Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Azure Data Lake Storage è una soluzione data lake altamente scalabile e conveniente per l'analisi dei Big Data. Combina la potenza di un file system ad alte prestazioni con scalabilità elevatissima e costi contenuti per ridurre i tempi di analisi. Data Lake Storage Gen2 estende le funzionalità di Archiviazione BLOB di Azure ed è ottimizzato per i carichi di lavoro di analisi.
Esplora dati di Azure si integra con Archiviazione BLOB di Azure e Azure Data Lake Storage (Gen1 e Gen2), offrendo accesso rapido, memorizzato nella cache e indicizzato ai dati archiviati nell'archiviazione esterna. È possibile analizzare ed eseguire query sui dati senza l'inserimento precedente in Esplora dati di Azure. È anche possibile eseguire query simultaneamente su dati esterni inseriti e non inseriti. Per altre informazioni, vedere come creare una tabella esterna utilizzando la procedura guidata dell'interfaccia utente Web di Esplora dati di Azure. Per una breve panoramica, vedere tabelle esterne.
Suggerimento
Le migliori prestazioni delle query richiedono l'inserimento dei dati in Esplora dati di Azure. La possibilità di eseguire query su dati esterni senza prima inserirli deve essere sfruttata solo per i dati cronologici o per i dati su cui vengono eseguite query raramente. Per ottenere risultati ottimali, ottimizzare le prestazioni delle query sui dati esterni.
Creare una tabella esterna
Si supponga di avere molti file CSV contenenti informazioni cronologiche sui prodotti depositati in un magazzino e di voler eseguire un'analisi rapida per trovare i cinque prodotti più popolari dell'anno precedente. I file CSV sono simili all'esempio seguente:
| Timestamp: | ID prodotto | descrizione del prodotto |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 8,89 cm dischetto DS/HD alta densità |
| 2019-01-01 11:30:55 | YDX1 | Sintetizzatore Dx1 Yamaha |
| ... | ... | ... |
I file vengono archiviati nel Blob di Azure mycompanystorage in un contenitore denominato archivedproducts, suddiviso per data:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Per eseguire direttamente una query KQL su questi file CSV, usare il comando .create external table per definire una tabella esterna in Esplora dati di Azure. Per ulteriori informazioni sulle opzioni del comando 'crea tabella esterna', vedere comandi per tabelle esterne.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
La tabella esterna è ora visibile nel riquadro sinistro dell'interfaccia utente Web Esplora dati di Azure:

Autorizzazioni per le tabelle esterne
Esaminare le autorizzazioni della tabella seguenti:
- L'utente del database può creare una tabella esterna. L'autore della tabella ne diventa automaticamente l'amministratore.
- L'amministratore del cluster, del database o della tabella può modificare una tabella esistente.
- Qualsiasi utente o lettore del database può eseguire query su una tabella esterna.
Esecuzione di query su una tabella esterna
Dopo aver definito una tabella esterna, è possibile usare la funzione external_table() per farvi riferimento. Il resto della query è KQL (Kusto Query Language) standard.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Esecuzione di query simultaneamente su dati esterni e inseriti
È possibile eseguire la stessa query simultaneamente su tabelle esterne e tabelle di dati inseriti. È possibile join o union la tabella esterna con altri dati di Esplora dati di Azure, SQL Server o altre origini. Usare un'let( ) statement per assegnare un nome abbreviato a un riferimento a una tabella esterna.
Nell'esempio seguente , Products è una tabella dati inserita e ArchivedProducts è una tabella esterna definita:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Esecuzione di query su formati di dati gerarchici
Esplora dati di Azure consente di eseguire query su formati gerarchici, ad esempio JSON, Parquet, Avro e ORC. Per eseguire il mapping dello schema dei dati gerarchici a uno schema di tabella esterna (se diverso), usare i comandi di mapping delle tabelle esterne. Ad esempio, per eseguire query sui file di log JSON con il formato seguente:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "aaaabbbb-0000-cccc-1111-dddd2222eeee",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "bbbbcccc-1111-dddd-2222-eeee3333ffff",
"method": "GetFileList"
}
}
...
La definizione di tabella esterna ha un aspetto simile al seguente:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Definire un mapping JSON che mappa i campi dati ai campi di definizione della tabella esterna.
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
Quando si esegue una query sulla tabella esterna, il mapping viene attivato e i dati pertinenti vengono mappati alle colonne della tabella esterna.
external_table('ApiCalls') | take 10
Per altre informazioni sulla sintassi di mapping, vedere Mapping dei dati.
