 많고 시간이 너무 많이 소모됩니다.
스키마 업로드
스키마를 만든 후 워크플로에 따라 스키마를 업로드합니다.
플랫 파일 인코딩 작업 추가
Azure Portal에서 논리 앱 리소스를 엽니다.
디자이너에서 워크플로를 엽니다.
워크플로에 트리거 또는 워크플로에 필요한 다른 작업이 없는 경우 먼저 해당 작업을 추가합니다.
이 예제에서는 HTTP 요청을 받을 때라는 요청 트리거를 사용합니다. 트리거를 추가하려면 워크플로를 시작하는 트리거 추가를 참조하세요.
디자이너에서 다음 일반 단계에 따라 플랫 파일 인코딩이라는 기본 제공 작업을 추가합니다.
매개 변수 탭이 선택된 상태에서 작업 정보 창이 열립니다.
작업의 Content 매개 변수에서 다음 단계에 따라 트리거 또는 이전 작업의 출력인 인코딩할 XML 콘텐츠를 제공합니다.
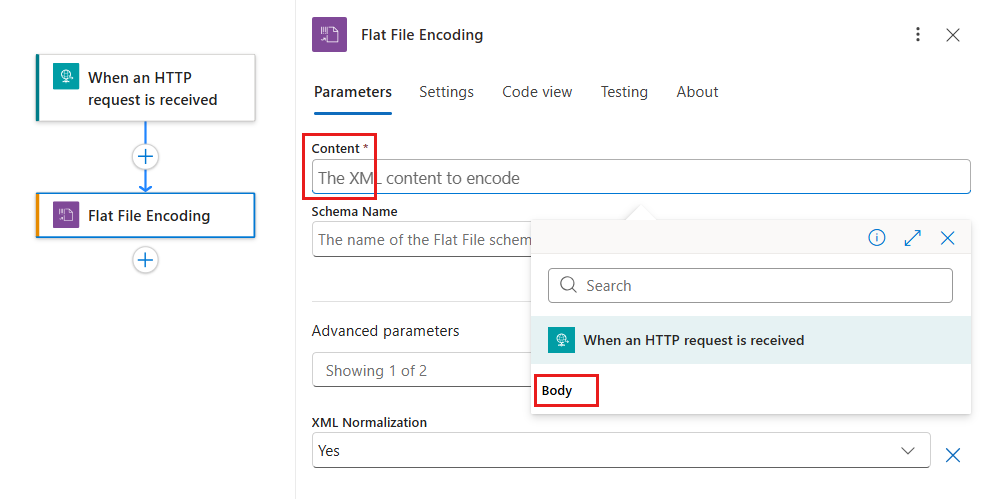
콘텐츠 상자 내부를 선택한 다음 번개 아이콘을 선택하여 동적 콘텐츠 목록을 엽니다.
동적 콘텐츠 목록에서 인코딩할 XML 콘텐츠를 선택합니다.
다음 예제에서는 열린 동적 콘텐츠 목록, HTTP 요청을 수신할 때 의 출력 및 트리거 출력에서 선택한 본문 콘텐츠를 보여 줍니다.
참고
동적 콘텐츠 목록에 본문 이 표시되지 않으면 HTTP 요청이 수신될 때 섹션 레이블 옆에 있는 자세히 보기를 선택합니다. 인코딩할 콘텐츠를 콘텐츠 상자에 직접 입력할 수도 있습니다.
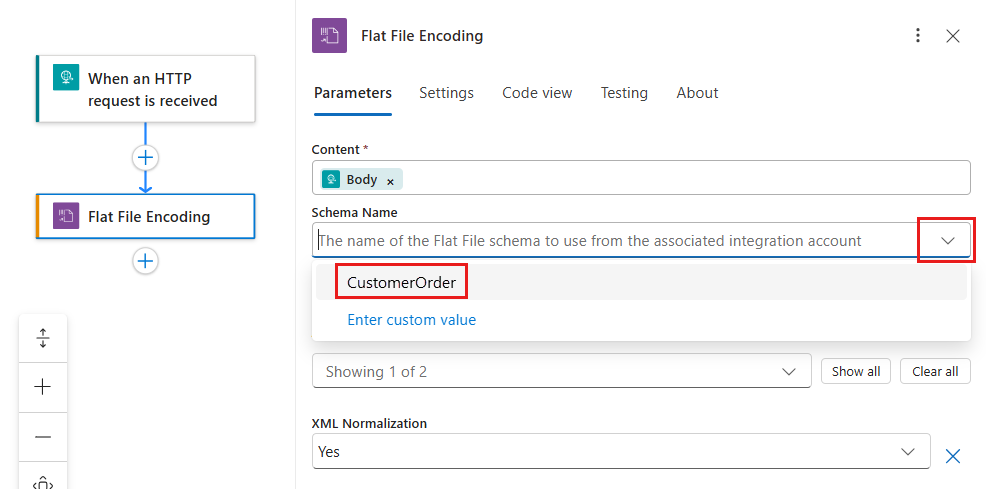
스키마 이름 목록에서 스키마를 선택합니다.
