Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa pagina illustra come connettersi a sql warehouse, esplorare file e dati e scrivere query nel nuovo editor SQL di Databricks.
Connessione all’ambiente di calcolo
Per eseguire query, è necessario disporre almeno delle autorizzazioni CAN USE per un'istanza di SQL Warehouse. È possibile usare l'elenco a discesa nella parte superiore dell'editor per visualizzare le opzioni disponibili. Per filtrare l'elenco, immettere testo nella casella di ricerca.
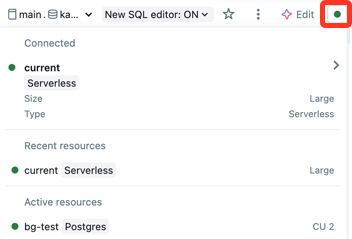
Se si dispone di un default SQL Warehouse, l'editor SQL lo usa automaticamente quando si crea una query. Se non è impostato alcun magazzino predefinito, è possibile selezionare un elenco alfabetico dei magazzini disponibili. Le query successive usano l'ultimo warehouse selezionato. Per impostare un warehouse predefinito, vedere Impostare un warehouse predefinito a livello di utente.
L'icona accanto a SQL warehouse indica lo stato:
- In esecuzione

- Arrestato
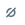
Annotazioni
Se nell'elenco non sono presenti warehouse SQL, contattare l'amministratore dell'area di lavoro.
L'istanza di SQL warehouse selezionata verrà riavviata automaticamente quando si esegue la query. Vedere Avviare un'istanza di SQL warehouse per informazioni su altri modi per avviare un'istanza di SQL warehouse.
Esplorare gli asset e ottenere assistenza
Usare il riquadro sinistro nell'editor SQL per trovare i file dell'area di lavoro, visualizzare gli oggetti dati e ottenere assistenza da Genie Code.
Esplorare i file dell'area di lavoro
Fare clic sull'icona della cartella per aprire la cartella utente dell'area di lavoro. È possibile passare a tutti i file dell'area di lavoro a cui si ha accesso da questa parte dell'interfaccia utente.
Esplorare gli oggetti dati
Se si dispone dell'autorizzazione di lettura dei metadati, il browser dello schema nell'editor SQL mostra i database e le tabelle disponibili. È anche possibile esplorare oggetti di dati dall'Esplora Cataloghi .
È possibile esplorare gli oggetti di database regolati dal catalogo Unity in Esplora cataloghi senza calcolo attivo. Per esplorare i dati nel hive_metastore e in altri cataloghi non regolati dal catalogo Unity, è necessario connettersi alle risorse di calcolo con privilegi appropriati. Vedere Governance dei dati con Azure Databricks.
Annotazioni
Se nel browser degli schemi o nel Catalog Explorer non sono presenti oggetti dati, contattare l'amministratore dell'area di lavoro.
Fare clic su ![]() vicino alla parte superiore del browser dello schema per aggiornare lo schema. È possibile immettere testo nella barra di ricerca per filtrare gli asset in base al nome. Fare clic
vicino alla parte superiore del browser dello schema per aggiornare lo schema. È possibile immettere testo nella barra di ricerca per filtrare gli asset in base al nome. Fare clic ![]() Icona filtro per filtrare gli oggetti in base al tipo.
Icona filtro per filtrare gli oggetti in base al tipo.
Fare clic sul nome di un oggetto nel browser per visualizzare altri dettagli sull'oggetto. Ad esempio, fare clic su un nome di schema per visualizzare le tabelle nello schema. Fare clic su un nome di tabella per visualizzare le colonne nella tabella.
Ottenere assistenza da Genie Code
Fare clic ![]() Icona Genie Code per aprire una finestra di chat con Genie Code. Fare clic su una domanda suggerita o immettere la propria domanda per interagire con Genie Code.
Icona Genie Code per aprire una finestra di chat con Genie Code. Fare clic su una domanda suggerita o immettere la propria domanda per interagire con Genie Code.
Crea una query
È possibile immettere testo per creare una query nell'editor SQL. È possibile inserire elementi dal browser dello schema per fare riferimento a cataloghi e tabelle.
Immettere la query nell'editor SQL.
L'editor SQL supporta il completamento automatico. Durante la digitazione, il completamento automatico suggerisce i completamenti. Ad esempio, se un completamento valido nella posizione del cursore è una colonna, il completamento automatico suggerisce un nome di colonna. Se si digita
select * from table_name as t where t., il completamento automatico riconosce chetè un alias pertable_namee suggerisce le colonne all'interno ditable_name. È anche possibile usare il completamento automatico per fare riferimento ai frammenti di query.
(Facoltativo) Al termine dell'azione di modifica, fare clic su Salva. Per impostazione predefinita, la query viene salvata nella cartella Home dell'utente. Per salvare la query in un percorso diverso, selezionare la cartella di destinazione e fare clic su Sposta.
