Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El almacenamiento en caché es una técnica esencial para mejorar el rendimiento de los sistemas de almacenamiento de datos evitando la necesidad de volver a calcular o capturar los mismos datos varias veces. En Databricks SQL, el almacenamiento en caché puede acelerar significativamente la ejecución de consultas y minimizar el uso del almacenamiento, lo que mejorará la eficacia del uso de recursos y reducirá los costes. Cada capa de almacenamiento en caché mejora el rendimiento de las consultas, minimiza el uso del clúster y optimiza el uso de recursos para lograr una experiencia de almacenamiento de datos libre de problemas.
El almacenamiento en caché proporciona numerosas ventajas en el almacenamiento de datos, entre las que se incluyen:
- Velocidad: al almacenar los resultados de las consultas o los datos a los que se accede con frecuencia en la memoria u otros medios de almacenamiento rápido, el almacenamiento en caché puede reducir considerablemente los tiempos de ejecución de consultas. Este almacenamiento es especialmente beneficioso para las consultas repetitivas, ya que el sistema puede recuperar rápidamente los resultados almacenados en caché en lugar de volver a calcularlos.
- Uso reducido del clúster: el almacenamiento en caché minimiza la necesidad de recursos de proceso adicionales gracias a la reutilización de los resultados calculados anteriormente. Esto reducirá el tiempo de actividad general del almacenamiento y la demanda de clústeres de proceso adicionales, lo que provocará un ahorro de costes y una mejor asignación de recursos.
Tipos de caché de consultas en Databricks SQL
Databricks SQL realiza varios tipos de almacenamiento en caché de consultas.
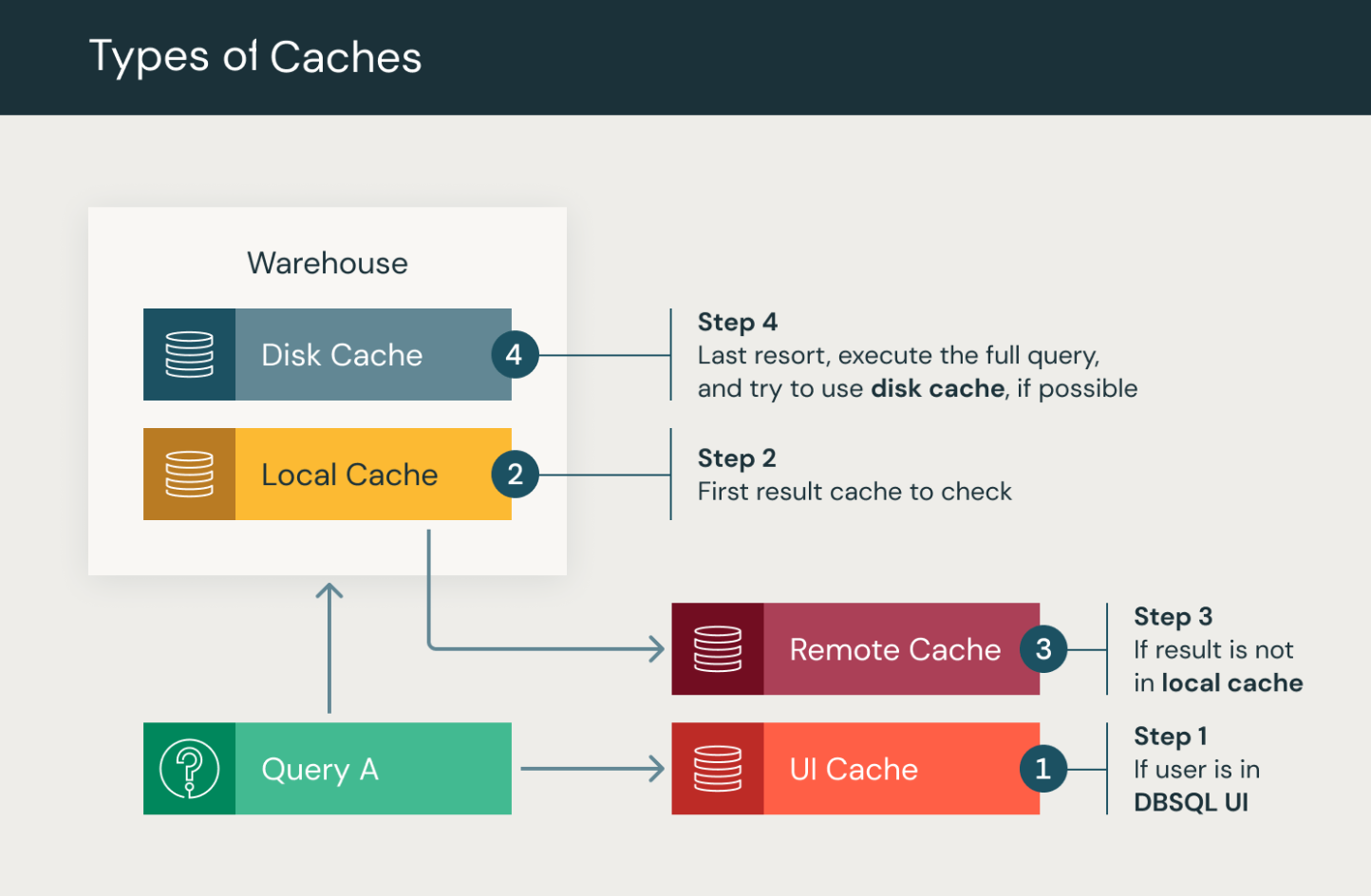
Caché de la interfaz de usuario de SQL de Databricks: almacenamiento en caché por usuario de los resultados de la consulta y visualizaciones del editor de SQL en la interfaz de usuario de Databricks SQL. Cuando un usuario abre por primera vez una consulta SQL o un panel de SQL heredado, la caché de la interfaz de usuario de SQL de Databricks muestra el resultado de la consulta más reciente, incluidos los resultados de las ejecuciones programadas.