Eseguire query sulla tabella esterna TaxiRides nel cluster di aiuto
Usare il cluster di test denominato help per provare diverse funzionalità di Esplora dati di Azure. Il cluster help contiene una definizione di tabella esterna per un set di dati dei taxi di New York City contenente miliardi di corse di taxi.
Creare la tabella esterna TaxiRides
Questa sezione illustra la query usata per creare la tabella esterna TaxiRides nel cluster help. Siccome hai già creato questa tabella, puoi ignorare questa sezione e passare direttamente a interrogare i dati della tabella esterna TaxiRides.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
È possibile trovare la tabella TaxiRides creata esaminando il riquadro sinistro dell'interfaccia utente Web Esplora dati di Azure.
Eseguire query sui dati della tabella esterna TaxiRides
Accedere a https://dataexplorer.azure.com/clusters/help/databases/Samples.
Eseguire query sulla tabella esterna TaxiRides senza partizionamento
Eseguire questa query sulla tabella esterna TaxiRides per visualizzare le corse per ogni giorno della settimana nell'intero set di dati.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Questa query mostra il giorno più trafficato della settimana. Poiché i dati non sono partizionati, la restituzione dei risultati della query potrebbe richiedere diversi minuti.

Eseguire query sulla tabella esterna TaxiRides con partizionamento
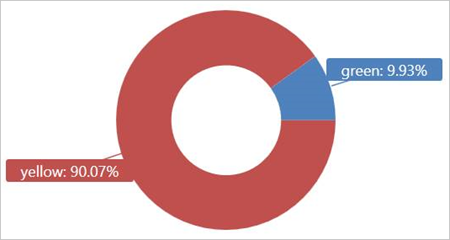
Eseguire questa query sulla tabella esterna TaxiRides per visualizzare i tipi di taxi (giallo o verde) usati nel gennaio 2017.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Questa query usa il partizionamento, che ne ottimizza le prestazioni e il tempo di esecuzione. La query applica un filtro a una colonna partizionata (pickup_datetime) e restituisce i risultati in pochi secondi.
È possibile scrivere altre query da eseguire sulla tabella esterna TaxiRides per saperne di più sui dati.
Ottimizzare le prestazioni delle query
Ottimizzare le prestazioni della query nel data lake usando le procedure consigliate seguenti per l'esecuzione di query sui dati esterni.
Formato dati
- Usare un formato a colonne per le query analitiche, per i motivi seguenti:
- Possono essere lette solo le colonne pertinenti a una query.
- Le tecniche di codifica delle colonne possono ridurre in modo significativo le dimensioni dei dati.
- Esplora dati di Azure supporta i formati a colonne Parquet e ORC. Il formato Parquet è quello consigliato per via dell'implementazione ottimizzata.
regione di Azure
Verificare che i dati esterni si trovano nella stessa area Azure del cluster Esplora dati di Azure. Questa configurazione riduce i costi e i tempi di recupero dei dati.
Dimensioni file
Le dimensioni ottimali dei file sono pari a centinaia di MB (fino a 1 GB) per file. Evitare molti file di piccole dimensioni che richiedono un sovraccarico non necessario, ad esempio un processo di enumerazione dei file più lento e un uso limitato del formato a colonne. Il numero di file deve essere maggiore del numero di core CPU nel cluster Esplora dati di Azure.
Compressione
Usare la compressione per ridurre la quantità di dati da recuperare dall'archivio remoto. Per il formato Parquet, usare il meccanismo interno di compressione di Parquet che comprime i gruppi di colonne in modo separato, permettendone la lettura individuale. Per convalidare l'uso del meccanismo di compressione, verificare che i file siano denominati nel modo seguente: <nomefile>.gz.parquet o <nomefile>.snappy.parquet e non <nomefile>.parquet.gz.
Partizionamento
Organizzare i dati usando partizioni di "cartella" che consentono alla query di ignorare i percorsi non rilevanti. Nella pianificazione del partizionamento, considerare le dimensioni dei file e i filtri comuni nelle query, come il timestamp o l'ID tenant.
Dimensioni della VM
Selezionare SKU di VM con più core e velocità effettiva di rete superiore (la memoria è meno importante). Per altre informazioni, vedere Selezionare lo SKU di macchina virtuale corretto per il cluster Esplora dati di Azure.