Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
L’article explique comment utiliser PolyBase sur une appliance PDW (Analytics Platform System) ou APS pour interroger des données externes dans Hadoop.
Prerequisites
PolyBase prend en charge deux fournisseurs Hadoop, HDP (Hortonworks Data Platform) et CDH (Cloudera Distributed Hadoop). Hadoop suit le modèle « Majeure.Mineure.Version » pour ses nouvelles versions, et toutes les versions au sein d'une édition majeure et mineure prise en charge sont prises en charge. Les fournisseurs Hadoop suivants sont pris en charge :
- Hortonworks HDP 1.3 sur Linux/Windows Server
- Hortonworks HDP 2.1 - 2.6 sur Linux
- Hortonworks HDP 3.0 - 3.1 sur Linux
- Hortonworks HDP 2.1 - 2.3 sur Windows Server
- Cloudera CDH 4.3 sur Linux
- Cloudera CDH 5.1 - 5.5, 5.9 - 5.13, 5.15 & 5.16 sur Linux
Configurer la connectivité Hadoop
Tout d’abord, configurez APS pour utiliser votre fournisseur Hadoop spécifique.
Exécutez sp_configure avec 'hadoop connectivity' et définissez une valeur appropriée pour votre fournisseur. Pour trouver la valeur pour votre fournisseur, consultez Configuration de la connectivité PolyBase.
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 and 3.0 - 3.1 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GORedémarrez la région APS à l’aide de la page État du service sur Appliance Configuration Manager.
Activer le calcul pushdown
Pour améliorer les performances des requêtes, activez le calcul pushdown sur votre cluster Hadoop :
Ouvrez une connexion de bureau à distance au nœud de contrôle PDW APS.
Recherchez le fichier
yarn-site.xmlsur le nœud Contrôle. En règle générale, le chemin est :C:\Program Files\Microsoft SQL Server Parallel Data Warehouse\100\Hadoop\conf\.Sur l’ordinateur Hadoop, recherchez le fichier analogue dans le répertoire de configuration Hadoop. Dans le fichier, recherchez et copiez la valeur de la clé
yarn.application.classpathde configuration.Sur le nœud de contrôle, dans le
yarn.site.xmlfichier, recherchez layarn.application.classpathpropriété. Collez la valeur de l’ordinateur Hadoop dans l’élément de valeur.Pour toutes les versions CDH 5.X, vous devez ajouter les
mapreduce.application.classpathparamètres de configuration à la fin de votreyarn.site.xmlfichier ou dans lemapred-site.xmlfichier. HortonWorks inclut ces configurations dans lesyarn.application.classpathconfigurations. Pour obtenir des exemples, consultez la configuration de PolyBase.
Exemples de fichiers XML pour les valeurs par défaut du cluster CDH 5.X
Yarn-site.xml avec configuration yarn.application.classpath et mapreduce.application.classpath.
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/,$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Si vous choisissez d’intégrer vos deux paramètres de configuration dans mapred-site.xml et dans yarn-site.xml, les fichiers se présentent ainsi :
Pour yarn-site.xml:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Pour mapred-site.xml:
Notez la propriété mapreduce.application.classpath . Dans CDH 5.x, vous trouverez les valeurs de configuration sous la même convention d’affectation de noms dans Ambari.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<property>
<name>mapred.min.split.size</name>
<value>1073741824</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH</value>
</property>
<!--kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>mapreduce.jobhistory.principal</name>
<value></value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value></value>
</property>
-->
</configuration>
Exemples de fichiers XML pour les valeurs par défaut du cluster HDP 3.X
Pour yarn-site.xml:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,/usr/hdp/3.1.0.0-78/hadoop/*,/usr/hdp/3.1.0.0-78/hadoop/lib/*,/usr/hdp/current/hadoop-hdfs-client/*,/usr/hdp/current/hadoop-hdfs-client/lib/*,/usr/hdp/current/hadoop-yarn-client/*,/usr/hdp/current/hadoop-yarn-client/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/lib/*,/usr/hdp/share/hadoop/common/*,/usr/hdp/share/hadoop/common/lib/*,/usr/hdp/share/hadoop/tools/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Configurer une table externe
Pour interroger les données dans votre source de données Hadoop, vous devez définir une table externe à utiliser dans les requêtes Transact-SQL. Les étapes suivantes décrivent comment configurer la table externe.
Créez une clé principale sur la base de données. Il est nécessaire de chiffrer le secret d’informations d’identification.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';Créez des identifiants au niveau de la base de données pour les clusters Hadoop sécurisés par Kerberos.
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';Créez une source de données externe avec CREATE EXTERNAL DATA SOURCE.
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );Créez un format de fichier externe avec CREATE EXTERNAL FILE FORMAT.
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE)Créez une table externe pointant vers les données stockées dans Hadoop avec CREATE EXTERNAL TABLE. Dans cet exemple, les données externes contiennent des données provenant de capteurs sur des voitures.
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );Créez des statistiques sur une table externe.
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
Requêtes PolyBase
PolyBase est approprié pour trois fonctions :
- Requêtes ad-hoc sur des tables externes.
- Importation de données.
- Exportation de données.
Les requêtes suivantes fournissent un exemple avec des données fictives provenant de capteurs sur des voitures.
requêtes ad hoc ;
La requête ad hoc suivante fait une jointure entre des données relationnelles et des données Hadoop. Il sélectionne les clients qui pilotent plus rapidement que 35 mph, joignant des données client structurées stockées dans APS avec des données de capteur de voiture stockées dans Hadoop.
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
Importer des données
La requête suivante importe des données externes dans APS. Cet exemple importe des données pour les pilotes rapides dans APS afin d’effectuer une analyse plus approfondie. Pour améliorer les performances, elle tire parti de la technologie columnstore dans APS.
CREATE TABLE Fast_Customers
WITH
(CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH (CustomerKey))
AS
SELECT DISTINCT
Insured_Customers.CustomerKey, Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
Exporter les données
La requête suivante exporte les données d’APS vers Hadoop. Il peut être utilisé pour archiver des données relationnelles dans Hadoop tout en étant en mesure de l’interroger.
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009]
WITH (
LOCATION='/archive/customer/2009',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat
)
AS
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
Afficher les objets PolyBase dans SSDT
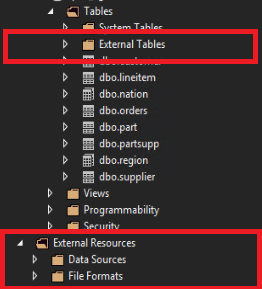
Dans SQL Server Data Tools, les tables externes sont affichées dans un dossier distinct Tables externes. Les sources de données externes et les formats de fichiers externes figurent dans des sous-dossiers du dossier Ressources externes.
Contenu connexe
- Pour connaître les paramètres de sécurité Hadoop, consultez configurer la sécurité Hadoop.
- Pour plus d’informations sur PolyBase, consultez la page Présentation de PolyBase ?