참고
스키마 목록이 비어 있으면 원인은 다음과 같습니다.
- 논리 앱 리소스는 통합 계정에 연결되지 않습니다.
- 연결된 통합 계정에는 스키마 파일이 없습니다.
- 논리 앱 리소스에는 스키마 파일이 없습니다. 이러한 이유는 표준 논리 앱에만 적용됩니다.
작업에 다른 선택적 매개 변수를 추가하려면 고급 매개 변수 목록에서 해당 매개 변수 를 선택합니다.
매개 변수 값 설명 빈 노드 생성 모드 ForcedDisabled 또는 HonorSchemaNodeProperty 또는 ForcedEnabled 플랫 파일 인코딩으로 빈 노드 생성에 사용할 모드
BizTalk의 경우 플랫 파일 스키마에는 빈 노드 생성을 제어하는 속성이 있습니다. 플랫 파일 스키마에 대한 빈 노드 생성 속성 동작을 따를 수 있습니다. 또는 이 설정을 사용하여 Azure Logic Apps가 빈 노드를 생성하거나 생략하도록 할 수 있습니다. 자세한 내용은 빈 요소에 대한 태그를 참조하세요.XML 정규화 예 또는 아니요 플랫 파일 인코딩에서 XML 정규화를 사용하거나 사용하지 않도록 지정하는 설정 자세한 내용은 XmlTextReader.Normalization을 참조하세요. 워크플로를 저장합니다. 디자이너 도구 모음에서 저장을 선택합니다.


플랫 파일 디코딩 작업 추가
Azure Portal에서 논리 앱 리소스를 엽니다.
디자이너에서 워크플로를 엽니다.
워크플로에 트리거 또는 워크플로에 필요한 다른 작업이 없는 경우 먼저 해당 작업을 추가합니다.
이 예제에서는 HTTP 요청을 받을 때라는 요청 트리거를 사용합니다. 트리거를 추가하려면 워크플로를 시작하는 트리거 추가를 참조하세요.
디자이너에서 다음 일반 단계에 따라 플랫 파일 디코딩이라는 기본 제공 작업을 추가합니다.
작업의 Content 매개 변수에서 다음 단계를 수행하여 트리거 또는 이전 작업의 출력으로 디코딩할 XML 콘텐츠를 제공합니다.
콘텐츠 상자 내부를 선택한 다음 번개 아이콘을 선택하여 동적 콘텐츠 목록을 엽니다.
동적 콘텐츠 목록에서 디코딩할 XML 콘텐츠를 선택합니다.
다음 예제에서는 열린 동적 콘텐츠 목록, HTTP 요청을 수신할 때 의 출력 및 트리거 출력에서 선택한 본문 콘텐츠를 보여 줍니다.

참고
동적 콘텐츠 목록에 본문이 표시되지 않으면 HTTP 요청이 수신되는 경우 섹션 레이블 옆의 자세히 보기를 선택합니다. 콘텐츠 상자에 직접 디코딩할 콘텐츠를 입력할 수도 있습니다.
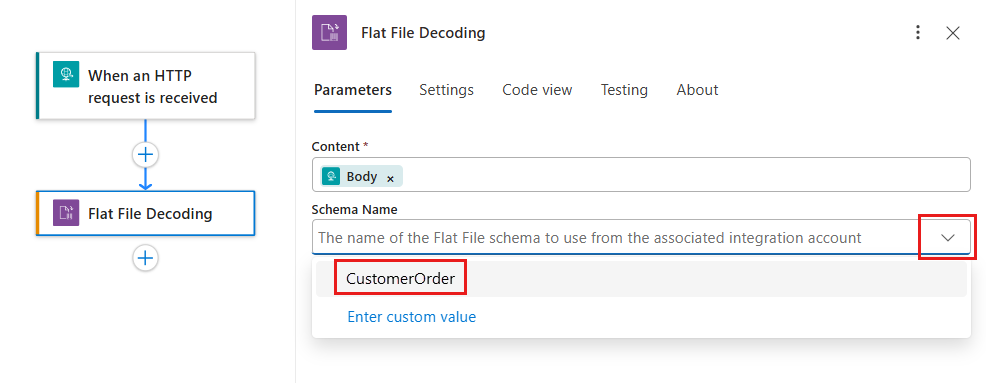
스키마 이름 목록에서 스키마를 선택합니다.
