Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Datenflussdiagramme bieten Ihnen eine flexible Möglichkeit, Daten zu verarbeiten, während sie sich durch Azure IoT Einsatz bewegt. Ein Standarddatenfluss folgt einer festen Anreicherung, Filter- und Kartensequenz. Mit einem Datenflussdiagramm können Sie Transformationen in beliebiger Reihenfolge erstellen, in parallele Pfade verzweigen und Daten über Zeitfenster aggregieren.
Ein Datenflussdiagramm wird von der DataflowGraph benutzerdefinierten Kubernetes-Ressource definiert. Darin verbinden Sie Quellen, Transformationen und Ziele zusammen, um Verarbeitungspipelines zu erstellen, die Ihrem Szenario entsprechen.
Von Bedeutung
Datenflussdiagramme unterstützen derzeit nur MQTT-, Kafka- und OpenTelemetry-Endpunkte. Andere Endpunkttypen wie Data Lake, Microsoft Fabric OneLake, Azure Data Explorer und lokaler Speicher werden nicht unterstützt. Weitere Informationen finden Sie unter Bekannte Probleme.
Datenflüsse im Vergleich zu Datenflussdiagrammen
Azure IoT Einsatz bietet zwei Möglichkeiten zum Verarbeiten von Daten in einer Pipeline:
| Fähigkeit | Datenflüsse | Datenflussdiagramme |
|---|---|---|
| Pipeline-Form | Behoben: Anreicherung, Filter, Karte | Flexibel: beliebige Reihenfolge, Verzweigung, Zusammenführung |
| Transformationstypen | Karte, Filter, Anreicherung | Abbildung, Filter, Verzweigen, Verketten, Fenster, Anreicherung |
| Zeitbasierte Aggregation | Nicht verfügbar | Fenstertransformationen mit gleitenden Fenstern |
| Bedingtes Routing | Nicht verfügbar | Verzweigung und Verketten von Transformationen |
| Endpunktunterstützung | Alle Endpunkttypen | NUR MQTT, Kafka und OpenTelemetry |
Für neue Projekte, die unterstützte Endpunkttypen verwenden, empfehlen wir Datenflussdiagramme. Datenflüsse werden für alle Szenarien vollständig unterstützt, und sie unterstützen die gesamte Bandbreite von Endpunkttypen.
Verfügbare Transformationen
Jede Transformation ist ein vordefinierter Verarbeitungsschritt, den Sie mit Regeln und Kette mit anderen Transformationen innerhalb einer DataflowGraph Ressource konfigurieren.
| Umwandeln | Artefakt | Description |
|---|---|---|
| Landkarte | azureiotoperations/graph-dataflow-map:1.0.0 |
Umbenennen, Neustrukturieren, Berechnen und Kopieren von Feldern. |
| Filter | azureiotoperations/graph-dataflow-filter:1.0.0 |
Verwerfen Sie Nachrichten, die einer Bedingung entsprechen. |
| Filiale | azureiotoperations/graph-dataflow-branch:1.0.0 |
Leiten Sie jede Nachricht basierend auf einer Bedingung an einen true- oder false-Pfad weiter. |
| Concatenate | azureiotoperations/graph-dataflow-concatenate:1.0.0 |
Führen Sie zwei oder mehr Pfade wieder in einem Pfad zusammen. |
| Fenster | azureiotoperations/graph-dataflow-window:1.0.0 |
Sammeln Sie Nachrichten über ein Zeitintervall, und aggregieren Sie dann. |
Alle Transformationen teilen eine Ausdruckssprache für Operatoren, Funktionen und Feldverweise. Sie können Nachrichten auch mit externen Daten aus einem Zustandsspeicher in Karten-, Filter- und Verzweigungstransformationen anreichern .
Wie sich Transformationen zusammensetzen
Transformationen verbinden sich in Sequenz innerhalb einer DataflowGraph Ressource: Quelle > Transformation A > Transformation B > ... > Ziel.
Verzweigungstransformationen teilen den Fluss in parallele Pfade auf und Zusammenführungstransformationen fügen sie wieder zusammen.
Sie können eine beliebige Anzahl von Transformationen in beliebiger Reihenfolge verketten. Eine Pipeline mit einer einzigen Map-Transformation ist genauso gültig wie eine, die filtert, verzweigt, jeden Pfad unterschiedlich abbildet, zusammenführt und dann über ein Zeitfenster aggregiert.
Funktionsweise der Konfiguration
Jede Transformation in einem Datenflussdiagramm verweist auf ein vordefiniertes Artefakt, das aus einer Containerregistrierung abgerufen wird. Sie konfigurieren die Transformation, indem Sie Regeln als JSON über den configuration Abschnitt der Graph-Ressource übergeben.
Ein Standard-Registrierungsendpunkt namens default, der auf mcr.microsoft.com zeigt, wird automatisch erstellt, wenn Sie Azure IoT Einsatz bereitgestellt haben. Die integrierten Transformationen verwenden diesen Endpunkt, um Artefakte aus der Microsoft Container-Registrierung abzurufen. Es ist kein zusätzliches Registrierungssetup erforderlich.
