Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite wird erläutert, wie Sie die serverlose Umgebung für Notizbücher und Auftragsaufgaben konfigurieren. Verwenden Sie für Notizbücher den Seitenbereich "Umgebung ", um eine Basisumgebung auszuwählen, Abhängigkeiten zu installieren, Arbeitsspeicher zu konfigurieren und Nutzungsrichtlinien anzuwenden. Konfigurieren Sie bei Auftragsaufgaben die Umgebung, wenn Sie eine Aufgabe erstellen oder bearbeiten.
Um die Umgebung-Seitenleiste auszuklappen, klicken Sie rechts neben dem Notebook auf die Schaltfläche ![]() .
.

Auswählen einer Basisumgebung
Eine Basisumgebung bestimmt die vorinstallierten Bibliotheken und Umgebungsversion, die für Ihr serverloses Notizbuch verfügbar ist. Die Basisumgebungsauswahl im Seitenbereich "Umgebung " ist der Ort, an dem Sie Ihre Umgebung auswählen. Informationen zu den einzelnen Umgebungsversionen finden Sie unter Serverless Environment Versions. Databricks empfiehlt die Verwendung der neuesten Version, um die meisten up-to-date-Notizbuchfunktionen zu erhalten.
Die Auswahl der Basisumgebung umfasst die folgenden Optionen:
- Standard: Die standardmäßige serverlose Basisumgebung mit von Databricks bereitgestellten Bibliotheken.
- ML (Beta): Eine Basisumgebung mit den Python und Systempaketen von Databricks Runtime für Machine Learning vorinstalliert. Verwenden Sie diese Umgebung, um die klassische Databricks-Runtime für Machine Learning Workloads auf serverlose Berechnung zu migrieren. Siehe ML-Basisumgebung.
- KI: Eine KI-optimierte Basisumgebung mit vorinstallierten ML-Bibliotheken (Machine Learning). Diese Option wird nur angezeigt, wenn ein Beschleuniger (GPU) ausgewählt ist.
-
Weitere Optionen: Erweitert, um weitere Optionen anzuzeigen:
- Frühere Versionen von Standard-, ML- und KI-Umgebungen.
- Benutzerdefiniert: Geben Sie eine benutzerdefinierte Umgebung mithilfe einer YAML-Datei an.
- Arbeitsbereichsumgebungen: Listet alle kompatiblen Basisumgebungen auf, die von einem Administrator für Ihren Arbeitsbereich konfiguriert wurden.
So wählen Sie eine Basisumgebung aus:
- Klicken Sie in der Notebook-Benutzeroberfläche auf den Seitenbereich
 Environment.
Environment. - Wählen Sie unter "Basisumgebung" im Dropdownmenü eine Umgebung aus.
- Klicken Sie auf Anwenden.
Hinzufügen von Abhängigkeiten zum Notizbuch
Da Serverless keine Compute-Richtlinien oder Initialisierungsskripts unterstützt, müssen Sie benutzerdefinierte Abhängigkeiten über den Seitenbereich Environment installieren. Sie können Abhängigkeiten einzeln installieren oder eine gemeinsam nutzbare Basisumgebung verwenden, um mehrere Abhängigkeiten zu installieren.
Azure Databricks die virtuelle Umgebung Ihres Notizbuchs zwischenspeichert, sodass Abhängigkeiten nicht jedes Mal neu installiert werden, wenn Sie ein Notizbuch erneut öffnen oder nach inaktivität fortsetzen. Auftragsaufgaben, die denselben Abhängigkeitssatz gemeinsam nutzen, profitieren auch von diesem Cache innerhalb einer Ausführung.
So installieren Sie eine Abhängigkeit einzeln:
Klicken Sie in der Notebook-Benutzeroberfläche auf den Seitenbereich Umgebung
.Klicken Sie im Abschnitt "Abhängigkeiten" auf "Abhängigkeit hinzufügen ", und geben Sie den Pfad der Abhängigkeit in das Feld ein. Sie können eine Abhängigkeit in einem beliebigen Format angeben, das in einer Datei vom Typ requirements.txt gültig ist. Python-Wheel-Dateien oder Python-Projekte (z. B. das Verzeichnis mit einem
pyproject.tomloder einemsetup.py) können sich in Arbeitsbereichs-Dateien oder Unity-Katalogvolumen befinden.- Wenn Sie eine Datei des Arbeitsbereichs verwenden, sollte der Pfad absolut sein und mit
/Workspace/beginnen. - Wenn Sie eine Datei in einem Unity-Katalogvolume verwenden, sollte der Pfad im folgenden Format vorliegen:
/Volumes/<catalog>/<schema>/<volume>/<path>.whl
- Wenn Sie eine Datei des Arbeitsbereichs verwenden, sollte der Pfad absolut sein und mit
Klicken Sie auf Apply, um die Abhängigkeiten zu installieren und den Python Prozess neu zu starten.
