Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite wird erläutert, wie Sie eine Verbindung mit einem SQL-Warehouse herstellen, Dateien und Daten durchsuchen und Abfragen im neuen Databricks SQL-Editor schreiben.
Verbindung mit Computeressource herstellen
Sie müssen über mindestens CAN USE-Berechtigungen für ein SQL-Warehouse verfügen, um Abfragen auszuführen. Sie können die Dropdownliste am oberen Rand des Editors verwenden, um die verfügbaren Optionen anzuzeigen. Um die Liste zu filtern, geben Sie Text in das Suchfeld ein.

Wenn Sie über ein SQL-Standardlager verfügen, verwendet der SQL-Editor diese automatisch, wenn Sie eine Abfrage erstellen. Wenn kein Standardlager festgelegt ist, wählen Sie aus einer alphabetischen Liste der verfügbaren Lagerhäuser aus. Nachfolgende Abfragen verwenden das letzte ausgewählte Lager. Informationen zum Festlegen eines Standardlagers finden Sie unter Festlegen eines Standardlagers auf Benutzerebene.
Das Symbol neben dem SQL-Warehouse gibt den Status an:
- Wird ausgeführt

- Angehalten
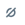
Note
Sollten die Liste keine SQL-Warehouses enthalten, wenden Sie sich an Ihre Arbeitsbereichsadministrator*innen.
Das ausgewählte SQL-Warehouse wird automatisch neu gestartet, wenn Sie die Abfrage ausführen. Weitere Möglichkeiten zum Starten eines SQL-Warehouse finden Sie unter Starten eines SQL-Warehouse.
Ressourcen durchsuchen und Hilfe erhalten
Verwenden Sie den linken Bereich im SQL-Editor, um Arbeitsbereichsdateien zu suchen, Datenobjekte anzuzeigen und Hilfe von Genie Code zu erhalten.

Durchsuchen von Arbeitsbereichsdateien
Klicken Sie auf ![]() auf das Ordnersymbol, um den Benutzerordner des Arbeitsbereichs zu öffnen. Sie können zu allen Arbeitsbereichsdateien wechseln, auf die Sie über diesen Teil der Benutzeroberfläche zugreifen können.
auf das Ordnersymbol, um den Benutzerordner des Arbeitsbereichs zu öffnen. Sie können zu allen Arbeitsbereichsdateien wechseln, auf die Sie über diesen Teil der Benutzeroberfläche zugreifen können.
Durchsuchen von Datenobjekten
Wenn Sie über die Berechtigung zum Lesen von Metadaten verfügen, werden im Schemabrowser des SQL-Editors die verfügbaren Datenbanken und Tabellen angezeigt. Sie können auch im Katalog-Explorer nach Datenobjekten suchen.
Sie können über Unity Catalog-gesteuerte Datenbankobjekte im Katalog-Explorer navigieren, ohne aktiven Rechenleistung zu nutzen. Um Daten in hive_metastore und anderen Katalogen zu erkunden, die nicht dem Unity-Katalog unterliegen, müssen Sie eine Verbindung zu einem Compute mit den entsprechenden Berechtigungen herstellen. Siehe Data Governance mit Azure Databricks.
Note
Wenn im Schemabrowser oder im Katalog-Explorer keine Datenobjekte vorhanden sind, wenden Sie sich an die Arbeitsbereichsadministrator*innen.
Wählen Sie am oberen Rand des Schemabrowsers ![]() aus, um das Schema zu aktualisieren. Sie können Text in die Suchleiste eingeben, um Ressourcen nach Namen zu filtern. Klicken Sie auf das
aus, um das Schema zu aktualisieren. Sie können Text in die Suchleiste eingeben, um Ressourcen nach Namen zu filtern. Klicken Sie auf das ![]() , um Objekte nach Typ zu filtern.
, um Objekte nach Typ zu filtern.
Klicken Sie im Browser auf den Namen eines Objekts, um weitere Details zum Objekt anzuzeigen. Klicken Sie beispielsweise auf einen Schemanamen, um die Tabellen in diesem Schema anzuzeigen. Klicken Sie auf einen Tabellennamen, um die Spalten in dieser Tabelle anzuzeigen.