Hier ist ein vollständiges Beispiel, das Temperaturdaten aus einem MQTT-Thema liest, Celsius mit einer Kartentransformation in Fahrenheit konvertiert und das Ergebnis veröffentlicht:
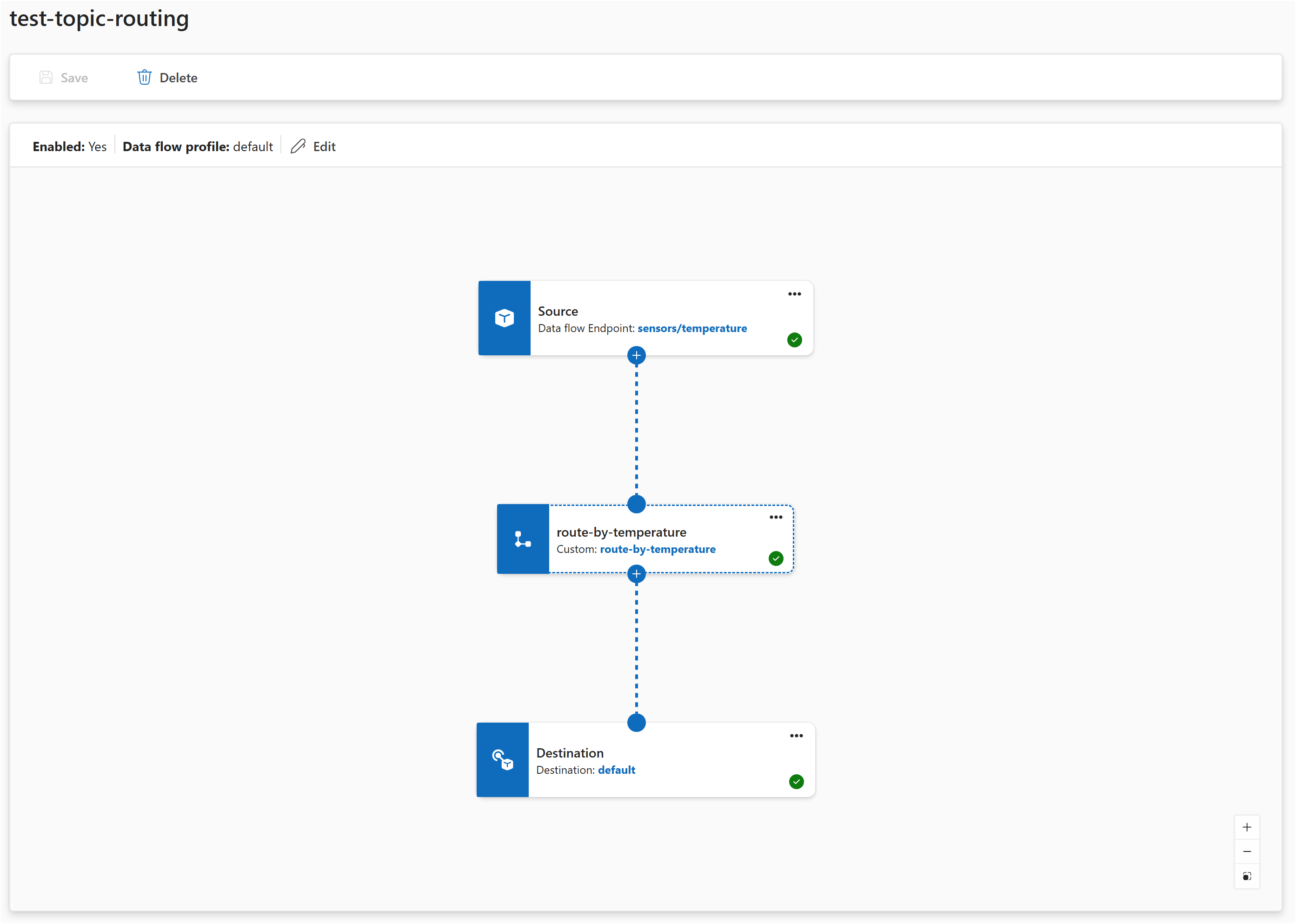
In der Betriebsumgebung:
- Wählen Sie "Datenflussdiagramm>erstellen" aus.
- Fügen Sie eine Quelle mit dem Standardendpunkt und Thema
telemetry/temperaturehinzu. - Fügen Sie eine Kartentransformation hinzu. Konfigurieren sie eine Regel mit Eingabe
temperature, Ausgabetemperature_fund AusdruckcToF($1). - Fügen Sie ein Ziel mit dem Standardendpunkt und Thema
telemetry/convertedhinzu. - Verbinden: Quelle → Karte → Ziel.
- Wählen Sie Speichern aus.