Important
Installieren Sie weder PySpark noch Bibliotheken, die PySpark als Abhängigkeit installieren, in Ihren serverlosen Notebooks. Das Ausführen dieser Aktion wird Ihre Sitzung beenden und einen Fehler verursachen. Entfernen Sie in diesem Fall die Bibliothek, und setzen Sie Ihre Umgebung zurück.
Um installierte Abhängigkeiten anzuzeigen, klicken Sie im Seitenbereich "Umgebungen" auf die Registerkarte "Installiert". Öffnen Sie die pip-Installationsprotokolle für die Notebook-Umgebung, indem Sie am unteren Rand des Bereichs auf pip-Logs klicken.
Note
Administratoren des Arbeitsbereichs können private oder authentifizierte Paket-Repositorys als Standardquelle für pip für serverlose Notebooks und Jobs konfigurieren. Auf diese Weise können Benutzer Pakete aus internen Repositorys installieren, ohne index-url oder extra-index-url anzugeben. Siehe Standard-Python-Paket-Repositories konfigurieren.
Erstellen einer benutzerdefinierten Umgebungsspezifikation
Sie können benutzerdefinierte Umgebungsspezifikationen erstellen und wiederverwenden.
- Wählen Sie in einem serverlosen Notizbuch eine Basisumgebung aus, und installieren Sie alle gewünschten Abhängigkeiten.
- Klicken Sie auf das
 Klicken Sie unten im Umgebungsbereich auf das Kebab-Menüsymbol, und klicken Sie dann auf "Umgebung exportieren".
Klicken Sie unten im Umgebungsbereich auf das Kebab-Menüsymbol, und klicken Sie dann auf "Umgebung exportieren". - Speichern Sie die Spezifikation als Arbeitsbereichsdatei oder in einem Unity-Katalogvolume.
Wenn Sie Ihre benutzerdefinierte Umgebungsspezifikation in einem Notizbuch verwenden möchten, wählen Sie im Dropdownmenü "Basisumgebung" die Option "Benutzerdefiniert" aus, und verwenden Sie dann das ![]() um Ihre YAML-Datei auszuwählen.
um Ihre YAML-Datei auszuwählen.
Erstellen allgemeiner Tools für die gemeinsame Nutzung in Ihrem Arbeitsbereich
In diesem Beispiel wird ein Dienstprogramm in einer Arbeitsbereichsdatei gespeichert und als serverlose Notizbuchabhängigkeit installiert:
Erstellen Sie einen Ordner mit der folgenden Struktur. Stellen Sie sicher, dass andere Benutzer Lesezugriff auf diesen Pfad haben:
helper_utils/ ├── helpers/ │ └── __init__.py # your common functions live here ├── pyproject.tomlFüllen Sie dies
pyproject.tomlwie folgt aus:[project] name = "common_utils" version = "0.1.0"Fügen Sie der
init.pyDatei eine Funktion hinzu. Beispiel:def greet(name: str) -> str: return f"Hello, {name}!"Klicken Sie in der Notebook-Benutzeroberfläche auf den Seitenbereich Umgebung

Klicken Sie im Abschnitt "Abhängigkeiten" auf "Abhängigkeit hinzufügen ", und geben Sie dann den Pfad der util-Datei ein. Beispiel:
/Workspace/helper_utils.Klicken Sie auf Anwenden.
Sie können nun die Funktion in Ihrem Notizbuch verwenden:
from helpers import greet
print(greet('world'))
Das wird ausgegeben als:
Hello, world!
Verwenden der KI-Runtime (serverlose GPU)
Important
Die AI-Runtime befindet sich in der öffentlichen Vorschau.
Führen Sie die folgenden Schritte aus, um die AI Runtime, die auf serverloser GPU-Rechenleistung basiert, in Ihrem Azure Databricks-Notebook zu konfigurieren:
- Klicken Sie in einem Notizbuch oben auf das Dropdownmenü "Compute", und wählen Sie "Serverless GPU" aus.
- Klicken Sie auf das Um den Seitenbereich "Umgebung " zu öffnen.
