Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Tip
Microsoft Fabric Data Warehouse es un almacenamiento relacional de escala empresarial en una base de lago de datos, con una arquitectura lista para el futuro, inteligencia artificial integrada y nuevas características. Si no está familiarizado con el almacenamiento de datos, comience con Fabric Data Warehouse. Las cargas de trabajo del grupo de SQL dedicadas pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Azure Synapse Analytics es un servicio de análisis que engloba el almacenamiento de datos empresariales y el análisis de macrodatos. Esto le ofrece la libertad de realizar consultas sobre datos según sus condiciones.
Nota:
Para más información sobre Azure Synapse Analytics, vea este vídeo en el que se explican las mejoras del movimiento de datos.
Componentes de la arquitectura de SQL de Synapse
El grupo de SQL dedicado (anteriormente SQL DW) aprovecha una arquitectura de escalabilidad horizontal para distribuir el procesamiento de cálculo de datos entre varios nodos. La unidad de escala es una abstracción de la potencia de cómputo que se conoce como unidad de almacenamiento de datos. Como el cómputo está separado del almacenamiento, se puede escalar independientemente de los datos en su sistema.
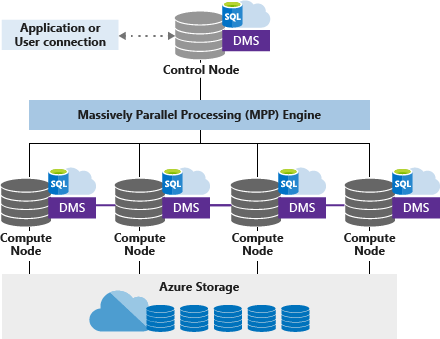
El grupo de SQL dedicado (anteriormente SQL DW) usa una arquitectura basada en nodos. Las aplicaciones se conectan y emiten comandos T-SQL a un nodo de control. El nodo de control hospeda el motor de consultas distribuidas, que optimiza las consultas para el procesamiento en paralelo y, después, pasa las operaciones a los nodos de ejecución para hacer su trabajo en paralelo.
Los nodos de ejecución almacenan todos los datos del usuario en Azure Storage y ejecutan las consultas en paralelo. El Servicio de movimiento de datos (DMS) es un servicio interno de nivel de sistema que mueve datos entre los nodos según sea necesario para ejecutar consultas en paralelo y devolver resultados precisos.
Con el almacenamiento y el proceso desacoplados, cuando usa un grupo de SQL dedicado (anteriormente SQL DW), puede realizar lo siguiente:
- Ajustar la potencia de cálculo de manera independiente a las necesidades de almacenamiento.
- Aumentar o reducir la capacidad de proceso en un grupo de SQL dedicado (anteriormente SQL DW), sin tener que mover los datos.
- Pausar la capacidad de cómputo mientras se dejan los datos intactos, de modo que solo pague por el almacenamiento.
- Reanudar la capacidad de computación durante el horario laboral.
Azure Storage
El grupo dedicado de SQL (anteriormente SQL DW) utiliza Azure Storage para mantener tus datos seguros. Puesto que los datos se almacenan y administran en Azure Storage, el consumo de almacenamiento se cobra aparte. Los datos están particionados en distribuciones para optimizar el rendimiento del sistema. Puede elegir qué modelo de particionamiento quiere usar para distribuir los datos cuando define la tabla. Se admiten estos patrones de particionamiento:
- Plato de carne picada
- Ciclo Rotativo
- Replicar
Nodo de control
El nodo de control es el cerebro de la arquitectura. Es el front-end que interactúa con todas las aplicaciones y conexiones. El motor de consultas distribuidas se ejecuta en el nodo de control para optimizar y coordinar las consultas en paralelo. Al enviar una consulta T-SQL, el nodo de control la transforma en consultas que se ejecutan en cada distribución en paralelo.
Nodos de cómputo
Los nodos de cómputo proporcionan la potencia de cálculo. Las distribuciones se asignan a nodos de cómputo para su procesamiento. A medida que paga por más recursos de proceso, las distribuciones se reasignan a los nodos de ejecución disponibles. El número de nodos de ejecución va de 1 a 60, y viene determinado por el nivel de servicio de SQL de Synapse.
