Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit les étapes de base pour le déploiement et l’interrogation d’un modèle personnalisé, qui est un modèle ML traditionnel, à l’aide de Model Serve. Le modèle doit être inscrit dans le catalogue Unity Catalog ou le Registre de modèles de l’espace de travail.
Pour en savoir plus sur le service et le déploiement de modèles d’IA générative à la place, consultez les articles suivants :
Étape 1 : Journaliser le modèle
Il existe différentes façons de consigner votre modèle pour le déploiement du modèle :
| Technique de journalisation | Descriptif |
|---|---|
| Journalisation automatique | Cette option est automatiquement activée quand vous utilisez Databricks Runtime pour le Machine Learning. C’est le moyen le plus simple, mais vous donne moins de contrôle. |
| Journalisation avec les approches intégrées de MLflow | Vous pouvez journaliser manuellement le modèle avec les versions intégrées du modèle MLflow. |
Journalisation personnalisée avec pyfunc |
Utilisez cette option si vous avez un modèle personnalisé ou si vous avez besoin d’étapes supplémentaires avant ou après l’inférence. |
L’exemple suivant montre comment journaliser votre modèle MLflow à l’aide de la saveur transformer et comment spécifier les paramètres dont vous avez besoin pour votre modèle.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Une fois votre modèle enregistré, veillez à vérifier que votre modèle est inscrit dans le catalogue Unity ou dans le registre de modèles MLflow.
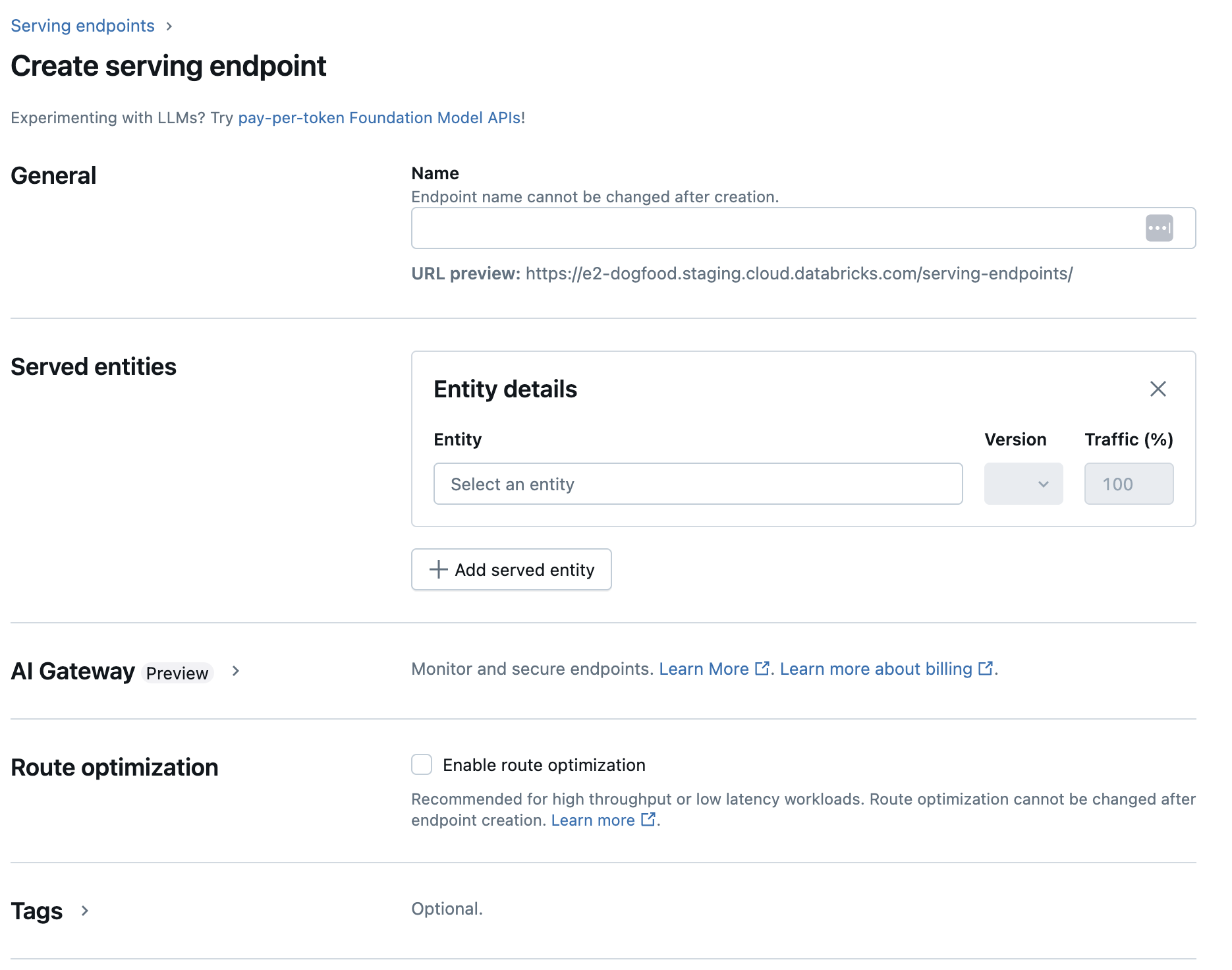
Étape 2 : Créer un point de terminaison à l’aide de l’interface utilisateur de mise en service
Une fois que votre modèle enregistré a été journalisé et que vous êtes prêt à le déployer, vous pouvez créer un point de terminaison de déploiement du modèle à l’aide de l’interface utilisateur Serving.