참고
스키마 목록이 비어 있으면 원인은 다음과 같습니다.
- 논리 앱 리소스는 통합 계정에 연결되지 않습니다.
- 연결된 통합 계정에는 스키마 파일이 없습니다.
- 논리 앱 리소스에는 스키마 파일이 없습니다. 이러한 이유는 표준 논리 앱에만 적용됩니다.
워크플로를 저장합니다. 디자이너 도구 모음에서 저장을 선택합니다.


이제 플랫 파일 디코딩 작업 설정을 완료하였습니다. 실제 앱에서는 디코딩된 데이터를 SalesForce와 같은 LOB(기간 업무) 앱에 저장할 수도 있습니다. 또는 디코딩된 데이터를 거래 업체에 보낼 수도 있습니다. 디코딩 작업의 출력을 Salesforce 또는 거래 업체에 보내려면 Azure Logic Apps에서 사용할 수 있는 다른 커넥터를 사용합니다:
플랫 파일 스키마 생성 작업 추가
플랫 파일 스키마 생성 작업은 입력으로 제공하는 샘플 플랫 파일 콘텐츠에서 런타임에 XSD 플랫 파일 스키마를 생성합니다. 생성된 스키마는 BizTalk 플랫 파일 주석(예: b:schemaInfo, b:recordInfo및 )과 b:fieldInfo호환됩니다.
Azure Portal에서 논리 앱 리소스를 엽니다.
디자이너에서 워크플로를 엽니다.
워크플로에 트리거 또는 워크플로에 필요한 다른 작업이 없는 경우 먼저 해당 작업을 추가합니다.
이 예제에서는 HTTP 요청을 받을 때라는 요청 트리거를 사용합니다. 트리거를 추가하려면 워크플로를 시작하는 트리거 추가를 참조하세요.
디자이너에서 다음 일반 단계에 따라 플랫 파일 스키마 생성이라는 기본 제공 작업을 추가합니다.
작업의 Content 매개 변수에서 플랫 파일 샘플 콘텐츠를 제공합니다.
트리거 출력 또는 이전 작업의 콘텐츠를 사용할 수 있습니다.
콘텐츠 상자 내부를 선택한 다음 번개 아이콘을 선택하여 동적 콘텐츠 목록을 엽니다.
동적 콘텐츠 목록에서 샘플 플랫 파일 콘텐츠를 선택합니다.
레코드 구조 매개 변수를 구분됨 또는 위치 관련(으)로 설정합니다.
디자이너는 동적 매개 변수(
getFlatFileSchemaGenerationParameters)를 사용하여 선택한recordStructure값에 따라 올바른 매개 변수 집합을 표시합니다.다음 예제에서는 구분된 레코드 구조에 대한 구성 매개 변수를 보여줍니다.

다음 예제에서는 위치 레코드 구조에 대한 구성 매개 변수 를 보여줍니다.

선택한 레코드 구조의 경우 필수 및 선택적 매개 변수를 설정합니다.