Hilfe von Genie Code erhalten
Klicken Sie auf ![]() Genie Code-Symbol zum Öffnen eines Chatfensters mit Genie Code. Klicken Sie auf eine vorgeschlagene Frage, oder geben Sie Ihre eigene Frage ein, um mit Genie Code zu interagieren.
Genie Code-Symbol zum Öffnen eines Chatfensters mit Genie Code. Klicken Sie auf eine vorgeschlagene Frage, oder geben Sie Ihre eigene Frage ein, um mit Genie Code zu interagieren.
Erstellen einer Abfrage
Sie können Text eingeben, um im SQL-Editor eine Abfrage zu erstellen. Sie können Elemente aus dem Schemabrowser einfügen, um auf Kataloge und Tabellen zu verweisen.
Geben Sie Ihre Abfrage im SQL-Editor ein.
Der SQL-Editor unterstützt AutoVervollständigen. Während der Eingabe schlägt AutoVervollständigen Vervollständigungen vor. Wenn beispielsweise eine gültige Vervollständigung an der Cursorposition eine Spalte ist, schlägt AutoVervollständigen einen Spaltennamen vor. Wenn Sie
select * from table_name as t where t.eingeben, erkennt AutoVervollständigen, dasstein Alias fürtable_nameist, und schlägt die Spalten intable_namevor. Sie können auch AutoVervollständigen verwenden, um auf Abfrageausschnitte zu verweisen.
(Optional) Wenn Sie die Bearbeitung beendet haben, klicken Sie auf Speichern. Standardmäßig wird die Abfrage im Ordner "Start" des Benutzers gespeichert. Um die Abfrage an einem anderen Speicherort zu speichern, wählen Sie den Zielordner aus, und klicken Sie auf "Verschieben".
Note
Neue Abfragen werden automatisch als neue Abfrage bezeichnet, wobei der Erstellungszeitstempel im Titel angefügt wird. Standardmäßig werden neue Abfragen, die ohne einen bestimmten Ordnerkontext erstellt wurden, im Ordner "Entwürfe" in Ihrem Startverzeichnis erstellt. Wenn neue Abfragen gespeichert oder umbenannt werden, werden sie aus Entwürfen entfernt.
Abfragen von Datenquellen
Sie können eine Abfragequelle mithilfe eines vollqualifizierten Tabellennamens in der Abfrage selbst identifizieren oder eine Kombination aus Katalog und Schema aus den Dropdownselektoren zusammen mit dem Tabellennamen in der Abfrage auswählen. Ein vollqualifizierter Tabellenname in der Abfrage setzt den Katalog und die Schemaselektoren im SQL-Editor außer Kraft. Wenn ein Tabellen- oder Spaltenname Leerzeichen enthält, schließen Sie diese Bezeichner in Ihren SQL-Abfragen in Backticks ein.
Note
Die maximale Anzahl der in einer Tabelle zurückgegebenen Ergebnisse beträgt 64.000 Zeilen oder 10 MB, je nachdem, was kleiner ist.
Die folgenden Beispiele veranschaulichen, wie Sie verschiedene tabellenähnliche Objekte abfragen, die Sie in einem Katalog speichern können.
Standardtabelle oder -ansicht abfragen
Im folgenden Beispiel wird eine Tabelle aus dem samples Katalog abgerufen.
SELECT
o_orderdate,
o_orderkey,
o_custkey,
o_totalprice,
o_shippriority
FROM
samples.tpch.orders
Abfragen einer Metrik-Ansicht
Das folgende Beispiel fragt eine Metrikansicht ab, die eine Tabelle aus dem Beispielkatalog als Quelle verwendet. Es wertet die drei aufgelisteten Maßnahmen aus und aggregiert über Order Month und Order Status. Sie erhalten die Ergebnisse sortiert nach Order Month. Informationen zum Erstellen einer ähnlichen Metrikansicht in Ihrem Arbeitsbereich finden Sie im Lernprogramm: Erstellen einer vollständigen Metrikansicht mit Verknüpfungen.