Cliquez sur Mise en service dans la barre latérale pour afficher l’interface utilisateur de Mise en service.
Cliquez sur Créer un point de terminaison de service.

Dans le champ Nom, indiquez un nom pour votre point de terminaison.
Dans la section Entités servies
- Cliquez sur le champ Entités pour ouvrir le formulaire Sélectionner une entité servie.
- Sélectionnez le modèle que vous souhaitez servir. Le formulaire est mis à jour dynamiquement en fonction de votre sélection.
- Sélectionnez le modèle et la version du modèle que vous souhaitez servir.
- Sélectionnez le pourcentage de trafic à acheminer vers votre modèle déployé.
- Sélectionnez la taille de calcul à utiliser.
- Sous Mise à l’échelle du calcul, sélectionnez la taille de mise à l’échelle du calcul qui correspond au nombre de requêtes que ce modèle déployé peut traiter simultanément. Ce nombre doit être à peu près égal au temps d’exécution du modèle QPS x.
- Les tailles disponibles sont Petit pour 0-4 demandes, Moyen pour 8-16 demandes et Large pour 16-64 demandes.
- Spécifiez si le point de terminaison doit être mis à l’échelle à zéro lorsqu’il n’est pas utilisé.
Cliquez sur Créer. La page Points de terminaison de mise en service s’affiche avec l’état du point de terminaison de mise en service indiqué comme Non prêt.
Si vous préférez créer un point de terminaison par programmation avec l’API de mise en service de Databricks, consultez Créer un modèle personnalisé servant des points de terminaison.
Étape 3 : Interroger le point de terminaison
Le moyen le plus simple et le plus rapide de tester et d’envoyer des requêtes de scoring à votre modèle servi consiste à utiliser l’interface utilisateur de Mise en service.
Dans la page Point de terminaison de service, sélectionnez Interroger le point de terminaison.
Insérez les données d’entrée du modèle au format JSON, puis cliquer sur Envoyer la requête. Si le modèle a été journalisé avec un exemple d’entrée, cliquez sur Afficher l’exemple pour charger l’exemple d’entrée.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Pour envoyer des demandes de notation, construisez un JSON avec l’une des clés prises en charge et un objet JSON correspondant au format d’entrée. Pour connaître les formats pris en charge et obtenir des conseils sur la façon d’envoyer des requêtes de scoring à l’aide de l’API, consultez Interroger les points de terminaison de service pour les modèles personnalisés.
Si vous prévoyez d’accéder à votre point de terminaison de service en dehors de l’interface utilisateur Azure Databricks Serving, vous avez besoin d’un fichier DATABRICKS_API_TOKEN.
Important
À titre de meilleure pratique de sécurité pour les scénarios de production, Databricks vous recommande d’utiliser des jetons OAuth machine à machine pour l’authentification en production.
Pour les tests et le développement, Databricks recommande d’utiliser un jeton d’accès personnel appartenant à des principaux de service et non pas à des utilisateurs de l’espace de travail. Pour créer des jetons d’accès pour des principaux de service, consultez la section Gérer les jetons pour un principal de service.
Exemples de notebooks
Consultez le notebook suivant pour déployer un modèle MLflow transformers avec Model Serving.
Déployer un notebook de modèle Hugging Face transformers
Consultez le notebook suivant pour déployer un modèle MLflow pyfunc avec Model Serving. Pour plus d’informations sur la personnalisation de vos modèles de déploiement, consultez Déployer du code Python avec le service de modèles.