공통 매개변수(구분 기호로 구분된 및 위치 기반)
매개 변수 유형 필수 설명 contentAny Yes 플랫 파일 샘플 데이터 콘텐츠(문자열 또는 이진). recordStructureString Yes Delimited또는Positional중 하나입니다.hasHeaderBoolean Yes 이면 true첫 번째 레코드 줄을 헤더로 처리하고 해당 값을 생성된 필드 이름으로 사용합니다.recordDelimiterString No 레코드(줄) 구분 기호입니다. 구문 분석에서는 이 값을 문자 그대로 사용합니다(16진수 디코딩 없음). \r\n또는\n와 같은 실제 문자를 사용합니다. 기본 줄 분할을 사용하려면 이 값을 생략합니다. 생성된 XSD는 스키마 주석에서 16진수 값(0x0D0A)을 내보낼 수 있습니다.recordDelimiterOrderString No 구분 기호 배치: Infix(기본값),Prefix또는Postfix.rootElementNameString No XSD의 루트 요소 이름입니다. 기본값: Root.targetNamespaceString No 스키마의 대상 네임스페이스입니다. 기본값: http://schemas.microsoft.com/FlatFile/{RootElementName}recordNameString No 반복되는 자식 레코드 요소의 이름. 기본값: {RootElementName}_Record구분된 특정 매개 변수
매개 변수 유형 필수 설명 fieldDelimiterString Yes 필드 구분 기호 문자(예: 쉼표, 세미콜론, 탭, 실제 문자 제공(예: ,,;또는\t. 구문 분석에서는 리터럴 문자열 비교(16진수 디코딩 없음)를 사용합니다.fieldDelimiterOrderString Yes 구분 기호 배치: Infix(기본값),Prefix또는Postfix.escapeCharacterString No 필드 값에 포함된 구분 기호의 이스케이프 문자입니다. 실제 문자(예: \또는".)를 제공합니다. 구문 분석에서는 리터럴 일치(16진수 디코딩 없음)를 사용합니다.위치별 매개 변수
매개 변수 유형 필수 설명 countPositionsByByteBoolean Yes 필드 길이를 바이트() 또는 문자( truefalse)로 측정합니다. 멀티바이트 인코딩과 관련이 있습니다.fieldPositions배열 Yes 각각 length및justification을 포함하는 필드 위치 개체의 배열fieldPositions[].lengthInteger Yes 필드의 너비가 고정되었습니다. fieldPositions[].justificationString Yes 패딩 정렬을 제어합니다. 값을 Left수동으로 입력하거나Right(대/소문자를 구분하지 않습니다).
참고: 현재 디자이너는 값을 선택할 수 있는 목록을 제공하지 않습니다.워크플로를 실행하기 전에 구분 기호와 이스케이프 문자 동작을 검토하세요.
레코드 구분자 동작
Aspect Behavior 구문 분석(줄 나누기) options.RecordDelimiter(원시 사용자 값)은 .에String.Split()직접 전달됩니다. 16진수 디코딩 없음XSD 출력 GetRecordDelimiterForSchema()는 다음과 같이 변환됩니다.
-0x접두사가 붙은 경우 그대로 통과시킵니다.
- 비어 있는 경우 기본값은 .입니다0x0D0A.
- 그렇지 않으면 리터럴 문자를 16진수 바이트로 변환합니다.16진수 입력 구문 분석용이 아님. 0x0D0A를 제공하면 구문 분석은 리터럴 텍스트0x0D0A를 기준으로 분리하려고 시도합니다.제공할 내용 리터럴 문자 \r\n,\n를 사용하거나 아예 생략할 수 있으며, 이 경우 기본적으로\r\n/\n/\r에서 분할하도록 설정됩니다.필드 구분 기호 동작
Aspect Behavior 구문 분석 (필드 분할) options.FieldDelimiter는 리터럴 문자열 비교로서 직접SplitDelimitedRecord()로 전달됩니다. 16진수 디코딩 없음XSD 출력 값이 0x로 시작하면child_delimiter_type="hex"를 내보내고, 그렇지 않으면"char"를 내보냅니다.16진수 입력 구문 분석용으로는 아니요. 0x09탭이 아닌 리터럴 텍스트0x09와 일치합니다.제공할 내용 실제 문자 사용: ,,;,\t등|이스케이프 문자 처리 방식
Aspect Behavior 구문 분석(이스케이핑) options.EscapeCharacter는 문자 그대로 비교됩니다. 일치하면 다음 문자는 있는 그대로 소비됩니다. 16진수 디코딩 없음.XSD 출력 값이 0x로 시작하면escape_char_type="hex"을 내보내고, 그렇지 않으면"char"를 내보냅니다.16진수 입력 구문 분석용으로는 아니요. 동일한 리터럴 일치 동작. 제공할 내용 실제 문자(예: ) \"를 사용합니다.워크플로를 저장합니다. 디자이너 도구 모음에서 저장을 선택합니다.