Note
La caché de la interfaz de usuario de SQL de Databricks no se aplica a los paneles de INTELIGENCIA ARTIFICIAL o BI (anteriormente paneles de Lakeview). Los paneles de IA/BI tienen su propio comportamiento de almacenamiento en caché. Vea la optimización y almacenamiento en caché del conjunto de datos .
La memoria caché de la interfaz de usuario de SQL de Databricks tiene como máximo un ciclo de vida de 7 días. La memoria caché se encuentra dentro del sistema de archivos de Azure Databricks de su cuenta. Para eliminar los resultados de consulta, vuelva a ejecutar la consulta que ya no quiere almacenar. Una vez que se vuelve a ejecutar, los resultados de consulta antiguos se quitan de la caché. Además, la memoria caché se invalida una vez que se actualicen las tablas subyacentes.
Almacenamiento en caché de resultados: almacenamiento en caché por clúster de los resultados de consulta para todas las consultas mediante almacenes de SQL. El almacenamiento en caché de resultados incluye tanto cachés de resultados locales como remotas, que funcionan conjuntamente para mejorar el rendimiento de las consultas almacenando los resultados de la consulta en medios de almacenamiento remoto o en memoria.
- Caché local: la caché local es una caché en memoria que almacena los resultados de la consulta durante la vigencia del clúster o hasta que la memoria caché está llena, lo que ocurra primero. Esta memoria caché resulta útil para acelerar las consultas repetitivas, lo que eliminará la necesidad de volver a calcular los mismos resultados. Sin embargo, una vez que se detenga o se reinicie el clúster, se limpiará la memoria caché y se quitarán todos los resultados de la consulta.
- Caché remoto de resultados: la caché remota de resultados es un sistema de caché exclusivo para entornos sin servidor que conserva los resultados de las consultas al persistirlos como datos del sistema del espacio de trabajo. Como resultado, esta caché no se invalida al detenerse o reiniciarse un almacenamiento de SQL. La caché remota de resultados resuelve un problema habitual del almacenamiento en caché en memoria de los resultados de las consultas, que solo permanece disponible mientras los recursos de cómputo están en ejecución. La caché remota es una caché compartida persistente en todos los almacenes de un área de trabajo de Databricks.
Acceder a la caché remota de resultados requiere un warehouse en ejecución. Al procesar consultas, un clúster buscará primero en su caché local y, luego, en la caché remota si fuera necesario. Solo si el resultado de la consulta no se almacena en caché en ninguna de las cachés se ejecuta la consulta. Tanto la caché local como la remota tienen un ciclo de vida de 24 horas, que comienza cuando se crea la entrada de caché. La caché remota de resultados persiste aunque se detenga o reinicie un almacenamiento de SQL. Ambas cachés se invalidan cuando se actualizan las tablas subyacentes.
La caché de resultados remota está disponible para las consultas que usan clientes ODBC/JDBC y la API de instrucciones SQL.
Para deshabilitar el almacenamiento en caché de resultados de consulta, puede ejecutar
SET use_cached_result = falseen el editor SQL.Importante
Debe usar esta opción solo en pruebas o como punto de referencia.
Almacenamiento en caché en disco: almacenamiento en caché SSD local para los datos leídos del almacenamiento de datos para las consultas mediante almacenes de SQL. La caché de disco está diseñada para mejorar el rendimiento de las consultas mediante el almacenamiento de datos en disco, lo que permite lecturas de datos aceleradas. Los datos se almacenan automáticamente en caché cuando se capturan los archivos, utilizando un formato intermedio rápido. Al almacenar copias de los archivos en el almacenamiento local adjunto a los nodos de proceso, la memoria caché de disco garantizará que los datos se encuentren más cerca de los trabajos, lo que da lugar a una mejora del rendimiento de las consultas. Consulte Optimización del rendimiento con el almacenamiento en caché en Azure Databricks.
Además de su función principal, la memoria caché de disco detecta automáticamente los cambios en los archivos de datos subyacentes. Cuando detecta cambios, la memoria caché se invalida. La caché de disco comparte las mismas características de ciclo de vida que la caché de resultados local. Esto significa que, cuando se detenga o reinicie el clúster, la memoria caché se limpiará y deberá volver a llenarse.
El almacenamiento en caché de resultados de consulta y la caché de disco afectan a las consultas de la interfaz de usuario de Databricks SQL y BI y otros clientes externos.