- Wählen Sie A10 aus dem Feld Beschleuniger aus.
- Wählen Sie unter "Basisumgebung" die Option "Standard " für die Standardumgebung oder KI für die KI-optimierte Umgebung mit vorinstallierten ML-Bibliotheken (Machine Learning) aus.
- Klicken Sie auf Übernehmen und Bestätigen Sie dann, dass Sie AI-Runtime auf Ihre Notebook-Umgebung anwenden möchten.
Weitere Details finden Sie unter AI Runtime.
Verwenden Sie serverlose Berechnung mit hohem Speicherbedarf
Important
Dieses Feature befindet sich in der Public Preview.
Wenn in Ihrem Notizbuch Fehler im Arbeitsspeicher auftreten, konfigurieren Sie das Notizbuch so, dass eine höhere Arbeitsspeichergröße verwendet wird. Diese Einstellung für die Arbeitsspeichergröße erhöht die Größe des REPL-Speichers, der beim Ausführen von Code im Notizbuch verwendet wird. Sie wirkt sich nicht auf die Speichergröße der Spark-Sitzung aus. Die serverlose Verwendung mit hohem Arbeitsspeicher hat eine höhere DBU-Emissionsrate als standardspeicher.
Die verfügbaren Speicheroptionen sind:
- Standard: 16 GB Gesamtspeicher.
- Hoch: 32 GB Gesamtspeicher.
So konfigurieren Sie die Speichereinstellung des Notizbuchs:
- Klicken Sie in der Notebook-Benutzeroberfläche im Seitenbereich Umgebung auf .
- Unter Speicherwählen Sie Hoher Arbeitsspeicheraus.
- Klicken Sie auf Anwenden.
Diese Speichereinstellung gilt auch für Notebook-Aufgaben in Jobs, die die Speichervoreinstellungen des Notebooks verwenden. Das Aktualisieren der Speichereinstellung im Notizbuch wirkt sich auf die nächste Auftragsausführung aus.
Auswählen einer serverlosen Nutzungsrichtlinie
Important
Dieses Feature befindet sich in der Public Preview.
Serverlose Nutzungsrichtlinien ermöglichen Es Ihrer Organisation, benutzerdefinierte Tags auf serverlose Verwendung für eine differenzierte Abrechnungszuordnung anzuwenden.
Wenn Ihr Arbeitsbereich serverlose Nutzungsrichtlinien verwendet, wählen Sie die Richtlinie aus, die Sie auf das Notizbuch anwenden möchten. Wenn ein Benutzer nur einer serverlosen Nutzungsrichtlinie zugewiesen ist, gilt diese Richtlinie standardmäßig.
Nachdem Sie mit serverloser Rechenleistung verbunden sind, wählen Sie in der Seitenleiste Umgebung eine Richtlinie aus:
- Klicken Sie in der Notebook-Benutzeroberfläche auf den Seitenbereich Environment.
- Wählen Sie unter " Serverlose Nutzungsrichtlinie" die Serverlose Nutzungsrichtlinie aus, die Sie auf Ihr Notizbuch anwenden möchten.
- Klicken Sie auf Anwenden.
Nach dem Anwenden nimmt die gesamte Notizbuchverwendung die benutzerdefinierten Tags der Richtlinie auf.
Note
Wenn Ihr Notizbuch aus einem Git-Repository stammt oder ihm keine serverlose Nutzungsrichtlinie zugewiesen ist, wird die zuletzt gewählte serverlose Nutzungsrichtlinie standardmäßig verwendet, wenn es als nächstes an die serverlose Berechnung angeschlossen ist.
Einschließen der Umgebung in Quelldateiexporte
Für Python-Notebooks können Sie in der Umgebungskonfiguration die Option In Quellfile-Exporten einbeziehen aktivieren oder deaktivieren. Wenn diese Option aktiviert ist, werden die Basisumgebung und Abhängigkeiten im PEP 723-Format in Quelldateiexporten gespeichert. Dadurch wird die Umgebungskonfiguration beibehalten, wenn Notizbücher in Git-Ordnern gespeichert oder als Quelldateien heruntergeladen werden.
Beispielsweise exportiert ein Notizbuch mit Standard v5 seine Umgebungskonfiguration als Inlinemetadaten oben in der Datei:
# Databricks notebook source
# /// script
# [tool.databricks.environment]
# environment_version = "5"
# ///
print("Hello World!")