디코딩 또는 인코딩 작업에 생성된 스키마 출력을 사용하려면 이 출력을
.xsd파일로 수동으로 저장합니다..xsd통합 계정에 파일을 업로드합니다. 또는 표준 워크플로의 경우 논리 앱 리소스 아티팩트 폴더에 파일을 업로드합니다. REST API를 사용하여 스키마 아티팩트를 업로드할 수도 있습니다.생성된 스키마는 작업 출력 본문에 문자열로 반환됩니다.
@body('Flat_File_Schema_Generation')필요에 따라 다음 정의 예제를 사용합니다.
구분된 예제
{ "Flat_File_Schema_Generation": { "type": "FlatFileSchemaGeneration", "runAfter": {}, "inputs": { "content": "@triggerBody()", "recordStructure": "Delimited", "fieldDelimiter": ";", "fieldDelimiterOrder": "Infix", "recordDelimiter": "\\r\\n", "hasHeader": true, "rootElementName": "MerchantOrders", "targetNamespace": "http://schemas.contoso.com/FlatFile/MerchantOrders", "recordName": "MerchantOrder", "escapeCharacter": "\\" } } }위치 예제
{ "Flat_File_Schema_Generation": { "type": "FlatFileSchemaGeneration", "runAfter": {}, "inputs": { "content": "@triggerBody()", "recordStructure": "Positional", "fieldPositions": [ { "length": 6, "justification": "Left" }, { "length": 5, "justification": "Left" }, { "length": 3, "justification": "Left" } ], "countPositionsByByte": false, "hasHeader": false, "rootElementName": "Ledger", "targetNamespace": "http://schemas.contoso.com/FlatFile/Ledger" } } }생성된 스키마를 다음 작업에 전달합니다.
{ "Next_Action": { "inputs": { "schema": "@body('Flat_File_Schema_Generation')" }, "runAfter": { "Flat_File_Schema_Generation": [ "Succeeded" ] } } }출력, 유추 규칙 및 알려진 문제를 검토합니다.
출력:
재산 유형 설명 bodyString BizTalk 호환 XSD 스키마를 XML 문자열로 생성했습니다. 상위 수준으로 생성된 XSD 내용:
-
b:schemaInfostandard="Flat File",root_reference및codepage="65001"를 사용한 주석 (UTF-8) -
b:recordInfostructure,child_delimiter,child_delimiter_type,child_order및 선택 사항인escape_char와escape_char_type가 있는 레코드당 주석 -
justification이 있는 필드당b:fieldInfo주석 및 위치 스키마의 경우pos_offset및pos_length - 샘플 데이터에서 데이터 형식 유추:
xs:string,xs:integer,xs:decimal,xs:booleanxs:datexs:dateTime
비어있지 않은 첫 번째 데이터 레코드에서 데이터 형식 유추:
샘플 값 유추된 XSD 형식 true또는falsexs:boolean12345xs:integer19.99xs:decimal2025-01-15xs:date2025-01-15T10:30:00xs:dateTime기타 값 xs:string자식 순서(구분 기호 배치):
Order 의미 예제( ;)Infix필드 간 구분 기호 A;B;CPrefix각 필드 앞의 구분 기호 ;A;B;CPostfix각 필드 뒤의 구분 기호 A;B;C;헤더 처리:
- 이
hasHeader경우true첫 번째 줄은 데이터가 아닌 필드 이름으로 처리됩니다. - 헤더 값은 유효한 XML 요소 이름이 되도록 정리됩니다. 특수 문자는
_로 표시되고, 앞에 오는 숫자에는_접두사가 붙습니다. - 머리글 줄만 있고 데이터 레코드가 없으면 필드가 기본값으로 지정됩니다
xs:string. - 머리글 필드가 비어 있으면 생성된 필드 이름이 .로
Field{N}돌아갑니다. -
hasHeader가false인 경우 필드 이름이Field1,Field2,Field3등으로 자동 지정됩니다.