Annotazioni
Le nuove query vengono denominate automaticamente Nuova query con il timestamp di creazione aggiunto nel titolo. Per impostazione predefinita, le nuove query create senza un contesto di cartella specifico vengono create nella cartella Bozze nella home directory. Quando le nuove query vengono salvate o rinominate, vengono rimosse dalle bozze.
Eseguire query su origini dati
È possibile identificare un'origine della query usando un nome di tabella completo nella query stessa o selezionando una combinazione di catalogo e schema dai menu a tendina insieme al nome della tabella nella query. Un nome di tabella completo nella query annulla le opzioni di catalogo e schema nell'editor SQL. Se un nome di tabella o colonna include spazi, racchiudi tali identificatori tra backtick nelle query SQL.
Annotazioni
Il numero massimo di risultati restituiti in una tabella è pari a 64.000 righe o 10 MB, a seconda di quale valore sia inferiore.
Negli esempi seguenti viene illustrato come eseguire query su vari oggetti simili a tabelle che è possibile archiviare in un catalogo.
Eseguire una query su una tabella o vista standard
Il seguente esempio esegue una query su una tabella del catalogo samples.
SELECT
o_orderdate,
o_orderkey,
o_custkey,
o_totalprice,
o_shippriority
FROM
samples.tpch.orders
Eseguire query su una visualizzazione metrica
Nell'esempio seguente viene eseguita una query su una vista metrica che usa una tabella del catalogo degli esempi come origine. Valuta le tre misure elencate e le aggregazioni su Order Month e Order Status. Restituisce i risultati ordinati in base a Order Month. Per creare una visualizzazione metrica simile nell'area di lavoro, vedere Esercitazione: Creare una visualizzazione metrica completa con join.
Tutte le valutazioni delle misure devono essere incluse nella funzione MEASURE. Vedere la funzione di aggregazione measuree.
SELECT
`Order Month`,
`Order Status`,
MEASURE(`Order Count`),
MEASURE(`Total Revenue`),
MEASURE(`Total Revenue per Customer`)
FROM
orders_metric_view
GROUP BY ALL
ORDER BY 1 ASC;
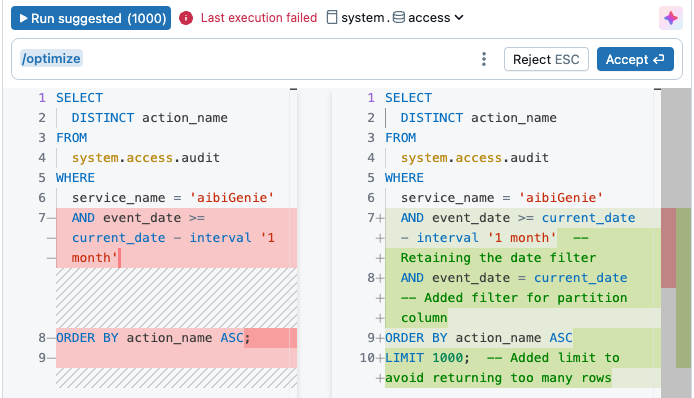
Ottimizzare una query con Genie Code
Fare clic ![]() Icona assistente sul lato destro dell'editor per ottenere informazioni e suggerimenti inline durante la scrittura di query. Il comando slash
Icona assistente sul lato destro dell'editor per ottenere informazioni e suggerimenti inline durante la scrittura di query. Il comando slash /optimize invita l'Assistente a valutare e ottimizzare le query. Per altre informazioni, vedere Ottimizzare codice Python, PySpark e SQL.
Modificare più schede di query
Per impostazione predefinita, l'editor SQL usa le schede in modo da poter aprire e modificare più query contemporaneamente. Per aprire una nuova scheda, cliccare su +, quindi selezionare Crea nuova query o Apri query esistente. Fare clic su Apri query esistente per visualizzare un elenco di query. La scheda For you offre un elenco curato di suggerimenti basati sull'utilizzo. Utilizzare la scheda Tutti per trovare qualsiasi query a cui si ha accesso.
Salvare una interrogazione
Il contenuto delle query nel nuovo editor SQL viene salvato automaticamente in modo continuo. Il pulsante Salva controlla se il contenuto della query bozza deve essere applicato agli asset correlati, ad esempio flussi di lavoro o avvisi legacy. Se la query viene condivisa con le credenziali Esegui come proprietario, solo il proprietario della query può usare il pulsante Salva per propagare le modifiche. Se la credenziale è impostata su Esegui come visualizzatore, qualsiasi utente con almeno CAN MANAGE l'autorizzazione può salvare la query.
Controllo del codice sorgente di una query
I file di query SQL di Databricks (estensione: .dbquery.ipynb) sono supportati nelle cartelle Git di Databricks . È possibile usare una cartella Git per controllare i file di query e condividerli in altre aree di lavoro con cartelle Git che accedono allo stesso repository Git. Se si sceglie di non utilizzare il nuovo editor SQL dopo aver effettuato il commit o la clonazione di una query in una cartella Git di Databricks, eliminare e riclonare quella cartella Git per evitare comportamenti imprevisti.