Zurücksetzen der Umgebungsabhängigkeiten
Wenn Ihr Notizbuch mit serverloser Berechnung verbunden ist, speichert Databricks den Inhalt der virtuellen Umgebung des Notizbuchs automatisch zwischen. Dies bedeutet, dass Sie die im Seitenbereich Environment angegebenen Python-Abhängigkeiten in der Regel nicht neu installieren müssen, wenn Sie ein vorhandenes Notebook öffnen, selbst wenn die Verbindung aufgrund von Inaktivität getrennt wurde.
Die Zwischenspeicherung von virtuellen Python-Umgebungen gilt auch für Jobs. Wenn ein Auftrag ausgeführt wird, wird jede Aufgabe, die dieselbe Gruppe von Abhängigkeiten wie eine abgeschlossene Aufgabe in derselben Ausführung gemeinsam verwendet, schneller abgeschlossen, da der Cache bereits die erforderlichen Abhängigkeiten enthält.
Note
Wenn Sie die Implementierung eines benutzerdefinierten Python Pakets ändern, das in einem Auftrag ohne Server verwendet wird, müssen Sie auch die Versionsnummer aktualisieren, damit Aufträge die neueste Implementierung aufnehmen können.
Um den Umgebungscache zu leeren und die im Seitenbereich Umgebung eines Notebooks, das an serverloses Computing angebunden ist, angegebenen Abhängigkeiten neu zu installieren, klicken Sie auf den Pfeil neben Übernehmen und dann auf Auf Standardwerte zurücksetzen.
Wenn Sie Pakete installieren, die das Kernnotizbuch oder die Apache Spark-Umgebung unterbrechen oder ändern, entfernen Sie die problematischen Pakete, und setzen Sie dann die Umgebung zurück. Beim Starten einer neuen Sitzung wird der gesamte Umgebungscache nicht gelöscht.
Konfigurieren der Umgebung für Auftragsaufgaben
Jede Auftragsaufgabe wird in einer isolierten Umgebung ausgeführt, die eine Basisumgebung und alle zusätzlichen Bibliotheken enthält, die Sie angeben. Die Basisumgebung legt die Python- und Scala-Laufzeitversion und vorinstallierte Bibliotheken fest. Aufgaben erben den Standardsatz der installierten Bibliotheken von der Umgebungsversion. Um zu sehen, was enthalten ist, lesen Sie den Abschnitt Installierte Python-Bibliotheken oder Installierte Java- und Scala-Bibliotheken der Umgebungsversion, die Sie verwenden.
Sie können die vorinstallierten Bibliotheken mit Bibliotheken aus Arbeitsbereichsdateien, Unity-Katalogvolumes oder öffentlichen Paketrepositorys ergänzen. Zur Laufzeit werden nur Abhängigkeiten installiert, die für die Aufgabe erforderlich sind.
Important
Die Verwendung der serverlosen Berechnung für JAR-Aufgaben befindet sich in der öffentlichen Vorschau.
Important
Die Auswahl einer verwalteten Basisumgebung befindet sich in der Betaversion. Mit der Dropdownliste "Basisumgebung " im Dialogfeld " Umgebung konfigurieren " können Sie aus databricks-bereitgestellten Umgebungen (z. B. Standard- und ML)- oder arbeitsbereichskonfigurierten Umgebungen auswählen. Ohne dieses Feature zeigt das Dialogfeld stattdessen eine Dropdownliste " Umgebungsversion " an. Arbeitsbereichsadministratoren können dieses Feature über die Vorschauseite aktivieren.

Konfigurieren der Umgebung nach Aufgabentyp
Wie Sie Umgebungen in einem Auftrag konfigurieren, hängt vom Aufgabentyp ab:
Notebook-Aufgaben
Notizbuchaufgaben werden standardmäßig in der Notizbuchumgebung verwendet, die die eigene konfigurierte Basisumgebung und Abhängigkeiten des Notizbuchs verwendet. Sie können dies mit einer Umgebung auf Job-Ebene überschreiben.

So konfigurieren Sie eine Umgebung auf Auftragsebene:
- Klicken Sie in der Aufgabenkonfiguration auf das Dropdownmenü "Umgebung und Bibliotheken ".
- Klicken Sie in der Auftragsumgebung auf das Stiftsymbol neben "Standard", oder klicken Sie auf "+Neue Auftragsumgebung hinzufügen".
- Wählen Sie im Dialogfeld " Umgebung konfigurieren " im Dropdownmenü " Basisumgebung " folgendes aus:
- Databricks-Umgebungen: Azure Databricks bereitgestellte Optionen wie Standard und ML.