-


제한 사항 및 알려진 문제
| Limitation | 설명 |
|---|---|
| 형식 유추는 단일 레코드를 사용합니다. | 비어있지 않은 첫 번째 데이터 레코드는 열 형식을 결정합니다. |
| 단일 레코드 유형만 | 이 작업은 반복 레코드 구조를 하나 생성하며 다른 유형의 레코드 레이아웃을 지원하지 않습니다. |
| 중첩 또는 계층적 레코드 없음 | 생성된 스키마는 평평합니다. 즉, 하나의 반복 자식 레코드와 필드가 있는 루트 요소가 있습니다. |
| 위치 경계는 자동으로 검색되지 않습니다. | 에 정확한 필드 길이를 fieldPositions제공해야 합니다. |
| UTF-8 코드 페이지만 | 생성된 스키마 집합 codepage="65001" 이며 인코딩 선택을 노출하지 않습니다. |
| 이스케이프 문자의 동작은 리터럴입니다. | 이스케이프 처리는 리터럴 값과 일치하며 다음 단일 문자만 건너뜁니다. |
recordName 기본값 |
지정되지 않은 경우 기본값은 .입니다 {RootElementName}_Record. |
| 디자이너 정당화 사유 입력 |
fieldPositions[].justification만 지원합니다.LeftRight |
| Issue | 해결 방법 |
|---|---|
| 잘못된 필드 수 |
fieldDelimiterOrder 데이터 형식(Infix, Prefix,Postfix)과 일치하는지 확인합니다. |
| 16진수 값은 출력 전용입니다. | 생성된 XSD는 구분 기호를 16진수 값(예: 0x0D0A)으로 표시하고 주석에서 0x 접두사가 붙은 값을 그대로 전달할 수 있지만, 구문 분석 시에는 16진수 입력을 디코딩하지 않습니다. 구문 분석의 경우 항상 실제 구분 기호 문자(\r\n,, \n, \t,,;)를 제공합니다. |
| 머리글 필드 이름이 예기치 않은 것처럼 보입니다. | 헤더 값은 유효한 XML 이름이 되도록 정리됩니다. 예를 들어 1st Qty는 _1st_Qty로 변합니다. |
| 레코드 구분자 동작 |
recordDelimiter가 생략되면 구문 분석 시 실제 줄바꿈 문자(\r\n, \n, \r)를 기준으로 분할됩니다. 생성된 XSD 주석에서 레코드 구분 기호의 기본값은 .입니다 0x0D0A. |
문제 해결
| 오류 | 원인 | 해결 방법 |
|---|---|---|
The flat file sample data content is required. |
content 가 null이거나 비어 있습니다. |
트리거 또는 이전 작업이 비어있지 않은 플랫 파일 콘텐츠를 제공하는지 확인합니다. |
The schema generation options are required. |
내부 오류: options 개체가 null입니다. | 워크플로 정의에 유효한 입력이 포함되어 있는지 확인합니다. |
Failed to generate flat file schema: '{details}'. |
예기치 않은 런타임 오류(예: 인코딩 또는 잘못된 형식의 데이터)입니다. | 근본 원인에 대한 세부 정보 또는 내부 오류 메시지를 검사합니다. |
The field delimiter is required for delimited record structure. |
recordStructure은 Delimited이지만 fieldDelimiter이 누락되었거나 비어 있습니다. |
예를 들어 쉼표, 세미콜론 또는 탭과 같은 fieldDelimiter를 입력하세요. 0x09와 같은 16진수 텍스트는 입력하지 말고, 대신 \t와 같은 실제 문자를 입력하세요. |
The field positions array is required for positional record structure. |
recordStructure는 Positional이지만 fieldPositions가 누락되었거나 비어 있습니다. |
각 필드에 대해 length 및 justification를 fieldPositions와 함께 제공하세요. |
The flat file sample data contains no data records. |
비어 있지 않은 데이터 줄이 없거나 헤더 hasHeader=true만 존재합니다. |
샘플 콘텐츠에 비어있지 않은 데이터 레코드를 하나 이상 제공합니다. |
Positional field '{N}' exceeds the record length. Record length: '{len}', position: '{pos}', field length: '{fieldLen}'. |
총 필드 길이가 레코드 길이를 초과합니다. |
fieldPositions 길이를 조정하거나 countPositionsByByte를 변경해야 하는지 확인하세요. |
워크플로 테스트
워크플로를 트리거하려면 다음 단계를 따르세요:
요청 트리거에서 HTTP POST URL 매개 변수를 찾고 URL을 복사합니다.
HTTP 요청 도구를 열고, 해당 지침에 따라 복사한 URL로 요청 트리거가 예상하는 메서드를 포함하는 HTTP 요청을 보내세요.
이 예제는 URL과 함께
POST메서드를 사용합니다.인코딩 또는 디코딩하려는 XML 콘텐츠를 요청 본문에 포함하세요.
워크플로 실행이 완료되면 워크플로의 실행 기록으로 이동하여 플랫 파일 작업의 입력 및 출력을 검사합니다.