Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Stream Analytics unterstützt die benutzerdefinierte Blobausgabepartitionierung mit benutzerdefinierten Feldern oder Attributen und benutzerdefinierten DateTime-Pfadmustern.
Benutzerdefiniertes Feld oder Attribute
Durch Verwendung eines benutzerdefinierten Felds oder von Eingabeattributen ist eine größere Kontrolle über die Ausgabe möglich, sodass Workflows zur Verarbeitung von Downstreamdaten und zur Berichterstellung verbessert werden.
Optionen für den Partitionsschlüssel
Der Partitionsschlüssel oder Spaltenname, der zum Partitionieren von Eingabedaten verwendet wird, kann ein beliebiges Zeichen enthalten, das für Blobnamen akzeptiert wird. Sie können geschachtelte Felder nicht als Partitionsschlüssel verwenden, es sei denn, Sie verwenden sie zusammen mit Aliasen. Sie können jedoch bestimmte Zeichen verwenden, um eine Hierarchie von Dateien zu erstellen. Beispielsweise können Sie mit der folgenden Abfrage eine Spalte erstellen, in der Daten aus zwei anderen Spalten kombiniert werden, um einen eindeutigen Partitionsschlüssel zu erzeugen.
SELECT name, id, CONCAT(name, "/", id) AS nameid
Der Partitionsschlüssel muss NVARCHAR(MAX), BIGINT, FLOAT oder BIT (Kompatibilitätsstufe 1.2 oder höher) sein. Die Typen DateTime, Array und Records werden nicht unterstützt, können aber als Partitionsschlüssel verwendet werden, wenn sie in Zeichenfolgen konvertiert werden. Weitere Informationen finden Sie unter Azure Stream Analytics-Datentypen.
Partitions-BLOB-Ausgabe durch ein benutzerdefiniertes Feld
Angenommen, in einem Auftrag werden Eingabedaten von Live-Benutzersitzungen erfasst, die mit einem externen Dienst für Videospiele verbunden sind, wobei die erfassten Daten zum Identifizieren der Sitzungen die Spalte client_id enthalten. Zum Partitionieren der Daten nach client_id legen Sie das Feld für das Pfadmuster des Blobs so fest, dass es beim Erstellen eines Auftrags das Partitionstoken {client_id} in Blobausgabeeigenschaften enthält. Da Daten mit verschiedenen Werten für client_id durch den Stream Analytics-Auftrag geleitet werden, erfolgt die Speicherung der Ausgabedaten basierend auf einem einzelnen client_id-Wert pro Ordner in separaten Ordnern.

Wenn die Auftragseingabe aus Sensordaten von Millionen Sensoren besteht und jeder Sensor einen sensor_id-Wert hat, wäre das Pfadmuster {sensor_id}, um die Sensordaten der einzelnen Sensoren in verschiedene Ordner zu verteilen.
Bei Verwendung der REST-API sieht der Ausgabeausschnitt einer für diese Anforderung verwendeten JSON-Datei beispielsweise wie folgt aus:

Nachdem der Auftrag gestartet ist, sieht der clients-Container möglicherweise wie das folgende Bild aus:
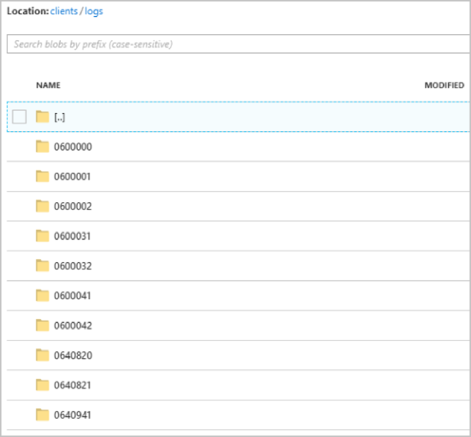
Jeder Ordner kann mehrere Blobs enthalten, und jedes Blob enthält einen oder mehrere Datensätze. Im vorherigen Beispiel ist ein einzelnes Blob in einem Ordner mit der Bezeichnung „"06000000"“ mit den folgenden Inhalten enthalten:

Beachten Sie, dass jeder Datensatz im Blob die Spalte client_id enthält, die mit dem Ordnernamen übereinstimmt, da client_id die Spalte war, die für die Partitionierung der Ausgabe im Ausgabepfad verwendet wurde.
Einschränkungen des benutzerdefinierten Partitionsschlüssels
Nur ein benutzerdefinierter Partitionsschlüssel ist in der Blobausgabeeigenschaft des Pfadmusters zulässig. Alle der folgenden Pfadmuster sind gültig:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Wenn Sie mehr als ein Eingabefeld verwenden möchten, können Sie in einer Abfrage mithilfe von
CONCATeinen zusammengesetzten Schlüssel für die benutzerdefinierte Pfadpartitionierung in der Blobausgabe erstellen. z. B.select concat (col1, col2) as compositeColumn into blobOutput from input. Anschließend können Sie in Azure Blob Storage als benutzerdefinierten Pfad angebencompositeColumn.Bei Partitionsschlüsseln wird die Groß- und Kleinschreibung nicht beachtet, sodass Partitionsschlüssel wie
Johnundjohnidentisch sind. Außerdem können Sie Ausdrücke nicht als Partitionsschlüssel verwenden. Beispielsweise funktioniert{columnA + columnB}nicht.Wenn ein Eingabedatenstrom aus Datensätzen mit einer Partitionsschlüssel-Kardinalität unter 8.000 besteht, fügt Stream Analytics die Datensätze an vorhandene Blobs an und erstellt nur bei Bedarf neue Blobs. Wenn die Kardinalität über 8.000 liegt, besteht keine Garantie dafür, dass Stream Analytics in vorhandene Blobs schreibt. Stream Analytics erstellt keine neuen Blobs für eine beliebige Anzahl von Datensätzen mit demselben Partitionsschlüssel.
Wenn die Blobausgabe als unveränderlich konfiguriert ist, erstellt Stream Analytics bei jedem Senden von Daten ein neues Blob.
Benutzerdefinierte DateTime-Pfadmuster
Mit benutzerdefinierten DateTime-Pfadmustern können Sie ein Ausgabeformat festlegen, das mit den Hive Streaming-Konventionen übereinstimmt, damit Stream Analytics Daten an Azure HDInsight und Azure Databricks zur weiteren Verarbeitung senden kann. Benutzerdefinierte DateTime-Pfadmuster können einfach mit dem Schlüsselwort datetime im Feld Pfadpräfix der Blobausgabe und dem Formatbezeichner implementiert werden. z. B. {datetime:yyyy}.
Unterstützte Token
Die folgenden Formatbezeichnertoken können einzeln oder in Kombination verwendet werden, um benutzerdefinierte DateTime-Formate zu erhalten.
| Formatspezifizierer | BESCHREIBUNG | Ergebnisse zur Beispielzeit 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Das Jahr als vierstellige Zahl | 2018 |
| {datetime:MM} | Monat von 01 bis 12 | 01 |
| {datetime:M} | Monat von 1 bis 12 | 1 |
| {datetime:dd} | Tag von 01 bis 31 | 02 |
| {datetime:d} | Tag von 1 bis 31 | 2 |
| {datetime:HH} | Stunde im 24-Stunden-Format, von 00 bis 23 | 10 |
| {datetime:mm} | Minuten von 00 bis 60 | 06 |
| {datetime:m} | Minuten von 0 bis 60 | 6 |
| {datetime:ss} | Sekunden von 00 bis 60 | 08 |
Wenn Sie keine benutzerdefinierten DateTime-Muster verwenden möchten, können Sie das Token {date} und/oder {time} zum Feld Pfadpräfix hinzufügen, um eine Dropdownliste mit integrierten DateTime-Formaten zu generieren.

DateTime-Tokenerweiterung und Einschränkungen
Sie können beliebig viele Token ({datetime:<specifier>}) im Pfadmuster verwenden, bis Sie den Zeichengrenzwert für das Pfadpräfix erreichen. Formatbezeichner können innerhalb eines einzelnen Tokens nicht über die bereits in den Dropdownlisten für Datum und Uhrzeit aufgeführten Kombinationen hinaus kombiniert werden.
Für eine Pfadpartition von logs/MM/dd:
| Gültiger Ausdruck | Ungültiger Ausdruck |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Sie können denselben Formatbezeichner mehrmals im Pfadpräfix verwenden. Das Token muss jedes Mal wiederholt werden.
Hive-Streaming-Konventionen
Sie können benutzerdefinierte Pfadmuster für Blob Storage mit der Hive-Streaming-Konvention verwenden, die erwartet, dass Ordner im Ordnernamen mit column= gekennzeichnet sind.
z. B. year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Die benutzerdefinierte Ausgabe erübrigt das mühevolle Ändern von Tabellen und das manuelle Hinzufügen von Partitionen zu Portdaten zwischen Stream Analytics und Hive. Stattdessen können viele Ordner automatisch wie folgt hinzugefügt werden:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Hive-kompatible DateTime-Ordnerstruktur erstellen
Erstellen Sie ein Speicherkonto, eine Ressourcengruppe, einen Stream Analytics-Auftrag und eine Eingabequelle gemäß der Schnellstartanleitung Schnellstart: Erstellen eines Stream Analytics-Auftrags mithilfe des Azure-Portals. Verwenden Sie dieselben Beispieldaten wie in der Schnellstartanleitung. Beispieldaten ist auch auf GitHub verfügbar.
Erstellen Sie eine Ausgabesenke für Blobs mit der folgenden Konfiguration.

Das vollständige Pfadmuster ist:
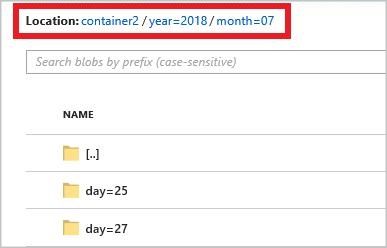
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Wenn Sie den Auftrag starten, wird in Ihrem Blobcontainer eine Ordnerstruktur basierend auf dem Pfadmuster erstellt. Sie können einen Drilldown bis zur Tagesebene ausführen.