- Arbeitsbereichsumgebungen: Benutzerdefinierte Umgebungen, die von Ihrem Arbeitsbereichsadministrator konfiguriert wurden. Siehe Verwalten von Arbeitsbereichsbasisumgebungen.
- Mehr: Frühere Versionen und Benutzerdefiniert (geben Sie eine YAML-Datei an).
- Fügen Sie unter Abhängigkeiten alle zusätzlichen Bibliotheken hinzu. Sie können eine Bibliothek in einem beliebigen Format angeben, das in einer requirements.txt-Datei gültig ist, oder einen absoluten Pfad zu einer Arbeitsbereichsdatei oder einem Unity Catalog-Volume verwenden.
- Klicken Sie auf Bestätigen.
Note
Wenn in Ihrem Arbeitsbereich die Arbeitsbereichsbasisumgebung für die Vorschau von Aufträgen nicht aktiviert ist, wird im Dialogfeld "Umgebung konfigurieren" anstelle der Basisumgebung eine Dropdownliste "Umgebungsversion" angezeigt.
Um die Umgebung zu konfigurieren, wählen Sie eine Version aus, und klicken Sie dann auf +Bibliothek hinzufügen. Sie können einen Dateipfad im Arbeitsbereich (beginnend mit /Workspace/), einen Unity Catalog-Volumepfad (beginnend mit /Volumes/) oder einen Verweis auf eine requirements-Datei (z. B. -r /Workspace/path/to/requirements.txt) angeben.
Python-Skript- und Python-Wheel-Aufgaben
Python-Skript- und Python-Wheel-Tasks erfordern eine konfigurierte Umgebung.
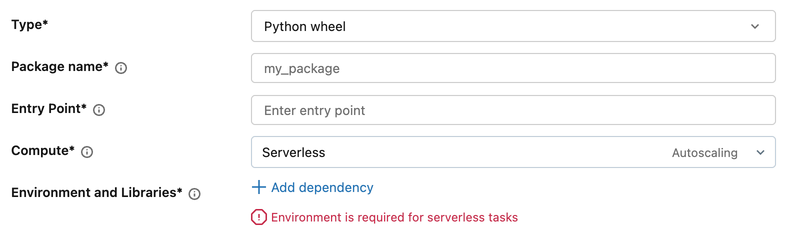
- Klicken Sie in der Aufgabenkonfiguration unter "Umgebung und Bibliotheken" auf +Abhängigkeit hinzufügen.
- Wählen Sie im Dialogfeld " Umgebung konfigurieren " im Dropdownmenü " Basisumgebung " folgendes aus:
- Databricks-Umgebungen: Azure Databricks bereitgestellte Optionen wie Standard und ML.
- Arbeitsbereichsumgebungen: Benutzerdefinierte Umgebungen, die von Ihrem Arbeitsbereichsadministrator konfiguriert wurden. Siehe Verwalten von Arbeitsbereichsbasisumgebungen.
- Mehr: Frühere Versionen und Benutzerdefiniert (geben Sie eine YAML-Datei an).
- Fügen Sie unter Abhängigkeiten alle zusätzlichen Bibliotheken hinzu.
- Klicken Sie auf Bestätigen.
Note
Wenn in Ihrem Arbeitsbereich die Arbeitsbereichsbasisumgebung für die Vorschau von Aufträgen nicht aktiviert ist, wird im Dialogfeld "Umgebung konfigurieren" anstelle der Basisumgebung eine Dropdownliste "Umgebungsversion" angezeigt.
Um die Umgebung zu konfigurieren, wählen Sie eine Version aus, und klicken Sie dann auf +Bibliothek hinzufügen. Sie können einen Dateipfad im Arbeitsbereich (beginnend mit /Workspace/), einen Unity Catalog-Volumepfad (beginnend mit /Volumes/) oder einen Verweis auf eine Anforderungsdatei (zum Beispiel -r /Workspace/path/to/requirements.txt) angeben.
Dbt-Aufgaben
DBT-Aufgaben verwenden eine Umgebung auf Auftragsebene für die Bibliothekskonfiguration.

So konfigurieren Sie eine Umgebung auf Auftragsebene:
- Klicken Sie in der Aufgabenkonfiguration auf das Dropdownmenü "Umgebung und Bibliotheken ".
- Klicken Sie in der Auftragsumgebung auf das Stiftsymbol neben einer vorhandenen Umgebung, oder klicken Sie auf +Neue Auftragsumgebung hinzufügen.