Cada nodo de cálculo tiene un identificador de nodo que está visible en las vistas del sistema. Para ver el identificador del nodo de ejecución, busque la columna node_id en las vistas del sistema cuyos nombres comiencen por sys.pdw_nodes. Para obtener una lista de las vistas del sistema, consulte Vistas del sistema de Synapse SQL.
Servicio de movimiento de datos
Servicio de movimiento de datos (DMS) es la tecnología de transporte de datos que coordina el movimiento de los datos entre los nodos de proceso. Algunas consultas requieren el movimiento de datos para asegurarse de que las consultas paralelas devuelven resultados precisos. Cuando un movimiento de datos es necesario, DMS asegura que los datos adecuados llegan a la ubicación adecuada.
Distribuciones
Una distribución es la unidad básica de almacenamiento y procesamiento de consultas en paralelo que se ejecutan en datos distribuidos. Cuando Synapse SQL ejecuta una consulta, el trabajo se divide en 60 consultas más pequeñas que se ejecutan en paralelo.
Cada una de estas 60 consultas más pequeñas se ejecuta en una de las distribuciones de datos. Cada nodo de ejecución administra una o más de las 60 distribuciones. Un grupo de SQL dedicado (anteriormente SQL DW) con recursos de procesamiento máximo cuenta con una distribución por nodo de cálculo. Un grupo de SQL dedicado (anteriormente SQL DW) con recursos de cómputo mínimos tiene todas las distribuciones en un nodo de proceso.
Nota:
Para obtener recomendaciones sobre la mejor estrategia de distribución de tablas que se va a usar en función de las cargas de trabajo, consulte Asesor de distribución de Azure Synapse SQL.
Tablas distribuidas mediante una función hash
Una tabla con distribución por hash puede ofrecer el máximo rendimiento de consultas para combinaciones y agregaciones en tablas grandes.
Para particionar los datos en una tabla con distribución por hash, se usa una función hash para asignar de una manera determinista cada fila a una distribución. En la definición de tabla, una de las columnas se designa como columna de distribución. La función hash usa el valor de la columna de distribución para asignar cada fila a una distribución.
El siguiente diagrama muestra cómo se almacena una tabla completa (no distribuida) como una tabla distribuida mediante una función hash.

- Cada fila pertenece a una distribución.
- Un algoritmo hash determinista asigna cada fila a una distribución.
- El número de filas de la tabla por cada distribución varía, lo que se hace patente en los diferentes tamaños de tablas.
Es preciso tener en cuenta consideraciones de rendimiento al seleccionar una columna de distribución, tales como la diferenciación, la asimetría de datos o los tipos de consultas que se ejecutan en el sistema.
Tablas distribuidas con el método round robin
Una tabla de round-robin es la tabla más fácil de crear y ofrece un rendimiento rápido cuando se utiliza como tabla de etapa para cargas de datos.
Una tabla distribuida con el método round robin distribuye los datos uniformemente en la tabla, pero sin ninguna optimización adicional. Primero se elige una distribución de manera aleatoria y luego se asignan secuencialmente búferes de filas a las distribuciones. Es rápido cargar datos en una tabla round robin, pero el rendimiento de las consultas puede mejorar con tablas con distribución por hash. Las combinaciones en tablas round-robin requieren redistribuir los datos, lo que lleva tiempo adicional.
Tablas replicadas
Una tabla replicada proporciona el rendimiento de consultas más rápido para tablas pequeñas.
Una tabla que se replica tiene una copia completa de la tabla almacenada en la caché de cada nodo de proceso. Por lo tanto, al replicar una tabla se elimina la necesidad de transferir sus datos de un nodo de proceso a otro antes de una combinación o agregación. Las tablas replicadas se usan mejor con tablas pequeñas. Se requiere almacenamiento adicional y hay sobrecargas adicionales que se producen al escribir datos que hacen que las tablas grandes sean poco prácticas.
En el diagrama siguiente se muestra una tabla replicada que se almacena en caché en la primera distribución de cada nodo de proceso.

Contenido relacionado
Ahora que ya sabe un poco sobre Azure Synapse, aprenda a crear un grupo de SQL dedicada (anteriormente SQL DW) rápidamente y a cargar datos de ejemplo. Si no está familiarizado con Azure, los conceptos básicos de Azure podrían resultarle útiles a medida que encuentre terminología nueva. También, puede examinar algunos de estos otros recursos de Azure Synapse.