Die Pipeline definiert drei Elemente: eine Quelle, eine Transformation (angegeben durch nodeType: Graph) und ein Ziel. Die Verbindungen beschreiben, wie Daten zwischen ihnen fließen. Die Regeln der configuration Transformation werden als JSON-Zeichenfolge unter dem rules Schlüssel übergeben.
In den folgenden Anleitungsartikeln konzentrieren sich Beispiele auf die Transformationsregeln selbst. Eine schrittweise Anleitung zum Erstellen eines Datenflussdiagramms finden Sie unter Erstellen eines Datenflussdiagramms.
Integrierte Transformationen im Vergleich zu WASM-Transformationen
Datenflussdiagramme unterstützen zwei Arten von Transformationen:
- Integrierte Transformationen sind von Microsoft vordefiniert (Zuordnung, Filter, Verzweigung, Verkettung, Fenster). Sie konfigurieren sie mit Regeln. Keine Codierung erforderlich.
- WASM-Transformationen sind benutzerdefinierte WebAssembly-Module, die Entwickler erstellen und bereitstellen. Verwenden Sie sie, wenn Sie Logik benötigen, die von den integrierten Transformationen nicht abgedeckt wird.
Beide Arten von Transformationen werden innerhalb derselben DataflowGraph Ressource ausgeführt und können in einer einzigen Pipeline gemischt werden. Informationen zum Erstellen und Bereitstellen von benutzerdefinierten Transformationen finden Sie unter Verwenden von WASM-Transformationen in Datenflussdiagrammen.
Fehlerbehandlung
Wenn bei der Verarbeitung einer Nachricht ein Fehler auftritt (z. B. ein fehlendes Feld oder ein ungültiger Ausdruck), wird die Nachricht gelöscht und ein Fehler protokolliert. Die Pipeline verarbeitet weiterhin nachfolgende Nachrichten.
Häufige Ursachen von Verarbeitungsfehlern:
- In der Nachricht ist kein Feld vorhanden, auf das in einer Regel
inputsverwiesen wird. - Ein Filter- oder Verzweigungsausdruck gibt einen nicht booleschen Wert zurück.
- Ein Ausdruck verweist auf einen inkompatiblen Datentyp (z. B. die Verwendung eines JSON-Objekts in arithmetischer Form).
- Ein Zustandsspeicher, der für die Anreicherung verwendet wird, ist nicht erreichbar.
Um Verarbeitungsfehler zu überwachen, überprüfen Sie die Pod-Protokolle auf den Datenflussgraphen oder verwenden Sie die Metrik-Endpunkte. Weitere Informationen finden Sie unter Configure observability and monitoring.
Skalierungsbeschränkung für zustandsbehaftete Diagramme
Datenflussdiagramme, die zustandsbehaftete Transformationen enthalten, z. B. Fenster, müssen mit einer Anzahl von Datenflussprofilinstanzen von 1 ausgeführt werden. Wenn die Anzahl der Instanzen größer als eins ist, werden eingehende Nachrichten über freigegebene Abonnements über Instanzen verteilt. Da jede Instanz ihren eigenen Aggregationsstatus verwaltet und die Instanzen nicht miteinander kommunizieren, sieht jede Instanz nur einen Bruchteil der Nachrichten. Dies führt dazu, dass Aggregationsergebnisse wie Mittelwerte, Summen und Zählungen über unvollständige Daten berechnet werden.
Zustandslose Datenflussdiagramme (die nur Zuordnungs-, Filter-, Verzweigungs- und Verkettentransformationen verwenden) können sicher höhere Instanzenanzahlen verwenden, um den Durchsatz zu erhöhen.
Leistungsleitfaden
Jede Transformation in der Pipeline erhöht den Verarbeitungsaufwand. Beachten Sie die folgenden Richtlinien:
- Bevorzugen Sie weniger Transformationen mit mehr Regeln. Wenn Sie über viele Transformationsregeln verfügen, die mit derselben Struktur arbeiten, sollten Sie sie in einer einzelnen Map-Transformation zusammenfassen, anstatt separate Transformationen für jede Regel zu erstellen.
- Verwenden Sie mehrere Transformationen, wenn die Logik voneinander getrennt ist. Separate Transformationen sind sinnvoll, wenn unterschiedliche Verarbeitungsschritte grundsätzlich unterschiedlich sind (Filterung und Zuordnung im Vergleich zur Aggregierung).
- Halten Sie verwandte Regeln zusammen. Eine einzelne Transformation kann gleichzeitig Feldumbenennungen, Umstrukturierungen, berechnete Felder und Metadatentransformationen verarbeiten.
Nächste Schritte
- Datenflüsse im Vergleich zu Datenflussdiagrammen
- Erstellen eines Datenflussdiagramms
- Transformieren von Daten mit Karte
- Filtern und Weiterleiten von Daten
- Aggregieren von Daten im Laufe der Zeit
- Anreichern mit externen Daten
- Ausdrucksreferenz
- Weiterleiten von Nachrichten an verschiedene Themen
- Ausdrucksreferenz
- Verwenden von WASM-Transformationen in Datenflussdiagrammen