- Wählen Sie im Dialogfeld " Umgebung konfigurieren " im Dropdownmenü " Basisumgebung " folgendes aus:
- Databricks-Umgebungen: Azure Databricks bereitgestellte Optionen wie Standard und ML.
- Arbeitsbereichsumgebungen: Benutzerdefinierte Umgebungen, die von Ihrem Arbeitsbereichsadministrator konfiguriert wurden. Siehe Verwalten von Arbeitsbereichsbasisumgebungen.
- Mehr: Frühere Versionen und Benutzerdefiniert (geben Sie eine YAML-Datei an).
- Fügen Sie unter Abhängigkeiten alle zusätzlichen Bibliotheken hinzu. Sie können eine Bibliothek in einem beliebigen Format angeben, das in einer requirements.txt-Datei gültig ist, oder einen absoluten Pfad zu einer Arbeitsbereichsdatei oder einem Unity Catalog-Volume verwenden.
- Klicken Sie auf Bestätigen.
Note
Wenn in Ihrem Arbeitsbereich die Arbeitsbereichsbasisumgebung für die Vorschau von Aufträgen nicht aktiviert ist, wird im Dialogfeld "Umgebung konfigurieren" anstelle der Basisumgebung eine Dropdownliste "Umgebungsversion" angezeigt.
Um die Umgebung zu konfigurieren, wählen Sie eine Version aus, und klicken Sie dann auf +Bibliothek hinzufügen. Sie können einen Dateipfad im Arbeitsbereich (beginnend mit /Workspace/), einen Unity Catalog-Volumepfad (beginnend mit /Volumes/) oder einen Verweis auf eine Anforderungsdatei (zum Beispiel -r /Workspace/path/to/requirements.txt) angeben.
JAR-Aufgaben
Arbeitsbereichsbasisumgebungen werden für JAR-Aufgaben nicht unterstützt. So konfigurieren Sie die Umgebung für eine JAR-Aufgabe:

- Klicken Sie in der Aufgabenkonfiguration unter "Umgebung und Bibliotheken" auf +JAR-Abhängigkeit hinzufügen.
- Im Dialogfeld "Umgebung konfigurieren ":
- Geben Sie optional einen Pfad zu einer YAML-Datei im Feld "Basisumgebung " ein.
- Wählen Sie im Dropdownmenü " Umgebungsversion " eine Umgebungsversion aus.
- Fügen Sie unter JAR-Abhängigkeiten die Pfade zu Ihren JAR-Dateien hinzu.
- Klicken Sie auf Bestätigen.
Informationen zum Erstellen einer benutzerdefinierten YAML-basierten Basisumgebung finden Sie unter Erstellen einer benutzerdefinierten Umgebungsspezifikation.
Umgebungs- und Rechenkompatibilität
Die ausgewählte Basisumgebung muss mit dem Computetyp der Aufgabe kompatibel sein. Beispielsweise ist eine für GPU-Compute integrierte Umgebung nicht mit der CPU-Berechnung kompatibel. In der Job-Benutzeroberfläche sind inkompatible Umgebungen im Dropdown-Menü für die Basisumgebung nicht verfügbar.
Wenn Sie eine Notizbuchaufgabe konfigurieren, kann der Computetyp (CPU oder GPU) und die Basisumgebung jeweils aus den Auftragseinstellungen oder den Notizbucheinstellungen stammen.
- Wenn Sie einen Hardwarebeschleuniger (GPU) auf Auftragsebene festlegen, müssen Sie auch eine Basisumgebung auf Auftragsebene auswählen. Sie können die Umgebung des Notebooks nicht mit einem jobbezogenen Beschleuniger verwenden.
- Wenn Sie Aufgaben haben, die auf ein Notizbuch verweisen und den Computetyp des referenzierten Notizbuchs aktualisieren (z. B. von CPU zu GPU), können vorhandene Aufgaben mit ihrer konfigurierten Umgebung inkompatibel werden. Überprüfen Sie die Umgebungseinstellungen Ihres Auftrags, nachdem Sie die Rechenkonfiguration des Notebooks geändert haben.
- Für API-Benutzer: Wenn Sie die Basisumgebung auf Auftragsebene festlegen, aber das Notizbuch den Berechnungstyp definiert, Azure Databricks die Kompatibilität zur Laufzeit überprüft, nicht zum Zeitpunkt der Auftragserstellung. Wenn die Konfiguration nicht kompatibel ist, schlägt die Ausführung mit einem Fehler fehl.