Alle Maßnahmebewertungen müssen in die MEASURE Funktion eingewickelt werden. Siehe measure Aggregatfunktion.
SELECT
`Order Month`,
`Order Status`,
MEASURE(`Order Count`),
MEASURE(`Total Revenue`),
MEASURE(`Total Revenue per Customer`)
FROM
orders_metric_view
GROUP BY ALL
ORDER BY 1 ASC;
Optimieren einer Abfrage mit Genie Code
Klicken Sie auf das ![]() Assistentensymbol auf der rechten Seite des Editors, um Inlinehilfe und Vorschläge beim Schreiben von Abfragen zu erhalten. Der
Assistentensymbol auf der rechten Seite des Editors, um Inlinehilfe und Vorschläge beim Schreiben von Abfragen zu erhalten. Der /optimize-Schrägstrichbefehl fordert den Assistenten auf, Abfragen auszuwerten und zu optimieren. Weitere Informationen finden Sie unter Optimieren von Python, PySpark und SQL-Code.

Mehrere Abfragen-Registerkarten bearbeiten
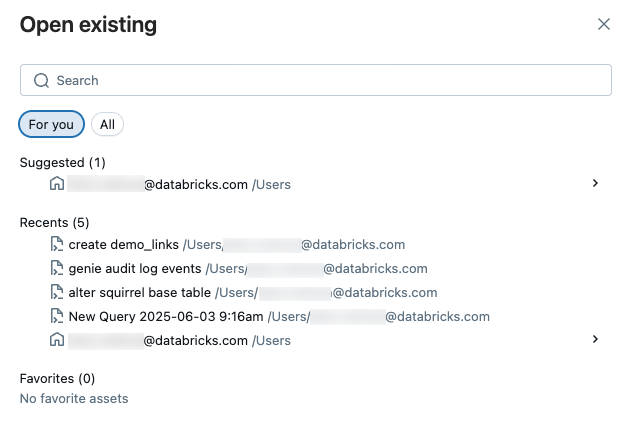
Standardmäßig verwendet der SQL-Editor Registerkarten, sodass Sie mehrere Abfragen gleichzeitig öffnen und bearbeiten können. Um eine neue Registerkarte zu öffnen, klicken Sie auf +, und wählen Sie dann Neue Abfrage erstellen oder Vorhandene Abfrage öffnen aus. Klicken Sie auf "Vorhandene Abfrage öffnen ", um eine Liste von Abfragen anzuzeigen. Auf der Registerkarte "Für Sie " wird eine kuratierte Liste der Sugestions basierend auf Ihrer Nutzung angeboten. Verwenden Sie die Registerkarte "Alle ", um eine beliebige Abfrage zu finden, auf die Sie Zugriff haben.
Speichern einer Abfrage
Abfrageinhalte im neuen SQL-Editor werden kontinuierlich automatisch gespeichert. Die Schaltfläche " Speichern " steuert, ob der Inhalt der Entwurfsabfrage auf verwandte Objekte angewendet werden soll, z. B. Workflows oder ältere Warnungen. Wenn die Abfrage für die Anmeldeinformationen " Als Besitzer ausführen" geteilt wird, kann nur der Abfragebesitzer die Schaltfläche "Speichern " verwenden, um Änderungen zu verteilen. Wenn die Anmeldeinformationen auf "Als Viewer ausführen" festgelegt sind, kann jeder Benutzer mit mindestens CAN MANAGE berechtigungen die Abfrage speichern.
Quellcodeverwaltung einer Abfrage
Databricks SQL-Abfragedateien (Dateierweiterung: .dbquery.ipynb) werden in Databricks Git-Ordnern unterstützt. Sie können einen Git-Ordner verwenden, um Ihre Abfragedateien zu steuern und sie in anderen Arbeitsbereichen für Git-Ordner freizugeben, die auf dasselbe Git-Repository zugreifen. Wenn Sie sich entscheiden, nach dem Commit oder Klonen einer Abfrage in einem Databricks-Git-Ordner den neuen SQL-Editor nicht mehr zu verwenden, löschen Sie diesen Git-Ordner und klonen ihn erneut, um unerwartete Verhaltensweisen zu vermeiden.